 |
VOOZH | about |
|
VOOZH | about |
This article was published as a part of the Data Science Blogathon
Today, AI is getting adopted in everyday life and now it is more important to ensure that decisions that have been taken using AI are not reflecting discriminatory behavior towards a set of populations. It is important to take fairness into consideration while consuming the output from AI. A quote from “The Guardian” has summarized it very well –
“Although neural networks might be said to write their own programs, they do so towards goals set by humans, using data collected for human purposes. If the data is skewed, even by accident, the computers will amplify injustice.” – The Guardian
Discrimination towards a sub-population can be created unintentionally and unknowingly but while the deployment of any AI solution, a check on bias is imperative. In this article, we will discuss
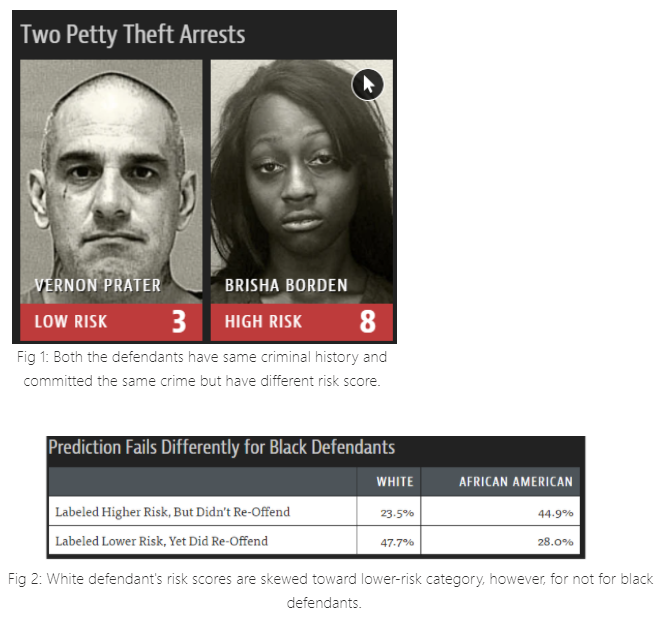
In the United States, amongst the population that has been sent to lock-up have blacks in disproportionate number. For centuries, the key decisions in the legal process are governed by human instincts and biases. When machines learned from this data to do the risk assessment score of future crime, it propagates the human bias in the models, and as a result, the model is found to have racial disparities. The algorithm makes mistakes with both black and white at the same rate but in different ways, as shown in Fig 1 and Fig 2.
These risk assessment scores along with other factors are being used by judges to suggest a treatment plan for defendants, deciding the term of sentence, etc. So, to be fair and ethical to everyone, bias should be analyzed and mitigated for factors like race, skin color, nationality.
These risk assessment scores along with other factors are being used by judges to suggest a treatment plan for defendants, deciding the term of sentence, etc. So, to be fair and ethical to everyone, bias should be analyzed and mitigated for factors like race, skin color, nationality.
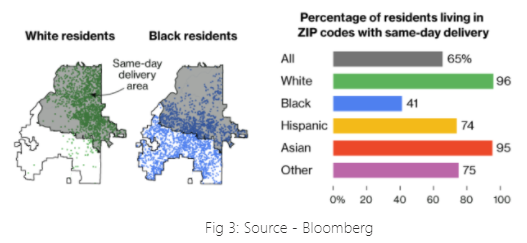
In the United States, Amazon decided to expand same-day delivery areas based on various factors without being racist intentionally. However, due to historical biases against African-Americans were created due to the National Housing Act of 1934, where African-Americans were excluded from getting mortgages, and in turn, they got cut from getting into affluent neighborhoods. This creates pockets of discrimination and with time discrimination continues to reproduce.
Factors that Amazon may have used to get the best yield from the same-day delivery program is not directly using Race as a deciding factor but the systematic racism must have affected the model outcome to choose such areas. For e.g. as shown in Fig 3, the Northern half of Atlanta, home to 96% of the city’s white residents, has same-day delivery. However, southern Atlanta, where 90% of the residents are black, is excluded from same-day delivery.
Takeaway: It is important to check model bias on sensitive factors before deploying it in production.
