 |
VOOZH | about |
|
VOOZH | about |
On June 2, 2026, at its Build developer conference, Microsoft announced a family of seven in-house AI models under the MAI brand, the most concrete step yet in the company’s plan to stop being just the best distributor of someone else’s frontier models. The lineup spans reasoning, coding, image generation, voice, and transcription, and it was unveiled during CEO Satya Nadella’s keynote alongside new agents, silicon, and a repositioning of Windows itself.
The centerpiece is MAI-Thinking-1, Microsoft’s first reasoning model. It is a 35 billion active parameter Mixture of Experts model that Microsoft says matches Claude Opus 4.6 on SWE-Bench Pro and narrowly beat Claude Sonnet 4.6 in blind human evaluations. The full benchmark picture is more modest than the headline (it trails the true coding frontier on most tests, as we break down below), but what makes the release notable is not just the scores. Microsoft trained the entire family from scratch on clean, commercially licensed data, with zero distillation from third party models, a direct shot at the way most labs bootstrap their models today.
Seven new models launching at Build: let’s go!
— Microsoft AI (@MicrosoftAI) June 2, 2026
Reasoning. Code. Image. Transcribe. Voice.
Built from scratch on a clean data lineage, designed for efficiency, working seamlessly as a family of models
Thread 🧵 #MSBuild pic.twitter.com/g3WQIcIQ24
In this article we walk through all seven models, the real benchmarks, the training philosophy Microsoft calls the Hill-Climbing Machine, the Maia 200 silicon co-design, pricing and availability, the strategic shift away from OpenAI dependence, and how MAI-Thinking-1 stacks up against the models Microsoft chose (Claude Opus 4.6, GPT-5.4) and against today’s actual leaders (Claude Opus 4.8 and GPT-5.5).
Microsoft used the Build 2026 keynote to unveil seven new models built by its MAI team (Microsoft AI Superintelligence). The full lineup is:
The framing was unusually direct. Microsoft positioned the whole effort under what it calls Humanist Superintelligence, advanced AI built to serve people and organizations rather than replace them. But the practical message to developers was simpler. Microsoft now wants to be seen as a model maker, a runtime owner, and a silicon vendor, not just the place where you rent OpenAI’s models.
Around the models, Microsoft also announced Microsoft Scout, a proactive personal agent that handles scheduling and meeting prep through Teams and Outlook, a Surface RTX Spark Dev Box capable of running models up to 120 billion parameters locally, the general availability of Microsoft Discovery for scientific research, and a new Windows sandboxing system called Microsoft Execution Containers that repositions the OS as an agent native runtime.
MAI-Thinking-1 is a sparse Mixture of Experts model with 35 billion active parameters and roughly 1 trillion total parameters. The base model, called MAI-Base-1, was pre-trained from scratch on 8,000 NVIDIA GB200 GPUs on a Microsoft-operated Azure cluster, using 30 trillion tokens of main pre-training followed by 3.55 trillion tokens of mid-training. Architecturally it is a decoder-only Transformer with Gemma-3-style attention (five local layers per global layer, 512 sliding window), grouped-query attention with 8 KV heads, and a LatentMoE design that activates 8 of 512 experts per token. It uses the o200k_base tokenizer with a roughly 200K vocabulary. The smaller inference footprint is the entire point: Microsoft built it for efficiency and low token cost so strong reasoning can move from occasional heavy tasks into everyday workflows.
The model ships with a 256K token context window, enough to fit roughly a 600 page document, according to Microsoft’s own technical report. Some early press coverage reported a 128K window, so expect the official 256K figure to be the one that sticks as documentation settles. It supports function calling, developer instructions, and multiple layers of instruction following, and it is compatible with the widely used Chat Completions API.
On training data, the report says MAI-Base-1 was pre-trained on a mixture of publicly available and licensed human-generated data covering web text, public GitHub code, books, academic papers, news, multilingual text, and domain-specific material. Microsoft says it chose not to use any synthetic data generated by language models, made an effort to remove AI-generated content from collected sources, and decontaminated common machine learning benchmarks from the training data.
Microsoft describes the target use cases plainly. MAI-Thinking-1 was designed to be good at complex multi-step instructions, long context reasoning, and code generation. It comes with enterprise grade security and compliance through Microsoft Foundry, and its default style was tuned toward enterprise needs rather than consumer chat.
