
{kind=link}
{kind=link}
{kind=link}
{kind=link}
13 items • Updated • 62
Salamandra Model Card
This repository contains the model described in Salamandra Technical Report.
Salamandra is a highly multilingual model pre-trained from scratch that comes in three different sizes — 2B, 7B and 40B parameters — with their respective base and instruction-tuned variants. This model card corresponds to the 7B base version.
To visit the model cards of other Salamandra versions, please refer to the Model Index.
The entire Salamandra family is released under a permissive Apache 2.0 license. Along with the open weights, all training scripts and configuration files are made publicly available in this GitHub repository.
Model Details
Description
Transformer-based decoder-only language model that has been pre-trained from scratch on 12.875 trillion tokens of highly curated data. The pre-training corpus contains text in 35 European languages and code.
Hyperparameters
The full list of hyperparameters for each model can be found here.
Architecture
| Total Parameters | 7,768,117,248 |
| Embedding Parameters | 1,048,576,000 |
| Layers | 32 |
| Hidden size | 4,096 |
| Attention heads | 32 |
| Context length | 8,192 |
| Vocabulary size | 256,000 |
| Precision | bfloat16 |
| Embedding type | RoPE |
| Activation Function | SwiGLU |
| Layer normalization | RMS Norm |
| Flash attention | ✅ |
| Grouped Query Attention | ✅ |
| Num. query groups | 8 |
Intended Use
Direct Use
The models are intended for both research and commercial use in any of the languages included in the training data. The base models are intended either for language generation or to be further fine-tuned for specific use-cases. The instruction-tuned variants can be used as general-purpose assistants, as long as the user is fully aware of the model’s limitations.
Out-of-scope Use
The model is not intended for malicious activities, such as harming others or violating human rights. Any downstream application must comply with current laws and regulations. Irresponsible usage in production environments without proper risk assessment and mitigation is also discouraged.
Hardware and Software
Training Framework
Pre-training was conducted using NVIDIA’s NeMo Framework, which leverages PyTorch Lightning for efficient model training in highly distributed settings.
The instruction-tuned versions were produced with FastChat.
Compute Infrastructure
All models were trained on MareNostrum 5, a pre-exascale EuroHPC supercomputer hosted and operated by Barcelona Supercomputing Center.
The accelerated partition is composed of 1,120 nodes with the following specifications:
- 4x Nvidia Hopper GPUs with 64 HBM2 memory
- 2x Intel Sapphire Rapids 8460Y+ at 2.3Ghz and 32c each (64 cores)
- 4x NDR200 (BW per node 800Gb/s)
- 512 GB of Main memory (DDR5)
- 460GB on NVMe storage
| Model | Nodes | GPUs |
|---|---|---|
| 2B | 64 | 256 |
| 7B | 128 | 512 |
| 40B | 256 / 512 | 1,024 / 2,048 |
How to use
This section offers examples of how to perform inference using various methods.
Inference
You'll find different techniques for running inference, including Huggingface's Text Generation Pipeline, multi-GPU configurations, and vLLM for scalable and efficient generation.
Inference with Huggingface's Text Generation Pipeline
The Huggingface Text Generation Pipeline provides a straightforward way to run inference using the Salamandra-7b model.
pip install transformers torch accelerate sentencepiece protobuf
Inference with single / multi GPU
This section provides a simple example of how to run inference using Huggingface's AutoModel class.
pip install transformers torch accelerate sentencepiece protobuf
Inference with vLLM
vLLM is an efficient library for inference that enables faster and more scalable text generation.
