 |
VOOZH | about |
|
VOOZH | about |
We’re so glad you’re here. You can expect all the best TNS content to arrive Monday through Friday to keep you on top of the news and at the top of your game.
Check your inbox for a confirmation email where you can adjust your preferences and even join additional groups.
Follow TNS on your favorite social media networks.
Become a TNS follower on LinkedIn.
Check out the latest featured and trending stories while you wait for your first TNS newsletter.
In this post, we’ll walk through a real-world example of using ChatGPT to iteratively develop a Postgres function that suppresses the display of duplicate primary columns. Along the way, we’ll explore useful SQL concepts like window functions and SETOF JSON (from Postgres), and we’ll see how an AI assistant can help you learn in moments of need.
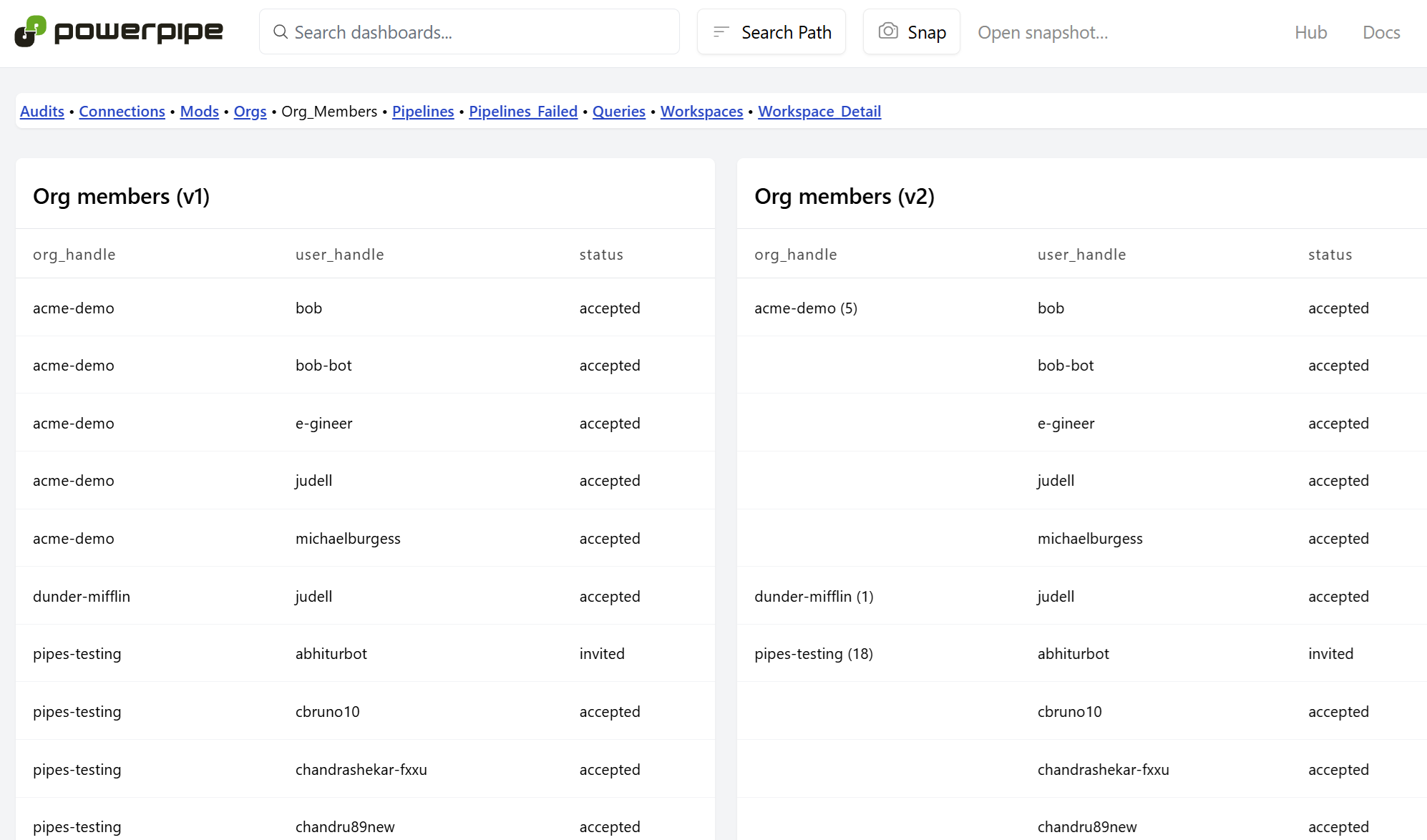
Soon after I started building dashboards to keep track of my Pipes resources, I ran into a familiar challenge. A SQL query yielded results like those shown in the v1 example, but I would rather see them the v2 way.
