
{kind=link}
Architecture : Hybrid Attention & MoE ultra-épars
La communauté IA vient de vivre un moment historique : l’équipe Tongyi Qianwen d’Alibaba a ouvert en accès libre la série Qwen3-Next, une avancée majeure alliant performances et efficacité computationnelle. En tant que passionnée d’IA qui suit de près l’innovation des LLM, je suis ravie de vous expliquer pourquoi cette sortie est importante — pas seulement pour les développeurs, mais pour tout l’écosystème qui œuvre pour une IA haute performance plus accessible.
{kind=link}
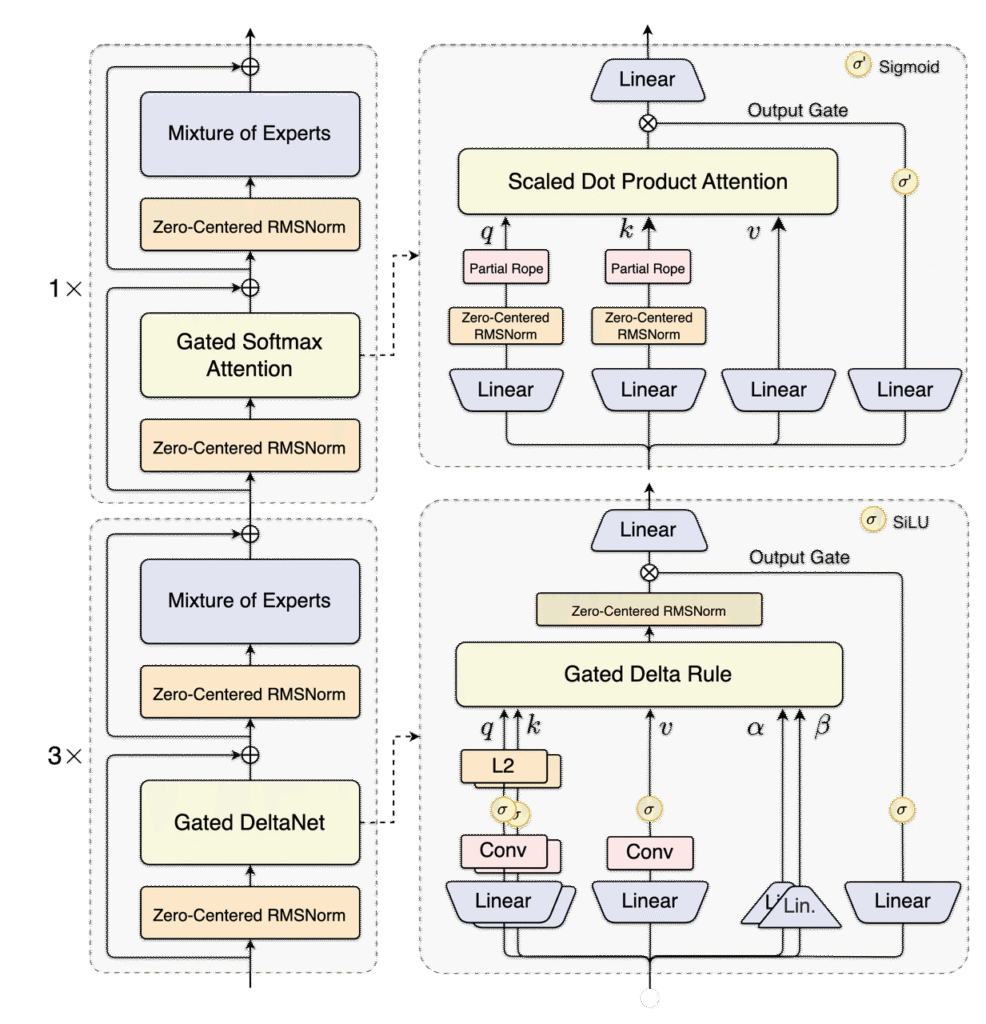
Au cœur de la rupture technologique de Qwen3-Next se trouvent des innovations architecturales, avec en tête le Hybrid Attention Mechanism et une conception Mixture-of-Experts (MoE) ultra-éparse. Commençons par le Hybrid Attention, qui remplace l’attention standard par une combinaison de Gated DeltaNet et Gated Attention. Ce n’est pas qu’un ajustement mineur ; c’est une refonte de la façon dont les LLM traitent les longues séquences. Le Gated DeltaNet, développé en collaboration avec NVIDIA Research et le MIT, permet au modèle de gérer des contextes ultra-longs — jusqu’à 256 000 tokens — avec des coûts mémoire et computationnels qui évoluent presque linéairement avec la longueur de la séquence. Pour les développeurs travaillant sur l’analyse documentaire, la compréhension de code ou la génération de contenu long, cela signifie la fin des arbitrages entre taille du contexte et vitesse.