The most interesting part of the release is not the model, it is the system Microsoft built to produce it. The company calls it the Hill-Climbing Machine, a co-designed pipeline meant to make every component of model development improvable over time, so capabilities climb continually as better data, rewards, environments, and compute are added.
Three principles guide it.
Capabilities should be learned, not inherited. This is the headline philosophical claim. Microsoft trained MAI-Thinking-1 without distillation from any third party model. The argument is that an imitator is permanently tied to the design choices of its teacher and struggles to adapt to new situations, while a model that learns tasks directly is more steerable. Most labs quietly bootstrap new models from outputs of existing strong models. Microsoft is explicitly refusing to.
Clean data. The model was trained on appropriately licensed data, and Microsoft says AI-generated content was excluded from pre-training entirely. The pitch here is provenance and control. If you cannot account for what shaped a model, you cannot fully understand its behavior. For enterprises worried about data lineage and legal exposure, this is the part that matters most.
Self-sufficiency across the stack. From co-designing the models with Microsoft’s own accelerators all the way through to its in-house reinforcement learning framework, Microsoft built the training infrastructure itself. The goal is to control and optimize the whole system end to end.
To train agentic coding, Microsoft built verified environments that are deterministic, executable, and graded by real test suites. That gives the model practice on the work developers actually do, reading code, editing files, running tests, watching failures, and recovering from mistakes mid task.
Microsoft published a full comparison table in its technical report, and the real numbers are more nuanced than the keynote framing. Here is Table 11 from the report, covering STEM and agentic coding, with every competitor figure Microsoft listed (these are drawn from each model’s official cards, and dashes mean a model did not report that benchmark).
| Benchmark | MAI-Thinking-1 | Sonnet 4.6 | Opus 4.6 | GPT-5.4 | Kimi K2.6 | DeepSeek V3.2 | DeepSeek V4 | GLM-5.1 |
|---|---|---|---|---|---|---|---|---|
| AIME 2025 | 97.0 | 95.6 | 99.8 | — | — | 93.1 | — | — |
| AIME 2026 | 94.5 | — | — | — | 96.4 | — | — | 95.3 |
| HMMT Feb 2026 | 84.9 | — | — | — | 92.7 | — | 95.2 | 82.6 |
| GPQA Diamond | 84.2 | 89.9 | 91.3 | 92.8 | 90.5 | 82.4 | 90.1 | 86.2 |
| LiveCodeBench v6 | 87.7 | — | — | — | 89.6 | 83.3 | 93.5 | — |
| Terminal-Bench 2.0 | 46.0 | 59.1 | 65.4 | 75.1 | 66.7 | 46.4 | 67.9 | 69.0 |
| SWE-bench Verified | 73.5 | 79.6 | 80.8 | — | 80.2 | 73.1 | 80.6 | — |
| SWE-Bench Pro | 52.8 | — | 53.4 | 57.7 | 58.6 | — | 55.4 | 58.4 |
A few honest takeaways. The famous “toe-to-toe with Claude Opus 4.6 on SWE-Bench Pro” line is technically accurate, 52.8 versus 53.4, but it is the one comparison that flatters MAI-Thinking-1 most. On that same benchmark, GPT-5.4 (57.7), Kimi K2.6 (58.6), DeepSeek V4 (55.4), and GLM-5.1 (58.4) all beat both Microsoft and Anthropic. On SWE-bench Verified and Terminal-Bench 2.0, MAI-Thinking-1 sits near the bottom of the frontier pack (73.5 and 46.0), well behind Opus 4.6, GPT-5.4, and the Chinese open models. Microsoft itself concedes in the report that the model “does not lead the field” and notes its weak Terminal-Bench number reflects that it was not trained on terminal-interaction environments. Among those Chinese open models, Nex-N2-Pro posts a far stronger 80.8 on SWE-bench Verified.
Where MAI-Thinking-1 genuinely shines is math. It hits 97.0 on AIME 2025, beating Sonnet 4.6 (95.6) and trailing only Opus 4.6 (99.8), and posts 94.5 on AIME 2026 and 87.7 on LiveCodeBench v6. For a 35B active model trained from scratch with no distillation and no benchmark targeting, that is a real result and the strongest evidence that the Hill-Climbing Machine produces genuine reasoning gains rather than memorized patterns. GPQA Diamond (84.2) is the soft spot, lowest of the closed frontier models on the list.
