
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Paper • 2205.13147 • Published • 27
Static Embeddings with BERT uncased tokenizer finetuned on various datasets
This is a sentence-transformers model trained on the gooaq, msmarco, squad, s2orc, allnli, paq, trivia_qa, msmarco_10m, swim_ir, pubmedqa, miracl, mldr and mr_tydi datasets. It maps sentences & paragraphs to a 1024-dimensional dense vector space and is designed to be used for semantic search.
Read our Static Embeddings blogpost to learn more about this model and how it was trained.
- 0 Active Parameters: This model does not use any active parameters, instead consisting exclusively of averaging pre-computed token embeddings.
- 100x to 400x faster: On CPU, this model is 100x to 400x faster than common options like all-mpnet-base-v2. On GPU, it's 10x to 25x faster.
- Matryoshka: This model was trained with a Matryoshka loss, allowing you to truncate the embeddings for faster retrieval at minimal performance costs.
- Evaluations: See Evaluations for details on performance on NanoBEIR, embedding speed, and Matryoshka dimensionality truncation. In short, this model is 87.4% as performant as the commonly used
all-mpnet-base-v2. - Training Script: See train.py for the training script used to train this model from scratch.
See static-similarity-mrl-multilingual-v1 for a general-purpose multilingual static embedding model. It's been trained for semantic textual similarity, paraphrase mining, text classification, clustering, and more.
Model Details
Model Description
- Model Type: Sentence Transformer
- Maximum Sequence Length: inf tokens
- Output Dimensionality: 1024 tokens
- Similarity Function: Cosine Similarity
- Training Datasets:
- Language: en
- License: apache-2.0
Model Sources
- Documentation: Sentence Transformers Documentation
- Repository: Sentence Transformers on GitHub
- Hugging Face: Sentence Transformers on Hugging Face
Full Model Architecture
SentenceTransformer(
(0): StaticEmbedding(
(embedding): EmbeddingBag(30522, 1024, mode='mean')
)
)
Usage
Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
pip install -U sentence-transformers
Then you can load this model and run inference.
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("tomaarsen/static-retrieval-mrl-en-v1")
# Run inference
sentences = [
'Gadofosveset-enhanced MR angiography of carotid arteries: does steady-state imaging improve accuracy of first-pass imaging?',
'To evaluate the diagnostic accuracy of gadofosveset-enhanced magnetic resonance (MR) angiography in the assessment of carotid artery stenosis, with digital subtraction angiography (DSA) as the reference standard, and to determine the value of reading first-pass, steady-state, and "combined" (first-pass plus steady-state) MR angiograms.',
'In a longitudinal study we investigated in vivo alterations of CVO during neuroinflammation, applying Gadofluorine M- (Gf) enhanced magnetic resonance imaging (MRI) in experimental autoimmune encephalomyelitis, an animal model of multiple sclerosis. SJL/J mice were monitored by Gadopentate dimeglumine- (Gd-DTPA) and Gf-enhanced MRI after adoptive transfer of proteolipid-protein-specific T cells. Mean Gf intensity ratios were calculated individually for different CVO and correlated to the clinical disease course. Subsequently, the tissue distribution of fluorescence-labeled Gf as well as the extent of cellular inflammation was assessed in corresponding histological slices.',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 1024]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities.shape)
# [3, 3]
This model was trained with Matryoshka loss, allowing this model to be used with lower dimensionalities with minimal performance loss (See Matryoshka Evaluations for evaluations).
Notably, a lower dimensionality allows for much faster and cheaper information retrieval. You can specify a lower dimensionality with the truncate_dim argument when initializing the Sentence Transformer model:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("tomaarsen/static-retrieval-mrl-en-v1", truncate_dim=256)
embeddings = model.encode([
"what is the difference between chronological order and spatial order?",
"can lavender grow indoors?"