pip install vllm
Data
Pretraining Data
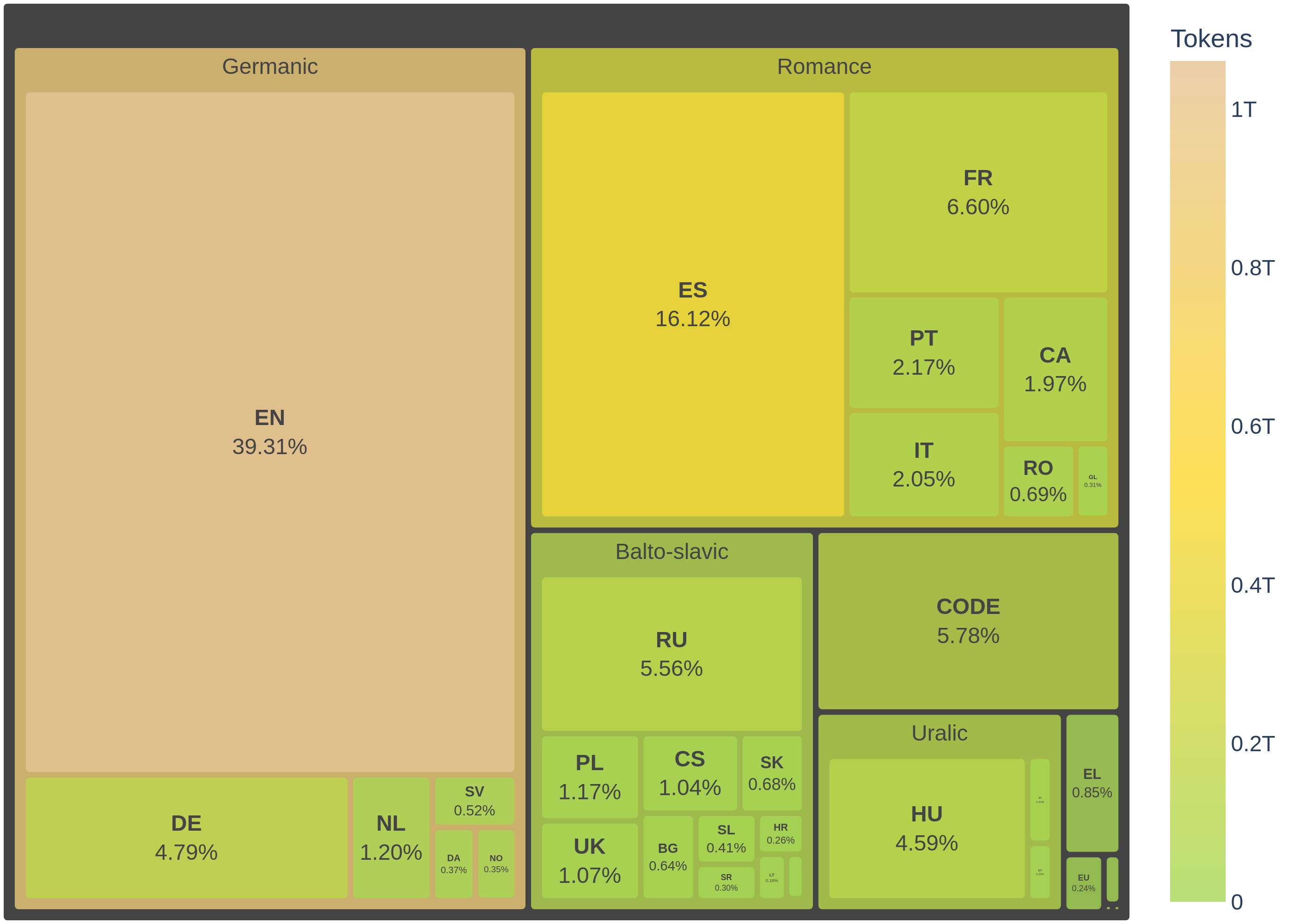
The pre-training corpus comprises data from 35 European languages and 92 programming languages, with detailed data sources provided below. The initial three training epochs used 2.4 trillion tokens, obtained by manually adjusting data proportion to balance the representation and give more importance to Spain’s co-official (Spanish, Catalan, Galician, and Basque). This way, we downsampled code and English data to half, Spanish co-official languages were oversampled by 2x, and the remaining languages were kept in their original proportions. During the following epochs, the Colossal OSCAR dataset was replaced with the FineWeb-Edu dataset. This adjustment resulted in a total of 2.68 trillion tokens, distributed as outlined below:
The pretraining corpus is predominantly composed of data from Colossal OSCAR, which contributes a significant 53.05% of the total tokens. Following this, Starcoder provides 13.67%, and FineWeb-Edu (350BT subset) adds 10.24%. The next largest sources are HPLT at 4.21% and French-PD at 3.59%. Other notable contributions include MaCoCu, Legal-ES, and EurLex, each contributing around 1.72% to 1.41%. These major sources collectively form the bulk of the corpus, ensuring a rich and diverse dataset for training the language model. The remaining 10% comes from smaller sources in various languages.
Feel free to click the expand button below to see the full list of sources.
The model was trained on 3 pre-training epochs with 2.4T tokens per epoch, 2 additional pre-training epochs in which the English part of the Colossal OSCAR dataset was replaced with FineWeb-Edu (350BT subset), resulting in 2.68T tokens per epoch; and 1 final epoch of 0.315T higher quality tokens, meaning that the total number of tokens seen during pre-training is approximately 12.875 trillion tokens.
We provide an extense Datasheet section following the best practices defined by (Gebru et al., 2021).
Evaluation
Gold-standard benchmarks
Evaluation is done using the Language Model Evaluation Harness (Gao et al., 2024). We evaluate on a set of tasks taken from SpanishBench, CatalanBench, BasqueBench and GalicianBench. We also use English tasks already available on the LM Evaluation Harness. These benchmarks include both new and existing tasks and datasets. In the tables below, we include the results in a selection of evaluation datasets that represent model's performance across a variety of tasks within these benchmarks.