The v2 panel reduces visual clutter and usefully displays the count of items in each primary partition at a glance. I knew that I’d used the lag() function to do this kind of thing before, but it had been a while since I’d used any of SQL’s window functions, so when I asked ChatGPT for a solution I didn’t mention lag() in order to see what else it might propose.
There were quite a few false starts along the way, and it was tricky to get the ordering to happen properly. But we iterated at lightning speed because I didn’t need to describe failed attempts, I could just show them by uploading screenshots like this one.
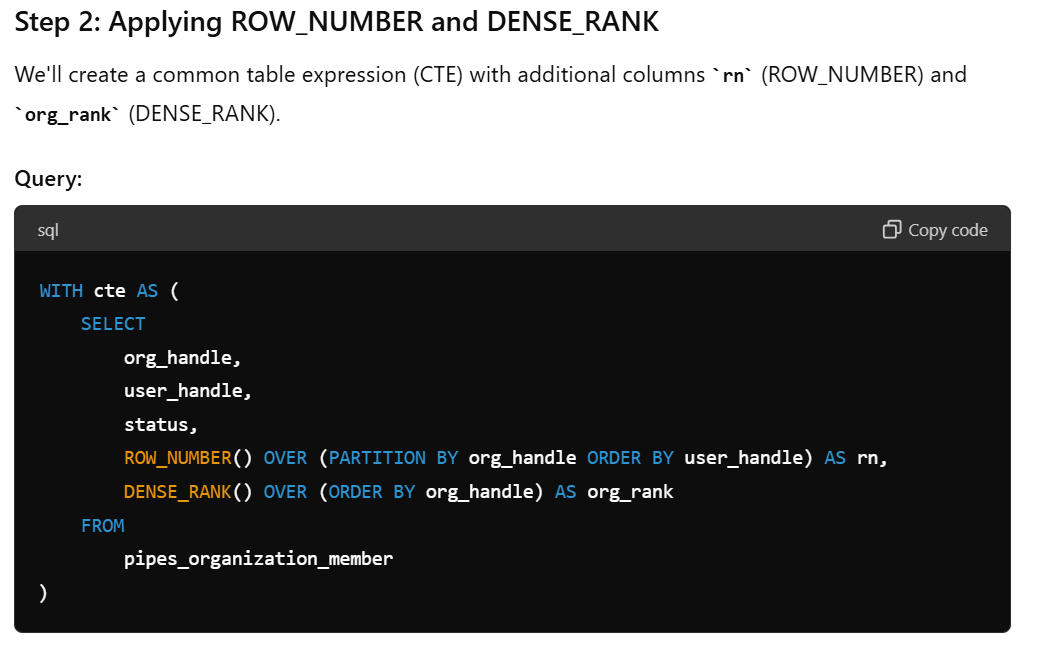
Here was the result of that iteration. And sure enough, instead of lag(), ChatGPT opted for the dense_rank() function.
I had never heard of, never mind used, dense_rank(). So now I wanted to learn about it. For me, it’s always a struggle to visualize things like window functions. It helps to work through step-by-step examples and examine intermediate steps and their values. Here’s the visualization that ChatGPT produced:
To do this, it runs Python with SQLite in a sandbox. To replicate, you can ask for the setup code.
Then run it yourself in SQLite.
Note that I never uploaded this sample data in any textual format, I only uploaded screenshots of data. As we saw last time, the distinction between textual data formats and images of the same data is rapidly (and delightfully) eroding.
Here’s a typical explanation of dense_rank():
“The DENSE_RANK() function in SQL assigns a unique rank to each distinct value in a partition, with no gaps between the rank numbers, even if there are ties.”
I wanted to see an example that illustrates ties, and in this case the data didn’t include a natural way to do that, so I asked ChatGPT to invent a column for that purpose and here’s the visualization I got.
If this is overkill for you then great, congratulations, you are lucky. Some of us need more scaffolding, though, and when we can effortlessly summon it into existence — based on the actual data we’re working with — it’s a big win.