])
print(embeddings.shape)
# => (2, 256)
Evaluation
Metrics
Information Retrieval
- Datasets:
NanoClimateFEVER,NanoDBPedia,NanoFEVER,NanoFiQA2018,NanoHotpotQA,NanoMSMARCO,NanoNFCorpus,NanoNQ,NanoQuoraRetrieval,NanoSCIDOCS,NanoArguAna,NanoSciFactandNanoTouche2020 - Evaluated with
InformationRetrievalEvaluator
| Metric | NanoClimateFEVER | NanoDBPedia | NanoFEVER | NanoFiQA2018 | NanoHotpotQA | NanoMSMARCO | NanoNFCorpus | NanoNQ | NanoQuoraRetrieval | NanoSCIDOCS | NanoArguAna | NanoSciFact | NanoTouche2020 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| cosine_accuracy@1 | 0.32 | 0.7 | 0.46 | 0.28 | 0.64 | 0.18 | 0.42 | 0.24 | 0.8 | 0.28 | 0.1 | 0.52 | 0.5714 |
| cosine_accuracy@3 | 0.52 | 0.84 | 0.8 | 0.44 | 0.82 | 0.42 | 0.56 | 0.44 | 0.96 | 0.48 | 0.46 | 0.6 | 0.898 |
| cosine_accuracy@5 | 0.6 | 0.9 | 0.84 | 0.54 | 0.86 | 0.5 | 0.62 | 0.58 | 1.0 | 0.54 | 0.56 | 0.62 | 0.9796 |
| cosine_accuracy@10 | 0.78 | 0.94 | 0.94 | 0.64 | 0.96 | 0.66 | 0.72 | 0.7 | 1.0 | 0.7 | 0.74 | 0.76 | 1.0 |
| cosine_precision@1 | 0.32 | 0.7 | 0.46 | 0.28 | 0.64 | 0.18 | 0.42 | 0.24 | 0.8 | 0.28 | 0.1 | 0.52 | 0.5714 |
| cosine_precision@3 | 0.1933 | 0.5867 | 0.2667 | 0.1933 | 0.3733 | 0.14 | 0.3733 | 0.1467 | 0.3867 | 0.2267 | 0.1533 | 0.2067 | 0.6054 |
| cosine_precision@5 | 0.14 | 0.544 | 0.18 | 0.16 | 0.26 | 0.1 | 0.32 | 0.124 | 0.248 | 0.188 | 0.112 | 0.132 | 0.6204 |
| cosine_precision@10 | 0.104 | 0.452 | 0.1 | 0.104 | 0.148 | 0.066 | 0.244 | 0.076 | 0.13 | 0.14 | 0.074 | 0.084 | 0.5306 |
| cosine_recall@1 | 0.1467 | 0.0805 | 0.4367 | 0.1519 | 0.32 | 0.18 | 0.0428 | 0.24 | 0.7107 | 0.0597 | 0.1 | 0.485 | 0.0398 |