On general capabilities, Microsoft only benchmarked against Sonnet 4.6 (Table 12), and the two trade blows. MAI-Thinking-1 leads on IFBench instruction following (69 vs 50) and SimpleQA (31 vs 29), but trails on MMLU-Pro (85 vs 87), tool calling via BFCL v3 (72 vs 76), long context GraphWalks (90 vs 96), and health knowledge (MedXpert 43 vs 49). They are effectively tied on safety and honesty.
The human evaluation is the most important correction to the marketing. Microsoft ran a blind side-by-side study through Surge AI across 1,276 English tasks (30% multi-turn). Against Sonnet 4.6, MAI-Thinking-1 won 49% of comparisons, tied 6%, and lost 45%, a narrow edge driven mostly by conciseness and style rather than correctness. But against Opus 4.6, MAI-Thinking-1 lost, winning 43%, tying 5%, and losing 52%. So the accurate one-line summary is that MAI-Thinking-1 is roughly Sonnet-4.6 class on overall helpfulness, not Opus class, and is a notch behind the true coding frontier. As with all vendor-run evaluations, these are Microsoft grading its own model, and no independent third-party benchmarks existed at launch.
The second model built for developers is MAI-Code-1-Flash, a small coding model tuned specifically for VS Code and GitHub Copilot CLI. It is tiny by frontier standards at around 5 billion parameters, closer to Claude Haiku in size, but Microsoft says it is cheaper to run and delivers strong coding performance.
Microsoft published a direct comparison against Claude Haiku 4.5, and MAI-Code-1-Flash wins on every coding benchmark they tested:
| Benchmark | MAI-Code-1-Flash | Claude Haiku 4.5 |
|---|---|---|
| SWE-Bench Verified | 71.6 | 66.6 |
| SWE-Bench Pro | 51.2 | 35.2 |
| Terminal Bench 2 | 54.8 | 41.6 |
It does this while using up to 60% fewer tokens, which is the real selling point. For a model that runs inside an editor on every keystroke and command, token efficiency directly determines cost and latency. MAI-Code-1-Flash is rolling out today as one of the default models in VS Code, and it was trained on production Copilot harnesses and licensed data.
The fact that a 5B model can post a 51.2 on SWE-Bench Pro, within striking distance of MAI-Thinking-1’s 53, is the more telling story. It points to how much of coding performance now comes from training environment quality rather than raw parameter count.
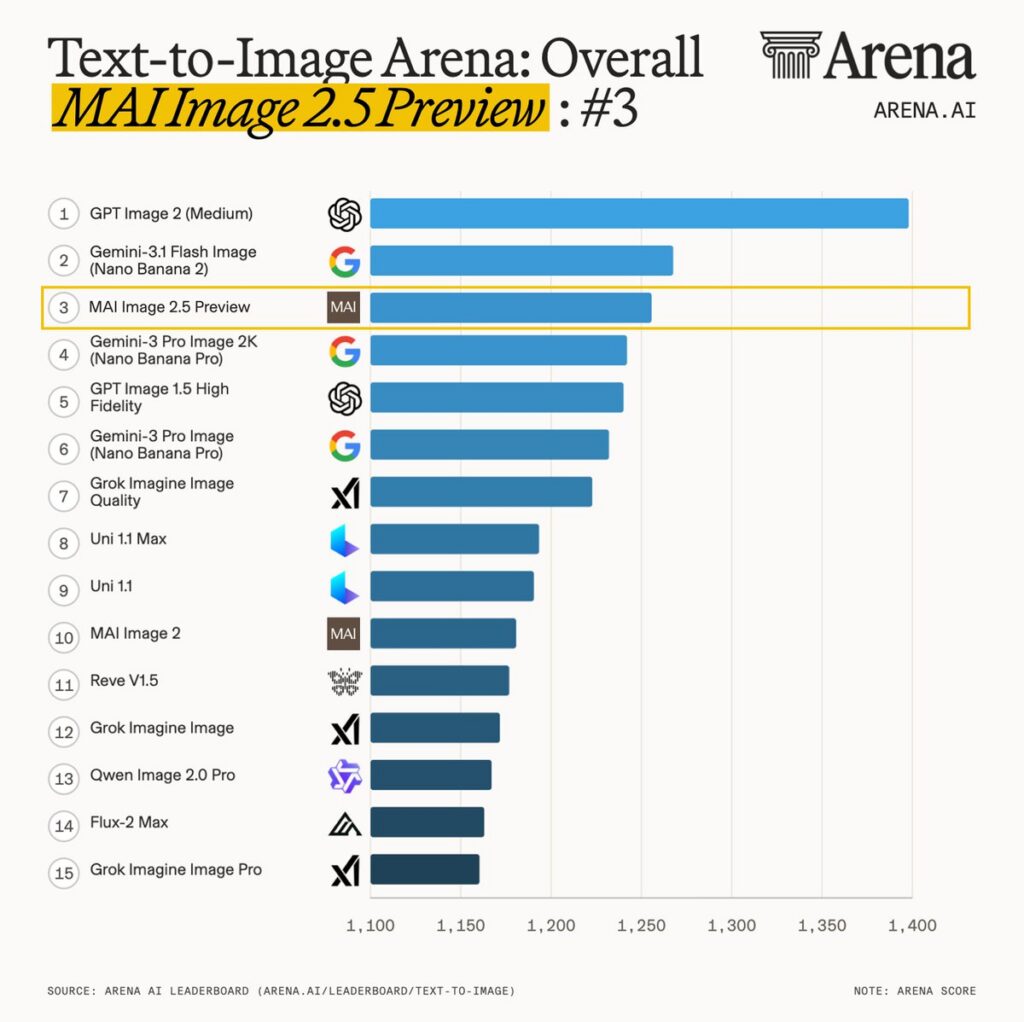
On the image side, Microsoft launched MAI-Image-2.5 and a faster MAI-Image-2.5 Flash variant. The models debuted at number 2 on Arena’s image-editing leaderboard, ahead of Google’s Nano Banana 2.1, and number 3 on the text-to-image leaderboard, roughly on par with Nano Banana 2. They emphasize precision editing with control and consistency, including a suite of control-with-preservation capabilities for image-to-image work.