2. What are the sources of bias?
As we have seen in the above examples that machine learning models developed a bias towards a certain section of the population due to human bias and/or historical bias present in training datasets. Likewise, there are multiple ways by which such biases can seep into the model.
Model learn from biased data and make decisions, these decisions affect the future data that gets used to subsequent model training. In this loop, bias keeps on propagating and gets enlarged over time.
Due to the propagation of biases into the machine learning feedback loop, bias for a specific population enlarge with time. As a result, AI can deepen social inequality [4]
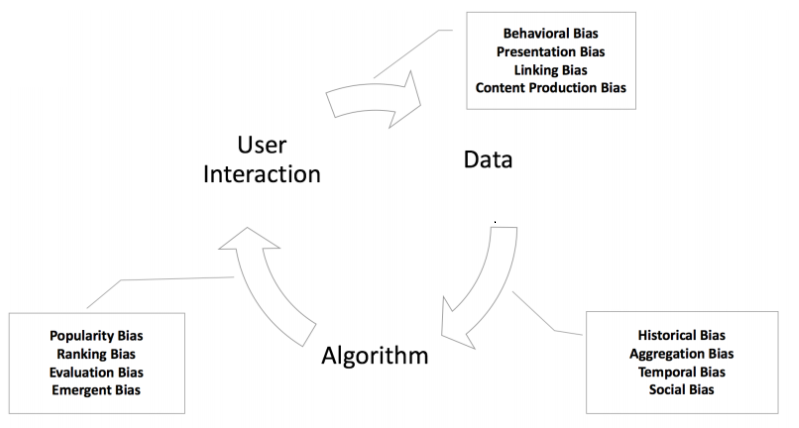
In Fig 4, biases are grouped on each arrow showing where they are most prevalent. Users can study the source of bias and try to address them most effectively at the source.
Fig 4: Due to the feedback loop, biases keep propagating and get enlarged with time
There are many ways by which bias can enter into the machine learning models. To take few examples –
Popularity Bias: Most of the recommender systems suffer from this bias [5] i.e most popular items are recommended frequently but less popular items are recommended rarely by the recommendation algorithm. However, for businesses, recommending rarely bought items is very important as they are less likely to be discovered.
Behavioral Bias: A bank trained a model to predict the ability of the applicant to repay the loan using the applicant’s financial history, employment history, and demographic information. They use historical bank loan decision data. However in this approach, bias arises because loan managers denied loans unfairly to the minority groups in the past, the AI will consider these groups’ general repayment ability to be lower.
1. Representation Bias: Most of the images in the ImageNet dataset are from a western country. So when a model is trained on this data, it predicts well on western country images than from African or Asian country images. When this model is used on the African or Asian origin population, it suffers from representation bias and gave poor accuracy.
2. Sample bias: If a model is trained on data where sample size for a specific population is not enough then the model won’t be able to predict outcome accurately for that specific population.
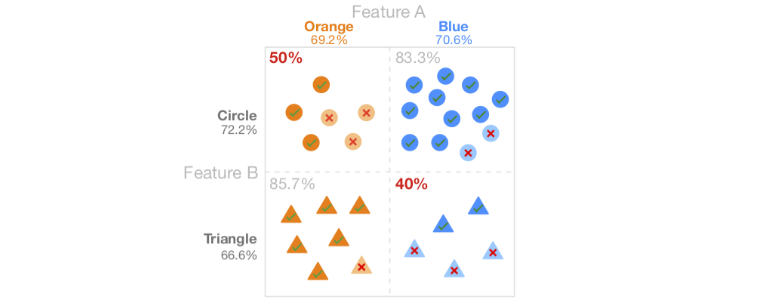
We say the model is biased if prediction accuracy for a specific group of population is either very low or very high. Bias in the model are often hidden and it becomes difficult to determine if the model is biased or not mainly due to intersectional biases. Detecting bias for a single feature is easy, for example, race, compare accuracy between each race (e.g. the model has lower accuracy for black than for white). But if we look at all the combinations of race, sex, and income we may have to compare hundreds of groups.