| cosine_recall@3 | 0.239 | 0.1605 | 0.7467 | 0.2983 | 0.56 | 0.42 | 0.0984 | 0.43 | 0.9253 | 0.1417 | 0.46 | 0.57 | 0.1236 |
| cosine_recall@5 | 0.279 | 0.218 | 0.8033 | 0.3793 | 0.65 | 0.5 | 0.1196 | 0.58 | 0.9627 | 0.1947 | 0.56 | 0.595 | 0.2095 |
| cosine_recall@10 | 0.4197 | 0.3143 | 0.9033 | 0.4838 | 0.74 | 0.66 | 0.1389 | 0.69 | 0.9793 | 0.2887 | 0.74 | 0.75 | 0.337 |
| cosine_ndcg@10 | 0.3309 | 0.5681 | 0.6922 | 0.3651 | 0.6547 | 0.4041 | 0.3242 | 0.4534 | 0.8951 | 0.2643 | 0.4078 | 0.6111 | 0.5703 |
| cosine_mrr@10 | 0.4453 | 0.7854 | 0.6397 | 0.3915 | 0.7485 | 0.3245 | 0.5041 | 0.3764 | 0.88 | 0.3998 | 0.3034 | 0.5837 | 0.744 |
| cosine_map@100 | 0.2598 | 0.4335 | 0.6205 | 0.3024 | 0.5798 | 0.3389 | 0.1449 | 0.389 | 0.8594 | 0.205 | 0.3151 | 0.5683 | 0.447 |
Nano BEIR
- Dataset:
NanoBEIR_mean - Evaluated with
NanoBEIREvaluator
| Metric | Value |
|---|---|
| cosine_accuracy@1 | 0.424 |
| cosine_accuracy@3 | 0.6337 |
| cosine_accuracy@5 | 0.703 |
| cosine_accuracy@10 | 0.8108 |
| cosine_precision@1 | 0.424 |
| cosine_precision@3 | 0.2963 |
| cosine_precision@5 | 0.2406 |
| cosine_precision@10 | 0.1733 |
| cosine_recall@1 | 0.2303 |
| cosine_recall@3 | 0.398 |
| cosine_recall@5 | 0.4655 |
| cosine_recall@10 | 0.5727 |
| cosine_ndcg@10 | 0.5032 |
| cosine_mrr@10 | 0.5482 |
| cosine_map@100 | 0.4203 |
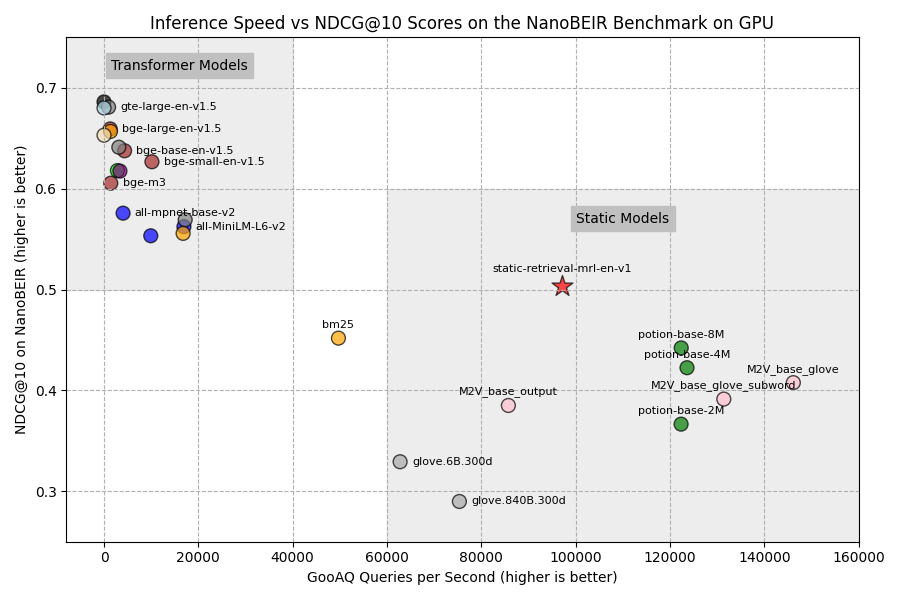
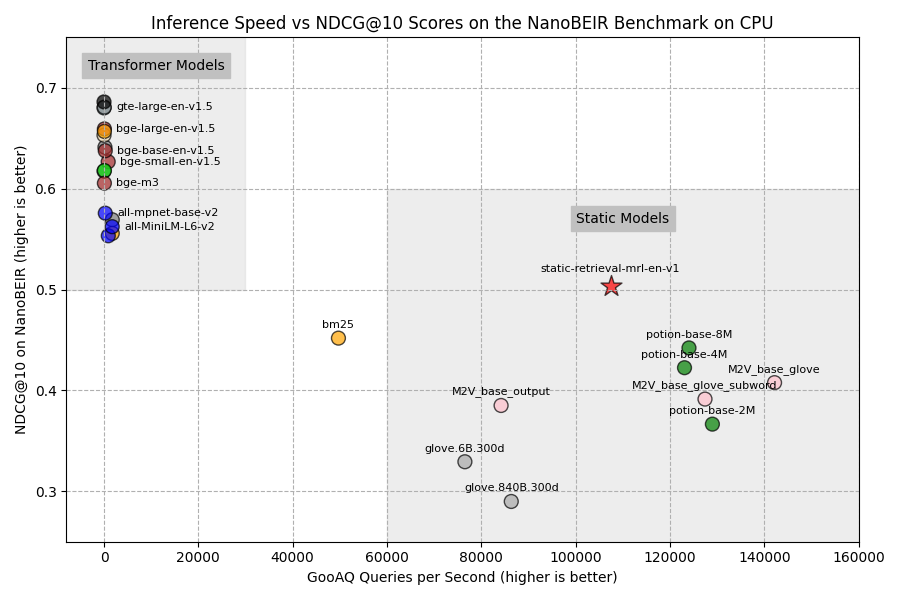
We've evaluated sentence-transformers/static-retrieval-mrl-en-v1 on NanoBEIR and plotted it against the inference speed computed on a RTX 3090 and i7-13700K. For the inference speed tests, we calculated the number of computed query embeddings of the GooAQ dataset per second, either on CPU or GPU.
