 |
VOOZH | about |
|
VOOZH | about |
Support both HIP and CUDA® with ease
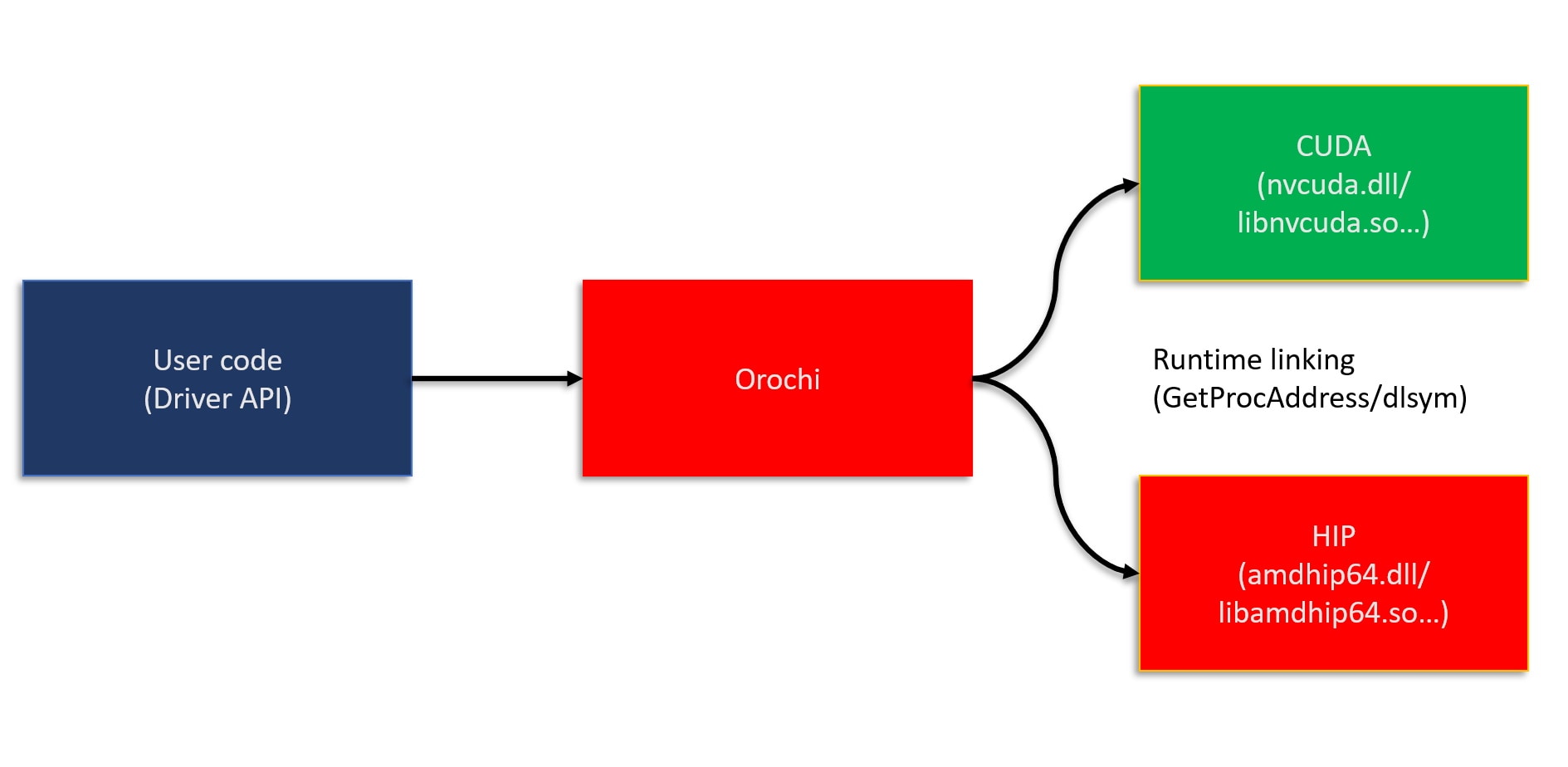
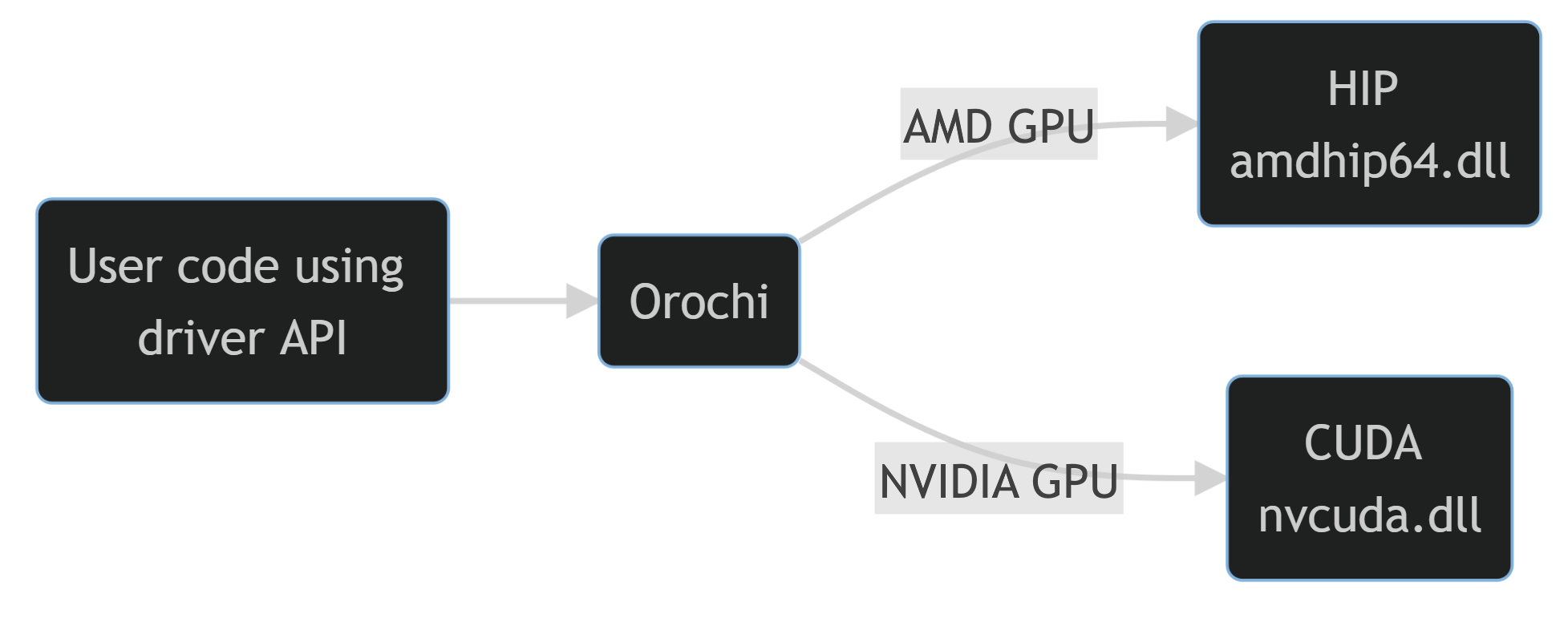
The Orochi library loads HIP and CUDA® APIs dynamically, allowing you to switch between them at runtime. Orochi is named after a legendary Japanese dragon with eight heads and eight tails on a single body. In keeping with its namesake, Orochi enables a single library to use multiple backends at runtime.
This release adds the following features:
release/hip5.7_cuda12.2),release/hip5.7_cuda12.2, install CUDA SDK 12.2.OrochiUtils .Orochi.h can be included in the kernel files to have the oro* names.To run an application compiled with Orochi, you need to install a driver of your choice with the corresponding .dll/.so files based on the GPU(s) available. Orochi will automatically link with the corresponding shared library at runtime.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}