At this point, I raised the alternative I’d intentionally withheld: “What about the lag() function?” I asked. “I think I’ve used it in the past to do this kind of thing more simply.”
“Sure,” chirped ChatGPT, ever eager to please. “Here’s a version that uses the lag() function.” As before, its first few attempts messed up the ordering of secondary columns. I’d have struggled a bit to tell ChatGPT exactly what I meant by “messed up,” but I didn’t have to explain with words because I could capture screenshots and explain with pictures. Also, since ChatGPT was working with the same sample data as before, I could ask it to refer back to prior results. Eventually, it converged on a solution that matched those prior results.
We then discussed the relative merits of the two approaches. My takeaway was that while dense_rank() is more versatile for complex partitioning and ordering, lag() was probably sufficient for my needs.
Which is easier to visualize, though? I went back and forth on that and, after comparing ChatGPT-generated visualizations of both methods, decided it was a wash.
As I added new dashboards, I found myself needing to apply the same method to different tables and different sets of columns. In this situation, I’m always tempted to write a Postgres function to encapsulate the common behavior. But I’ve also learned to tap the brakes and resist that temptation because dynamic programming in Postgres is gnarly.
Historically, the cost of writing the function could easily outweigh the benefit of having written it. But that was before I had an LLM assistant to help me write the function! So now was a good time to revisit that cost/benefit equation.
With or without assistance, you need to tread carefully. The version I ultimately wanted would work with any table, with any primary column, and with an arbitrary number of secondary columns. But trying to do all that at once is a recipe for disaster. So I began by asking for a function that just wrapped the query that was already working.
That still required some iteration. You’re writing a Postgres function that takes string parameters, constructs a SQL query that incorporates those parameters — which might be Postgres identifiers or plain strings — and then runs that query. In my experience the resulting function isn’t likely to work the first time, and indeed it didn’t.
My usual strategy has been to write a debug version of the function that just returns the generated query. You can then run that query by hand or, if it won’t run, quickly spot where the construction of the SQL query from its various pieces of input has gone wrong.
Delightfully I did not even have to suggest that strategy because ChatGPT volunteered debug versions of the function. If you’re already aware of the strategy, that spares you the effort of implementing it. But it might not have occurred to you at all! In that case, you’ll experience the kind of ambient learning that LLMs can enable.
Proceeding in this fashion, we arrived at a function that was properly parameterized by the table name, the primary column, and a pair of secondary columns. And we validated that it worked for two cases that happened to share that pattern.
I’m sure you can guess what came next: a case that required a different number of columns. Now the function would need to receive and process a list of column names. This is the kind of thing that I know is possible but would be hard for me to work out on my own. It wasn’t quick and easy for the two of us, but we did get there. The final version of the function embodies all of the degrees of freedom that I had originally envisioned.
The final result delivered another bit of ambient learning. I knew that a pl/pgsql function can return TABLE or SETOF RECORD, both of which require strong typing that makes it hard to handle lists of arbitrary parameters. We stumbled over that limitation for a while, then ChatGPT came up with RETURNS SETOF JSON which was a beautiful solution. You can see examples of the function’s use here.
I’m tempted to say that SETOF JSON, like dense_rank, was news to me, and that might be true, but there’s a more intriguing possibility. Maybe I read about one or both of these idioms at some point, but not in a teachable moment like this was, so the knowledge didn’t stick. When LLMs surface programming idioms in the moment of need, you’re far more likely to remember them.
It was only after I deployed the function and used it in three different dashboards that the penny finally dropped. This had begun as an exercise to wrap a SQL idiom that made use of the lag() function. But when I looked at the final version of the function, I realized it wasn’t using lag(). Nor was it using dense_rank(). Just row_number() with partition logic was sufficient. Why, I asked ChatGPT, wasn’t that initially obvious?
ChatGPT: The final solution using ROW_NUMBER() and partition logic was not immediately apparent due to a combination of reliance on familiar patterns, the evolving understanding of requirements, and the iterative nature of problem-solving. This process highlights the importance of flexibility and openness to re-evaluating initial approaches to find the simplest and most effective solution.
It’s a good answer that synthesizes wisdom drawn from the human minds represented in the corpus of SQL queries and related conversations that ChatGPT feeds on.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}