{kind=link}
Complétant cette architecture, le mécanisme MoE ultra-éparse du modèle phare Qwen3-Next-80B-A3B totalise 80 milliards de paramètres mais n’en active que 3 milliards par token. Ce résultat est rendu possible grâce à une couche MoE avec 512 experts de routage et 1 expert partagé, chaque token n’activant que 10 experts. Les implications sont considérables : on préserve les performances des grands modèles tout en réduisant radicalement la charge computationnelle.
Performances, benchmarks et déploiement
Pour quantifier ces gains, regardons les chiffres. Comparé à son prédécesseur Qwen3-32B-Base, la version de base de Qwen3-Next-80B-A3B offre de meilleures performances en aval tout en réduisant de 90 % le coût total d’entraînement. Pour des contextes dépassant 32 000 tokens, le débit d’inférence est multiplié par 10 — un gain qui se traduit directement par des temps de réponse plus rapides et des coûts opérationnels réduits pour les entreprises. Plus impressionnant encore, la version instruction (*Qwen3-Next-80B-A3B-Instruct*) égale les performances du bien plus gros modèle Qwen3-235B-A22B-Instruct-2507 sur plusieurs benchmarks, tout en le surpassant dans les tâches à contexte ultra-long.
{kind=link}
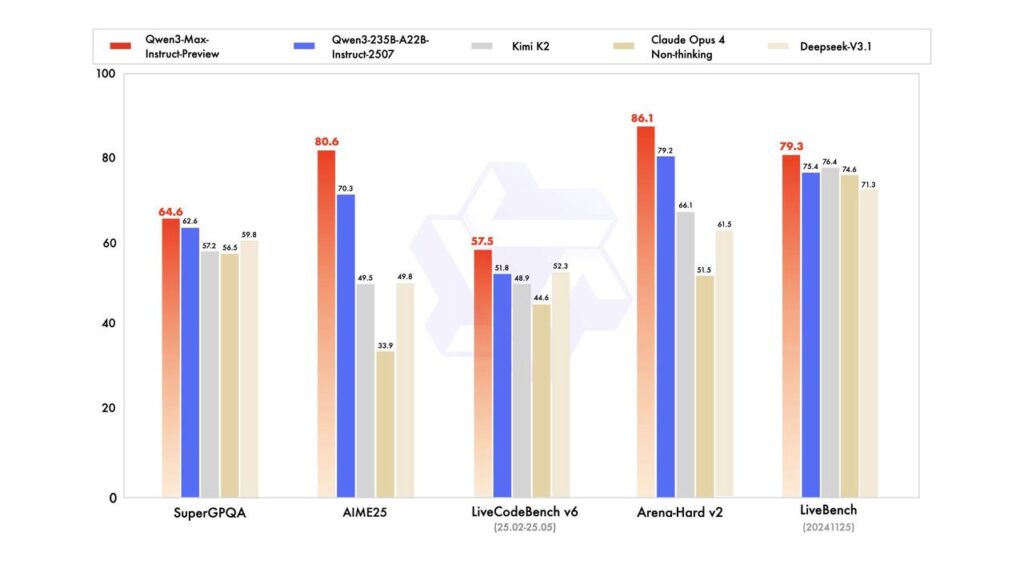
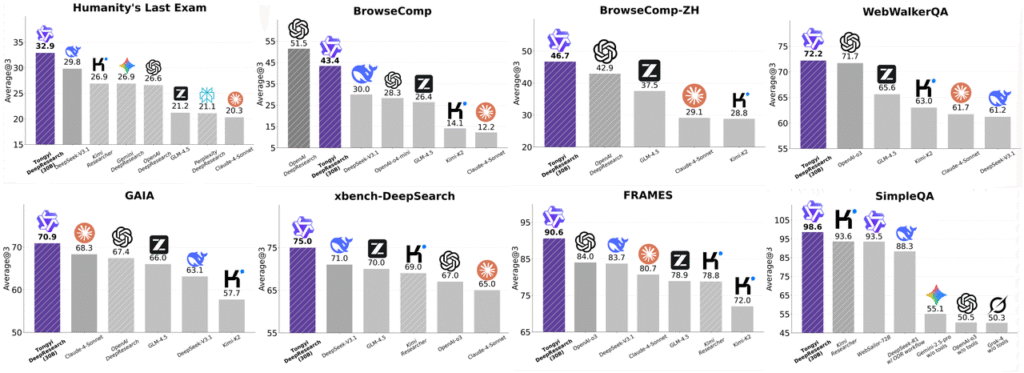
Pour situer ces performances, voici quelques résultats clés. Dans les tâches knowledge-intensive, Qwen3-Next-80B-A3B-Instruct obtient 80,6 sur MMLU-Pro et 90,9 sur MMLU-Redux, surpassant Qwen3-30B-A3B-Instruct-2507. En raisonnement, il atteint 69,5 sur AIME25 et 54,1 sur HMMT25, approchant les scores du modèle 235B. Le code est un autre point fort : 56,6 sur LiveCodeBench v6 et 87,8 sur MultiPL-E, devançant les petits modèles Qwen et même des concurrents comme Gemini-2.5-Flash-Thinking dans certains scénarios de raisonnement complexe. Le benchmark Arena-Hard v2, qui mesure les capacités conversationnelles en conditions réelles, lui attribue un score de 82,7 — supérieur au 79,2 du modèle 235B — preuve que l’efficacité ne se fait pas au détriment de l’utilisabilité.