We evaluate against 3 types of models:
Attention-based dense embedding models, e.g. traditional Sentence Transformer models like
all-mpnet-base-v2,bge-base-en-v1.5, andgte-large-en-v1.5.Static Embedding-based models, e.g.
static-retrieval-mrl-en-v1,potion-base-8M,M2V_base_output, andglove.6B.300d.Sparse bag-of-words model, BM25, often a strong baseline.
NOTE: Many of the attention-based dense embedding models are finetuned on the training splits of the (Nano)BEIR evaluation datasets. This gives the models an unfair advantage in this benchmark and can result in lower downstream performance on real retrieval tasks.
static-retrieval-mrl-en-v1 is purposefully not trained on any of these datasets.
GPU
👁 NanoBEIR performance vs inference speed
CPU
👁 NanoBEIR performance vs inference speed
We can draw some notable conclusions from these figures:
static-retrieval-mrl-en-v1outperforms all other Static Embedding models.static-retrieval-mrl-en-v1is the only Static Embedding model to outperform BM25.static-retrieval-mrl-en-v1is- 87.4% as performant as the commonly used
all-mpnet-base-v2, - 24x faster on GPU,
- 397x faster on CPU.
- 87.4% as performant as the commonly used
static-retrieval-mrl-en-v1is quicker on CPU than on GPU: This model can run extraordinarily quickly everywhere, including consumer-grade PCs, tiny servers, phones, or in-browser.
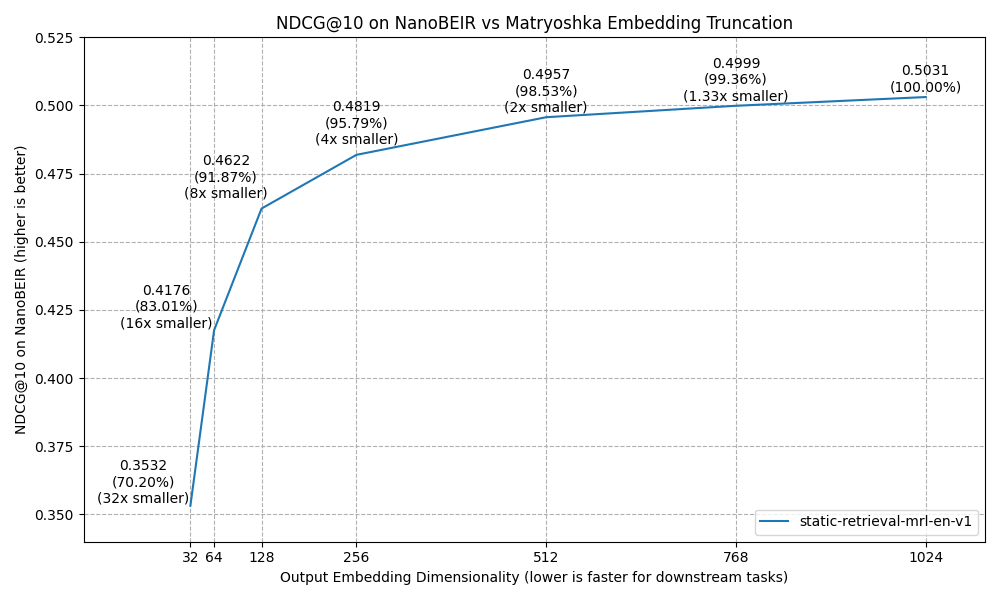
Matryoshka Evaluations
We experimented with the results on NanoBEIR performance when we performed Matryoshka-style dimensionality reduction by truncating the output embeddings to a lower dimensionality.