We only use tasks that are either human generated, human translated, or with a strong human-in-the-loop (i.e., machine translation followed by professional revision or machine generation followed by human revision and annotation). This is the reason behind the variety in number of tasks reported across languages. As more tasks that fulfill these requirements are published, we will update the presented results. We also intend to expand the evaluation to other languages, as long as the datasets meet our quality standards.
During the implementation of the evaluation we observed a series of issues worth considering when replicating and interpreting the results presented. These issues include ≈1.5% variances in performance in some tasks depending on the version of the transformers library used, and depending on the use (or lack of use) of tensor parallelism when loading a model. When implementing existing tasks, we carry out a comprehensive quality evaluation of the dataset, the Harness task itself, and what kind of input models see during evaluation. Our implementation (see links above) addresses multiple existing problems such as errors in datasets and prompts, and lack of pre-processing. All this means that results will vary if using other Harness implementations, and may slightly vary depending on the replication setup.
It should be noted that these results are subject to all the drawbacks of every current gold-standard evaluation, and that the figures do not fully represent the models capabilities and potential. We thus advise caution when reading and interpreting the results.
A full list of results compared to other baselines, a discussion of the model's performance across tasks and its implications, and details regarding problem-solving with task implementation will soon be available in the technical report.
All results reported below are on a 5-shot setting.
Spanish
| Category | Task | Metric | Result |
|---|---|---|---|
| Commonsense Reasoning | copa_es | acc | 86 |
| xstorycloze_es | acc | 74.32 | |
| NLI | wnli_es | acc | 59.15 |
| xnli_es | acc | 46.59 | |
| Paraphrasing | paws_es | acc | 60.3 |
| QA | openbookqa_es | acc | 41.6 |
| xquad_es | acc | 72.26 | |
| Translation | flores_es | bleu | 23.43 |
Catalan
| Category | Task | Metric | Result |
|---|---|---|---|
| Commonsense Reasoning | copa_ca | acc | 84 |
| xstorycloze_ca | acc | 75.51 | |
| NLI | wnli_ca | acc | 59.15 |
| xnli_ca | acc | 50.16 | |
| Paraphrasing | parafraseja | acc | 65.83 |
| paws_ca | acc | 67.45 | |
| QA | arc_ca_easy | acc | 71.72 |
| arc_ca_challenge | acc | 45.56 | |
| openbookqa_ca | acc | 38.8 | |
| piqa_ca | acc | 71.27 | |
| siqa_ca | acc | 49.85 | |
| Translation | flores_ca | bleu | 30.63 |
Basque
| Category | Task | Metric | Result |
|---|---|---|---|
| Commonsense Reasoning | xcopa_eu | acc | 68.8 |
| xstorycloze_eu | acc | 66.12 | |
| NLI | wnli_eu | acc | 57.75 |
| xnli_eu | acc | 43.51 | |
| QA | eus_exams | acc | 41.04 |
| eus_proficiency | acc | 39.72 | |
| eus_trivia | acc | 52.36 | |
| piqa_eu | acc | 63.67 | |
| Reading Comprehension | eus_reading | acc | 33.52 |
| Translation | flores_eu | bleu | 16.95 |
Galician
| Category | Task | Metric | Result |
|---|---|---|---|
| Commonsense Reasoning | xstorycloze_gl | acc | 74.12 |
| NLI | xnli_gl | acc | 50.95 |
| Paraphrasing | parafrases_gl | acc | 54.42 |
| paws_gl | acc | 63.2 | |
| QA | openbookqa_gl | acc | 34.4 |
| Translation | flores_gl | bleu | 27.75 |
English
| Category | Task | Metric | Result |
|---|---|---|---|
| Commonsense Reasoning | copa | acc | 91 |
| xstorycloze_en | acc | 79.09 | |
| NLI | wnli | acc | 56.34 |
| xnli_en | acc | 50 | |
| Paraphrasing | paws * | acc | 64.05 |
| QA | arc_easy | acc | 82.2 |
| arc_challenge | acc | 52.82 | |
| openbookqa | acc | 36 | |
| piqa | acc | 80.03 | |
| social_iqa | acc | 50.31 | |
| xquad_en ** | acc | 77.74 |
* Current LM Evaluation Harness implementation is lacking correct pre-processing. These results are obtained with adequate pre-processing.