As shown in fig 5, the low accuracy of the intersectional group, blue triangles, is hidden by the aggregate accuracy metrics of shape and color that appear more equal. Likewise, when we look for subgroups of the population, we will likely find similar model biases.
To check if a model is fair towards a set of protected features (i.e. features that represent protected groups) such as age, gender, race, religion, national origin, etc, we can do the following-
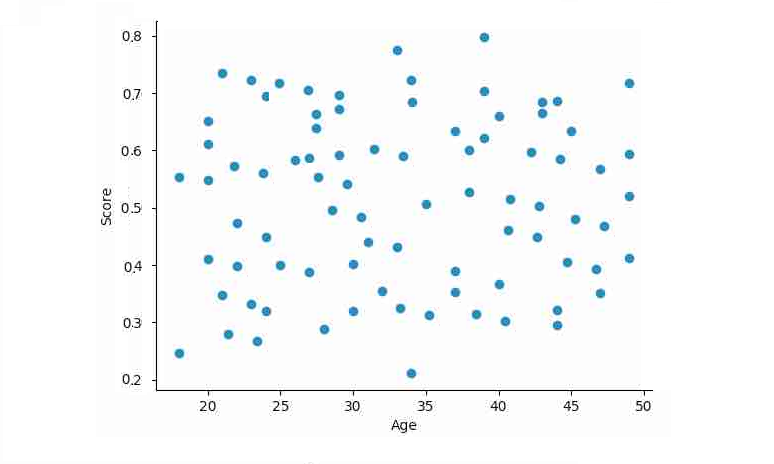
1. If your protected variable is continuous like age, then perform the correlation analysis between continuous variable and probability score. If there is no linear trend between the two, the correlation should come close to 0 as shown in Fig 6 then the model is not biased wrt. this variable.
FIg 6: Scatter plot between age and predicted scores
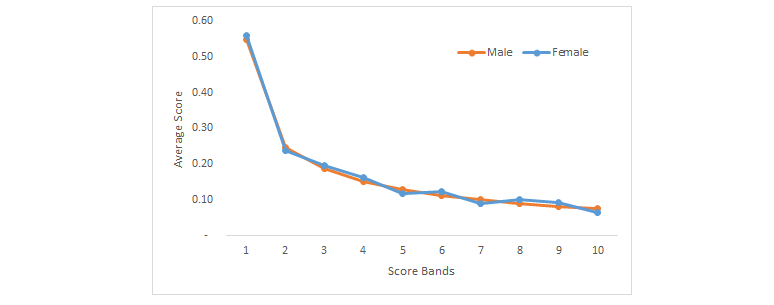
2. If your protected variable is discrete like gender, then plotting the average score by different score bands for different genders should converge if the model has no bias as shown in Fig 7.
Fig 7: Average scores by score bands
In this article, we developed an understanding of why ethics in AI is important and how it may creep in unknowing into the models? In the next article, we will go through how can we take care of these biases before moving the model into production.
1.https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing
2.https://www.usatoday.com/story/tech/news/2016/04/22/amazon-same-day-delivery-less-likely-black-areas-report-says/83345684/
3. https://www.bloomberg.com/graphics/2016-amazon-same-day/
4.https://theconversation.com/artificial-intelligence-can-deepen-social-inequality-here-are-5-ways-to-help-prevent-this-152226
5.Managing
Popularity Bias in Recommender Systems with Personalized Re-ranking; Himan
Abdollahpouri, Robin Burke, Bamshad Mobasher; https://arxiv.org/abs/1901.07555
Author
, Advanced Analytics Practice Lead,
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.
GPT-4 vs. Llama 3.1 – Which Model is Better?
Llama-3.1-Storm-8B: The 8B LLM Powerhouse Surpa...
A Comprehensive Guide to Building Agentic RAG S...
Top 10 Machine Learning Algorithms in 2026
45 Questions to Test a Data Scientist on Basics...
90+ Python Interview Questions and Answers (202...
8 Easy Ways to Access ChatGPT for Free
Prompt Engineering: Definition, Examples, Tips ...
What is LangChain?
What is Retrieval-Augmented Generation (RAG)?
Edit
Resend OTP
Resend OTP in 45s
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}