Sur le plan du déploiement, la compatibilité du modèle avec l’infrastructure existante est un atout maître. Alibaba s’est associé à NVIDIA pour optimiser Qwen3-Next pour les plateformes GPU Hopper et Blackwell. Le NVLink haute vitesse (1,8 To/s) des GPU Blackwell résout les goulots d’échange fréquents dans les modèles MoE, garantissant un routage fluide des experts. Pour les développeurs, les options de déploiement sont flexibles : utilisation de SGLang avec une commande simple comme python3 -m sglang.launch_server --model Qwen/Qwen3-Next-80B-A3B-Instruct --tp 4, exploitation de vLLM pour du serving haut débit, ou intégration avec NVIDIA NIM pour des conteneurs production-ready. Cet écosystème permet aux équipes de commencer à expérimenter avec très peu de friction.
Impact pour l’écosystème & démarrage rapide
Au-delà des spécifications techniques, Qwen3-Next incite un virage dans le paysage des LLM vers l’innovation « efficiency-first ». Pour les startups et petites équipes, la réduction de 90 % des coûts d’entraînement abaisse les barrières à l’entrée et permet à plus d’acteurs de développer des solutions IA sans budget calcul conséquent. Pour les entreprises, le gain d’un facteur 10 en vitesse d’inférence permet des services IA scalables — que ce soit des chatbots support client, des pipelines de traitement documentaire ou des assistants code — sans augmentation proportionnelle des coûts cloud. Même les chercheurs bénéficient de l’open-source, avec accès à une architecture de pointe pour explorer de nouvelles directions dans l’IA efficiente.
{kind=link}
La stabilité et la facilité d’usage n’ont pas été négligées. Le modèle intègre une normalisation des poids avec decay centré sur zéro (zero-centered weight decay layer normalization), assurant des performances constantes pendant pré-entraînement et fine-tuning. La technique de prédiction multi-tokens (multi-token prediction, MTP) accroît encore l’efficacité du pré-entraînement et la vitesse d’inférence, créant un cercle vertueux d’optimisation. Ces améliorations « sous le capot » sont des facilitateurs discrets, mais leur importance en conditions réelles est indéniable — la stabilité est aussi cruciale que la vitesse pour des systèmes IA fiables.
En explorant Qwen3-Next ces derniers jours, ce qui me marque le plus est son équilibre. Ce n’est pas qu’un « modèle rapide » ou un « modèle économique » — c’est un modèle qui allie les deux sans sacrifier les performances. À une époque où les LLM deviennent centraux pour les entreprises et la recherche, ce type de percée en efficience est exactement ce dont la communauté a besoin pour passer de l’expérimentation à l’adoption de masse. La décision d’Alibaba d’open-sourcer la série est tout aussi louable ; elle garantit que ces innovations profitent à tout l’écosystème, pas seulement à quelques-uns.
{kind=link}
Pour les développeurs qui souhaitent commencer, les modèles sont disponibles sur Hugging Face et ModelScope, avec une documentation détaillée sur l’optimisation et le déploiement. Que vous construisiez un outil de niche ou que vous mettiez à l’échelle un système IA d’entreprise, Qwen3-Next offre un point de départ convaincant. Alors que le domaine de l’IA continue d’évoluer, il est clair que la prochaine vague d’innovation sera définie par notre capacité à équilibrer puissance et praticité — et Qwen3-Next établit une référence ambitieuse.
—
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave a Comment Cancel Reply