** This task is not yet available in the official Harness, we hope to add it soon.
Ethical Considerations and Limitations
We examine the presence of undesired societal and cognitive biases present in this model using different benchmarks. For societal biases, we test performance using the BBQ dataset (Parrish et al., 2022) in the original English and the Regard dataset (Sheng et al., 2019). We report that while performance is high (accuracies between 0.69 and 0.87 depending on the social category) in disambiguated settings the model performs very poorly in ambiguous settings, which is indicative of the presence of societal biases which need to be addressed in post-training phases.
We additionally analyse model generations using the Regard dataset and classifier in Catalan, Spanish, and English using backtranslation and manual revision of the translations. We find no statistically significant difference in regard between majority and minority groups for any regard types, with the exception of negative regard in Catalan where model generations are actually slightly worse for social majorities. Our analyses on societal biases show that while these biases are capable of interfering with model performance as expressed in the results on the BBQ dataset, their tendency for representational harm is limited given the results of the Regard dataset. We highlight that our analyses of these biases are by no means exhaustive and are limited by the relative scarcity of adequate resources in all languages present in the training data. We aim to gradually extend and expand our analyses in future work.
Our cognitive bias analysis focuses on positional effects in 0-shot settings, and majority class bias in few-shot settings. For positional effects, we leverage the ARC Multiple Choice Question dataset (Clark et al., 2018). We observe moderate to strong primacy effects, whereby the model shows a preference for answers towards the beginning of the list of provided answers. We measure effects of majority class effects in few-shot settings using SST-2 (Socher et al., 2013). We detect moderate effects, implying that outputs can be influenced by the prompts.
We highlight that these results can be expected from a pretrained model that has not yet been instruction-tuned or aligned. These tests are performed in order to show the biases the model may contain. We urge developers to take them into account and perform safety testing and tuning tailored to their specific applications of the model.
Additional information
Author
The Language Technologies Unit from Barcelona Supercomputing Center.
Contact
For further information, please send an email to langtech@bsc.es.
Copyright
Copyright(c) 2024 by Language Technologies Unit, Barcelona Supercomputing Center.
Funding
This work has been promoted and financed by the Government of Catalonia through the Aina Project.
This work is funded by the Ministerio para la Transformación Digital y de la Función Pública - Funded by EU – NextGenerationEU within the framework of ILENIA Project with reference 2022/TL22/00215337.
Acknowledgements
This project has benefited from the contributions of numerous teams and institutions, mainly through data contributions, knowledge transfer or technical support.
In Catalonia, many institutions have been involved in the project. Our thanks to Òmnium Cultural, Parlament de Catalunya, Institut d'Estudis Aranesos, Racó Català, Vilaweb, ACN, Nació Digital, El món and Aquí Berguedà.
At the national level, we are especially grateful to our ILENIA project partners: CENID, HiTZ and CiTIUS for their participation. We also extend our genuine gratitude to the Spanish Senate and Congress, Fundación Dialnet, and the ‘Instituto Universitario de Sistemas Inteligentes y Aplicaciones Numéricas en Ingeniería (SIANI)’ of the University of Las Palmas de Gran Canaria.
At the international level, we thank the Welsh government, DFKI, Occiglot project, especially Malte Ostendorff, and The Common Crawl Foundation, especially Pedro Ortiz, for their collaboration. We would also like to give special thanks to the NVIDIA team, with whom we have met regularly, specially to: Ignacio Sarasua, Adam Henryk Grzywaczewski, Oleg Sudakov, Sergio Perez, Miguel Martinez, Felipes Soares and Meriem Bendris. Their constant support has been especially appreciated throughout the entire process.
Their valuable efforts have been instrumental in the development of this work.
Disclaimer
Be aware that the model may contain biases or other unintended distortions. When third parties deploy systems or provide services based on this model, or use the model themselves, they bear the responsibility for mitigating any associated risks and ensuring compliance with applicable regulations, including those governing the use of Artificial Intelligence.
The Barcelona Supercomputing Center, as the owner and creator of the model, shall not be held liable for any outcomes resulting from third-party use.
Citation
@misc{gonzalezagirre2025salamandratechnicalreport,
title={Salamandra Technical Report},
author={Aitor Gonzalez-Agirre and Marc Pàmies and Joan Llop and Irene Baucells and Severino Da Dalt and Daniel Tamayo and José Javier Saiz and Ferran Espuña and Jaume Prats and Javier Aula-Blasco and Mario Mina and Adrián Rubio and Alexander Shvets and Anna Sallés and Iñaki Lacunza and Iñigo Pikabea and Jorge Palomar and Júlia Falcão and Lucía Tormo and Luis Vasquez-Reina and Montserrat Marimon and Valle Ruíz-Fernández and Marta Villegas},
year={2025},
eprint={2502.08489},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2502.08489},
}
License
Model Index
- Downloads last month
- 767
Safetensors
Model size
8B params
Tensor type
BF16
·