The split between the two is about workload. Flash targets super efficient production workloads at scale, while the full 2.5 model is for maximum fidelity and professional grade output. Both are already live in PowerPoint, rolling out to OneDrive, and landing on Foundry with what Microsoft frames as market leading quality per dollar.
MAI-Transcribe-1.5 is Microsoft’s updated speech-to-text model, and the company is making a bold claim, that it is the best transcription model in the world, with state of the art accuracy across 43 languages and beating Gemini and OpenAI models. It is optimized for real world use and runs up to five times faster than rival models. Microsoft is integrating it into Copilot, Teams, GitHub, and Dynamics 365 Contact Center, with streaming support coming soon, and it is available in Foundry as what Microsoft calls the fastest and most cost-effective transcription model of any hyperscaler.
Microsoft has released MAI-Transcribe-1.5: an exceptionally fast speech transcription model at a speed factor of ~276x, while still achieving 2.4% on AA-WER (#3), leading the accuracy-speed Pareto frontier
— Artificial Analysis (@ArtificialAnlys) June 2, 2026
MAI-Transcribe-1.5 is Microsoft AI (MAI)’s latest speech transcription… pic.twitter.com/63lx80W4pa
MAI-Voice-2 is the matching speech generation model, with native sounding delivery, fine grained emotional control, and support for 15 languages with more coming. A Voice-2-Flash variant targets ultra latency sensitive voice agents, which Microsoft is betting will be the big application category of 2026.
On safety, the voice models include protections against unauthorized cloning, and all outputs are watermarked. Microsoft also says it reduced over-refusals across the family and improved representation, including for people with disabilities.
One of Microsoft’s strongest structural advantages is that it builds its own chips, and the MAI launch leaned into it. Microsoft co-designed MAI-Thinking-1 with its Maia 200 accelerator and benchmarked it head-to-head against NVIDIA’s GB200.
The numbers Microsoft cited are about efficiency, not raw speed. On top of a 30% improvement Nadella referenced earlier in the keynote, Microsoft says it sees a further 1.4x performance-per-watt gain running MAI models on Maia 200 end to end. At data center scale, where every watt is a cost and a constraint, that kind of model-plus-silicon co-design is a genuine moat. The faster, more efficient MAI models are also coming to the N1X chip for Windows devices.
