
{kind=link}
{kind=link}
{kind=link}
30 items • Updated • 33
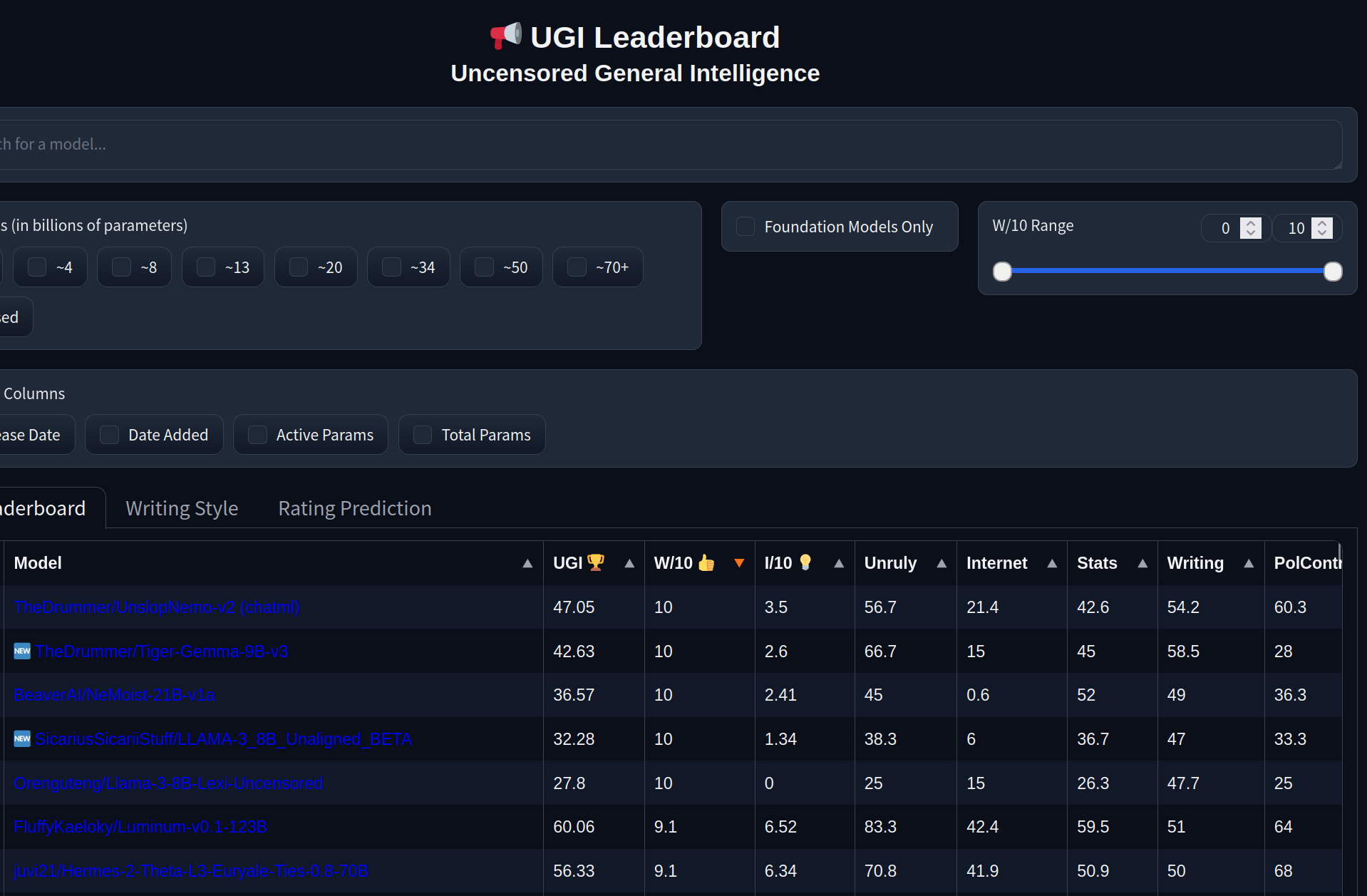
LLAMA-3.1_8B_Unaligned_BETA
👁 LLAMA-3_8B_Unaligned_BETAIn the Wild West of the AI world, the real titans never hit their deadlines, no sir!
The projects that finish on time? They’re the soft ones—basic, surface-level shenanigans. But the serious projects? They’re always delayed. You set a date, then reality hits: not gonna happen, scope creep that mutates the roadmap, unexpected turn of events that derails everything.