| Dimensionality | NanoBEIR_mean | NanoArguAna | NanoClimateFEVER | NanoDBPedia | NanoFEVER | NanoFiQA2018 | NanoHotpotQA | NanoMSMARCO | NanoNFCorpus | NanoNQ | NanoQuoraRetrieval | NanoSCIDOCS | NanoSciFact | NanoTouche2020 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1024 | 0.5031 | 0.4077 | 0.3308 | 0.5681 | 0.6921 | 0.3651 | 0.6547 | 0.4040 | 0.3241 | 0.4533 | 0.8950 | 0.2642 | 0.6111 | 0.5702 |
| 512 | 0.4957 | 0.3878 | 0.3360 | 0.5626 | 0.6945 | 0.3517 | 0.6280 | 0.3892 | 0.3206 | 0.4505 | 0.8986 | 0.2657 | 0.5953 | 0.5635 |
| 256 | 0.4819 | 0.3855 | 0.3203 | 0.5407 | 0.6734 | 0.3518 | 0.6027 | 0.4144 | 0.2860 | 0.4254 | 0.8948 | 0.2466 | 0.5620 | 0.5605 |
| 128 | 0.4622 | 0.4001 | 0.2982 | 0.5266 | 0.6273 | 0.3188 | 0.5606 | 0.4025 | 0.2693 | 0.4021 | 0.8930 | 0.2283 | 0.5447 | 0.5368 |
| 64 | 0.4176 | 0.3424 | 0.2809 | 0.5022 | 0.5480 | 0.2831 | 0.4680 | 0.3739 | 0.2153 | 0.3845 | 0.8525 | 0.1680 | 0.5045 | 0.5050 |
| 32 | 0.3532 | 0.2866 | 0.1870 | 0.4292 | 0.4193 | 0.2292 | 0.3602 | 0.3587 | 0.1444 | 0.3525 | 0.8325 | 0.1525 | 0.3983 | 0.4408 |
👁 NanoBEIR performance vs Matryoshka dimensionality reduction
These findings show that reducing the dimensionality by e.g. 2x only has a 1.47% reduction in performance (0.5031 NDCG@10 vs 0.4957 NDCG@10), while realistically resulting in a 2x speedup in retrieval speed.
Training Details
Training Datasets
Evaluation Datasets
Training Hyperparameters
Non-Default Hyperparameters
eval_strategy: stepsper_device_train_batch_size: 2048per_device_eval_batch_size: 2048learning_rate: 0.2num_train_epochs: 1warmup_ratio: 0.1bf16: Truebatch_sampler: no_duplicates
All Hyperparameters
Training Logs
Environmental Impact
Carbon emissions were measured using CodeCarbon.
- Energy Consumed: 2.611 kWh
- Carbon Emitted: 1.015 kg of CO2
- Hours Used: 17.883 hours
Training Hardware
- On Cloud: No
- GPU Model: 1 x NVIDIA GeForce RTX 3090
- CPU Model: 13th Gen Intel(R) Core(TM) i7-13700K
- RAM Size: 31.78 GB
Framework Versions
- Python: 3.11.6
- Sentence Transformers: 3.3.0.dev0
- Transformers: 4.45.2
- PyTorch: 2.5.0.dev20240807+cu121
- Accelerate: 1.0.0
- Datasets: 2.20.0
- Tokenizers: 0.20.1-dev.0
Citation
BibTeX
Sentence Transformers
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
MatryoshkaLoss
@misc{kusupati2024matryoshka,
title={Matryoshka Representation Learning},
author={Aditya Kusupati and Gantavya Bhatt and Aniket Rege and Matthew Wallingford and Aditya Sinha and Vivek Ramanujan and William Howard-Snyder and Kaifeng Chen and Sham Kakade and Prateek Jain and Ali Farhadi},
year={2024},
eprint={2205.13147},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
MultipleNegativesRankingLoss
@misc{henderson2017efficient,
title={Efficient Natural Language Response Suggestion for Smart Reply},
author={Matthew Henderson and Rami Al-Rfou and Brian Strope and Yun-hsuan Sung and Laszlo Lukacs and Ruiqi Guo and Sanjiv Kumar and Balint Miklos and Ray Kurzweil},
year={2017},
eprint={1705.00652},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Datasets used to train sentence-transformers/static-retrieval-mrl-en-v1
Spaces using sentence-transformers/static-retrieval-mrl-en-v1 13
Papers for sentence-transformers/static-retrieval-mrl-en-v1
Evaluation results
- Cosine Accuracy@1 on NanoClimateFEVERself-reported0.320
- Cosine Accuracy@3 on NanoClimateFEVERself-reported0.520
- Cosine Accuracy@5 on NanoClimateFEVERself-reported0.600
- Cosine Accuracy@10 on NanoClimateFEVERself-reported0.780
- Cosine Precision@1 on NanoClimateFEVERself-reported0.320
- Cosine Precision@3 on NanoClimateFEVERself-reported0.193
- Cosine Precision@5 on NanoClimateFEVERself-reported0.140
- Cosine Precision@10 on NanoClimateFEVERself-reported0.104