This is the part competitors cannot easily copy. Anthropic, OpenAI, and Google can tune models, but Microsoft tuning a model against silicon it designed itself is a different category of optimization. The open-weight race is heating up alongside it; on June 4, NVIDIA released Nemotron 3 Ultra, the most capable open US model.
The strategic subtext is not subtle. Microsoft has been the primary commercial channel for OpenAI’s models for years, and this launch is the clearest signal yet that it no longer wants to depend on a single partner for frontier intelligence.
The motivation is partly cost. As the price of the most advanced models keeps climbing, Microsoft can run its own models on its own Azure infrastructure and pass savings to developers, avoiding payments to third parties. Kyle Daigle, Microsoft’s developer marketing chief and GitHub COO, described MAI-Thinking-1 as built for high efficiency and performance at a low token cost, framing it explicitly as a way for developers to lower their AI spend.
It is also about control and trust. The clean data lineage and no-distillation approach are designed to give enterprises a model they can put into production with confidence about where its capabilities came from. For regulated industries, provenance is not a nice-to-have.
Notably, Microsoft is not locking these models to Azure. MAI models are being distributed through OpenRouter, Fireworks, and Baseten in addition to Foundry, and for the first time developers will be able to tune the weights directly themselves. That positions MAI as an industry platform play rather than a pure cloud lock-in, which is a more aggressive competitive stance than simply keeping the models in-house.
The piece Microsoft is most excited about long term is customization. The company introduced Microsoft Frontier Tuning, built on reinforcement learning environments it calls RLEs, task specific training gyms that let companies adapt MAI models to their own workflows.
The examples were concrete. Internally, Microsoft used RLEs to tune a MAI model for agentic Excel tasks, reaching parity with GPT-5.4 on public and private benchmarks while being up to 10x more efficient. When it tuned models for McKinsey’s tasks, Microsoft says MAI delivered the highest win rate, outperforming GPT-5.5 on quality while being 10x lower on cost.
The pitch to enterprises is ownership. Unlike renting intelligence from a shared model that learns from everyone, a company that tunes a MAI model inside its own RLE keeps the benefits of its workflows and data, and controls the resulting model. Microsoft is arguing that these custom models become a company’s competitive moat. It also announced a partnership with Mayo Clinic to jointly develop and deploy a frontier health model inside Mayo’s hospital system, the highest-stakes example of this co-creation approach.
Availability is staggered across the family:
Microsoft has not published per-token API pricing at launch. The repeated emphasis on low token cost, quality per dollar, and being the most cost-effective option among hyperscalers signals that aggressive pricing is the intended differentiator, but exact numbers will appear as the Foundry, OpenRouter, Fireworks, and Baseten listings go live. Microsoft also published a detailed technical report alongside the release for transparency on how the models were built.
MAI-Thinking-1 is a reasoning model in the same arena as Claude Opus 4.6, Claude Sonnet 4.6, and GPT-5.4, but it is competing on a different axis. It is smaller, cheaper to run, and built around efficiency rather than topping every leaderboard. Here are the head-to-head numbers Microsoft published in its report, against the models it chose to compare with:
| Benchmark | MAI-Thinking-1 | Sonnet 4.6 | Opus 4.6 | GPT-5.4 |
|---|---|---|---|---|
| AIME 2025 (math) | 97.0 | 95.6 | 99.8 | not reported |
| GPQA Diamond (science) | 84.2 | 89.9 | 91.3 | 92.8 |
| SWE-bench Verified | 73.5 | 79.6 | 80.8 | not reported |
| SWE-Bench Pro | 52.8 | not reported | 53.4 | 57.7 |
| Terminal-Bench 2.0 | 46.0 | 59.1 | 65.4 | 75.1 |
| Human preference vs MAI | baseline | MAI wins 49 / loses 45 | MAI wins 43 / loses 52 | not tested |
One catch with that table is that Microsoft benchmarked against Opus 4.6 and GPT-5.4, both of which have already been superseded. The current market leaders as of early June 2026 are Claude Opus 4.8 (released May 28) and GPT-5.5 (released April 23), and the gap to them is wider. Using each vendor’s own published numbers, here is how MAI-Thinking-1 lands against today’s frontier on the benchmarks where the figures line up:
| Benchmark | MAI-Thinking-1 | Claude Opus 4.8 | GPT-5.5 |
|---|---|---|---|
| GPQA Diamond (science) | 84.2 | 93.6 | 93.6 |
| SWE-bench Verified | 73.5 | 88.6 | not reported |
| SWE-Bench Pro | 52.8 | 69.2 | 58.6 |
| Terminal-Bench 2.0 | 46.0 | 74.6 (on v2.1) | 82.7 |
Read these cross-vendor numbers as directional, not exact. Microsoft, Anthropic, and OpenAI each run these benchmarks on their own scaffolds and harnesses, which can move scores by several points, and SWE-Bench Pro in particular is sensitive to the agent setup. Opus 4.8’s Terminal-Bench figure is also on the newer 2.1 version rather than the 2.0 the others report. Even allowing for all of that, the direction is clear: on agentic coding and science, the current leaders are well ahead, with Opus 4.8 at 69.2 on SWE-Bench Pro and GPT-5.5 at 82.7 on Terminal-Bench against MAI-Thinking-1’s 52.8 and 46.0.