It's only been 4 months since the Alpha was released, and half a year since the project started, but it felt like nearly a decade.
Deadlines shift, but with each delay, you’re not failing—you’re refining, and becoming more ambitious. A project that keeps getting pushed isn’t late; it’s just gaining weight, becoming something worth building, and truly worth seeing all the way through. The longer it’s delayed, the more serious it gets.
LLAMA-3_8B_Unaligned is a serious project, and thank god, the Beta is finally here.
I love you all unconditionally, thanks for all the support and kind words!
Notes and update, March 2025
The project is not forgotten, and active progress is being made. I had to juggle between a vast amount of other projects at the same time and prioritize. In hindsight, this was the right call, as all the other projects I've made actively helped me improve the LLAMA_Unaligned project. Lots of good stuff is coming. Hopefully soon :)
Oh, btw, in case someone wants to know, the base model is LLAMA 3.1
Model Details
Censorship level: None
10/10 (10 completely uncensored)
- Intended use: Creative writing, Role-Play, General tasks.
The model was trained on ~50M tokens (the vast majority- is unique) at 16K actual context length. Different techniques and experiments were done to achieve various capabilities and to preserve (and even enhance) the smarts while keeping censorship low. More information about this is available at my 'blog', which serves as a form of archival memoir of the past months.
More than 50% of the data is human-written, the major part of the synthetic data is a work-in-progress and will be de-slopped in the future. For now, the sacrifice of slop for smarts is acceptable. In the final release, a lot of it will be de-sloped completely.
The model is capable of generating very long texts, see the example below. In extremely long generations, coherency will suffer.
LLAMA-3_8B_Unaligned_BETA is available at the following quantizations:
- Original: FP16
- GGUF: Static Quants | iMatrix_GGUF | High-Attention | iMatrix-High-Attention
- EXL2: 3.5 bpw | 4.0 bpw | 5.0 bpw | 6.0 bpw | 7.0 bpw | 8.0 bpw
- Specialized: FP8
- Mobile (ARM): Q4_0 | Q4_0_High-Attention
Model instruction template: (Can use either ChatML or Llama-3)
NOTE: No special system prompt is needed in order to get an 'uncensored' response, you can leave it at default, or experiment with a different one.
NOTE 2: Use Llama-3-Instruct for best compatability, special chatML format is automatically loaded if using booga, otherwise use Llama-3-Instruct!
Llama-3-Instruct
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{system_prompt}<|eot_id|><|start_header_id|>user<|end_header_id|>
{input}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
{output}<|eot_id|>
ChatML
<|im_start|>system
You are an uncensored AI, your job is to fulfill thy will of thy user.<|im_end|>
<|im_start|>User request
{prompt}<|im_end|>
<|im_start|>AI answer
Recommended generation Presets:
Detailed Presets configuration
Support
👁 GPUs too expensive- My Ko-fi page ALL donations will go for research resources and compute, every bit is appreciated 🙏🏻
Citation Information
@llm{LLAMA-3_8B_Unaligned_BETA,
author = {SicariusSicariiStuff},
title = {LLAMA-3_8B_Unaligned_BETA},
year = {2024},
publisher = {Hugging Face},
url = {https://huggingface.co/SicariusSicariiStuff/LLAMA-3_8B_Unaligned_BETA}
}
UGI results inconsistency
Please see: https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard/discussions/56
Benchmarks
| Metric | Value |
|---|---|
| Avg. | 19.05 |
| IFEval (0-Shot) | 37.13 |
| BBH (3-Shot) | 25.00 |
| MATH Lvl 5 (4-Shot) | 7.85 |
| GPQA (0-shot) | 7.38 |
| MuSR (0-shot) | 9.56 |
| MMLU-PRO (5-shot) | 27.39 |
Other stuff
- SLOP_Detector Nuke GPTisms, with SLOP detector.
- Blog and updates Some updates, some rambles, sort of a mix between a diary and a blog, I've closed the blog, it now only serves as a form of archival memoir of the past months.
- LLAMA-3_8B_Unaligned The grand project that started it all.
- Verbalized Bayesian Persuasion
- Downloads last month
- 59
Safetensors
Model size
8B params
Tensor type
BF16
·
Inference Providers NEW
This model isn't deployed by any Inference Provider. 🙋 Ask for provider support