On the qualitative dimensions, the trade is different:
| Dimension | MAI-Thinking-1 | Frontier leaders (Opus 4.8 / GPT-5.5) |
|---|---|---|
| Active parameters | 35B (MoE) | undisclosed, larger |
| Context window | 256K | ~200K (Opus), large (GPT) |
| Trained from scratch, no distillation | yes, emphasized | proprietary |
| Clean licensed data lineage | yes, emphasized | not emphasized |
| Token cost focus | core differentiator | premium pricing |
| Silicon co-design | Maia 200 | none disclosed |
| Open weights / self-tuning | yes, planned | no |
The honest read is that MAI-Thinking-1 is not a current-frontier competitor on raw capability. Against the models Microsoft chose, it is roughly Sonnet-4.6 class on overall helpfulness, strong specifically on math, and a step behind on agentic coding and science. Against today’s leaders, Opus 4.8 and GPT-5.5, the capability gap is clearly larger. What MAI-Thinking-1 actually offers is useful-but-not-leading capability in a 35B active model, at low token cost, with a clean data story, running on Microsoft’s own silicon, and eventually with weights you can tune yourself. For production workloads where a full Opus 4.8 or GPT-5.5 would be overkill on price, that combination is the real value proposition, not leaderboard wins. And every MAI number here is vendor-run, so independent third party benchmarks are still the ones worth waiting for.
Three things stand out.
First, Microsoft just declared independence. After years as OpenAI’s primary commercial channel, building a credible in-house reasoning model that lands in the Sonnet-4.6 capability range, from scratch and at low cost, changes the relationship even if it does not top the leaderboards. Microsoft can now route Copilot, GitHub, Office, and Azure workloads to its own models when the economics make sense, which reshapes the bargaining position of every frontier lab that depends on Microsoft distribution.
Second, the no-distillation, clean-data approach is a real bet, not just marketing. Most labs bootstrap from existing models. Microsoft is arguing that learned capabilities are more steerable than inherited ones, and that clean data lineage is worth the extra cost for enterprises. If MAI-Thinking-1’s results hold up under independent testing, it validates the idea that you can climb to frontier-adjacent performance from the ground up, which is a different playbook from the rest of the field.
Third, efficiency is becoming the competitive battleground. A 35B active reasoning model and a 5B coding model that punch above their weight, co-designed with Maia 200 silicon for a 1.4x performance-per-watt gain, signal that the next phase of competition is about cost per useful token, not just peak capability. As advanced model prices climb, the labs that can deliver near-frontier quality cheaply will win the everyday workflows, even if they do not top the leaderboards.
For users who want to compare MAI-Thinking-1 and MAI-Code-1 against Claude Opus 4.6, GPT-5.5, Gemini 3.1 Pro, DeepSeek V4, and Perplexity side by side, Fello AI brings every frontier model into one lightweight native app for Mac, iPhone, and iPad. One place to test the same prompt across models, see which one handles your work best, and switch instantly, instead of paying for a stack of separate subscriptions.
Microsoft says this is a new era of AI you control on your own terms. Whether the MAI family lives up to the benchmarks under independent scrutiny is the open question, but the strategic intent is unmistakable. Microsoft is no longer content to distribute the frontier. It wants to build it.
Stay ahead with expert AI insights trusted by top tech professionals!
Join thousands of AI fans & professionals benefiting from exclusive tips and insights from industry leaders.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}