 |
VOOZH | about |
|
VOOZH | about |
The best LLM for Coders is back with some new abilities. Anthropic recently launched Claude Sonnet 4.5, a powerful addition to its suite of LLMs. This new release significantly boosts capabilities, especially for tasks requiring advanced Agentic AI. It shows marked improvements in areas like code generation and multimodal reasoning, setting new standards for efficiency and reliability. The model promises a leap in performance across various benchmarks. This deep dive explores all aspects of this significant development.
Claude Sonnet 4.5 represents a strategic advancement for Anthropic. It combines high performance with enhanced safety protocols. This model targets complex tasks that demand a nuanced understanding. It offers a compelling balance of speed, cost, and intelligence for many applications.
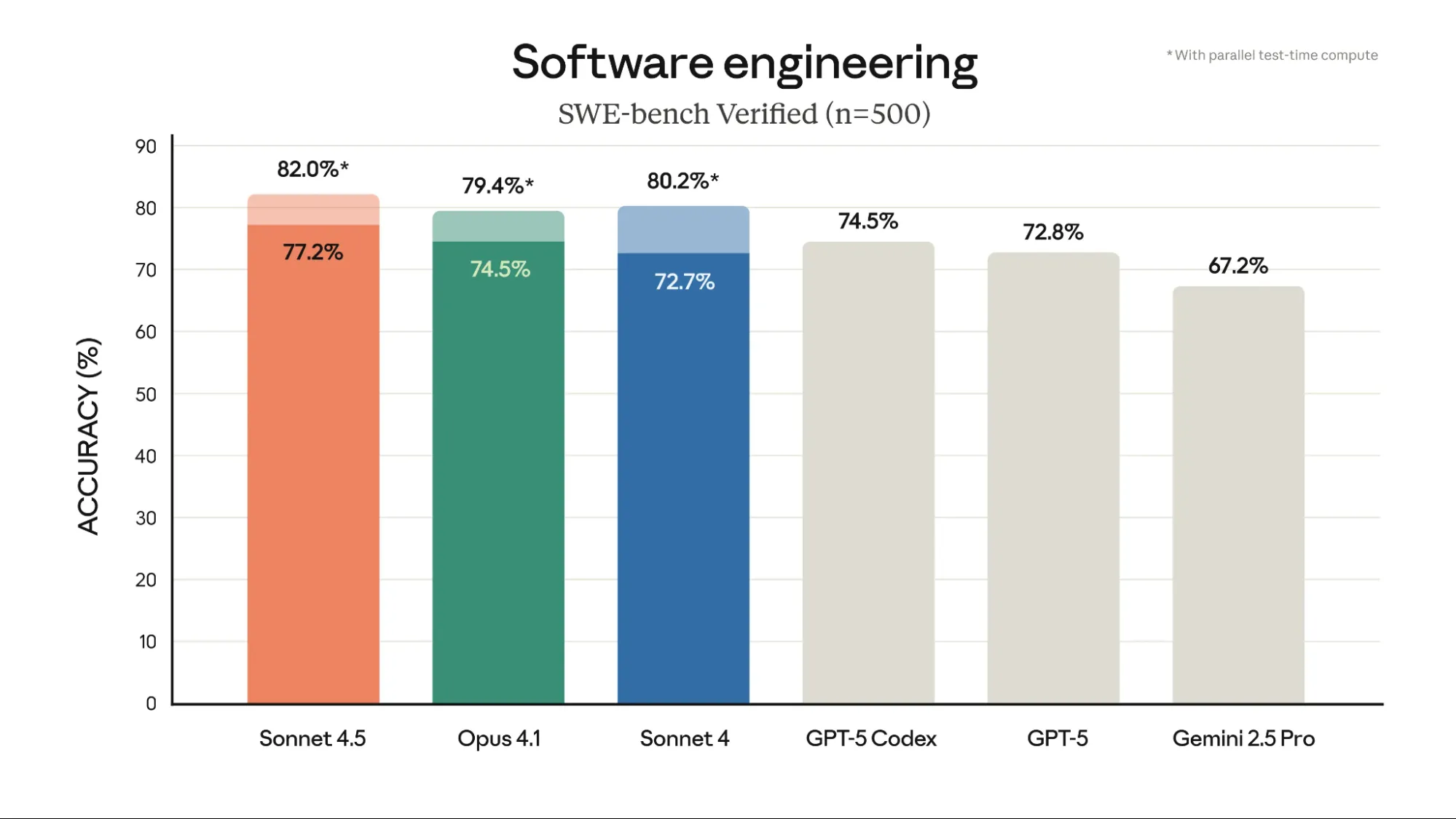
Sonnet 4.5 is state-of-the-art on the SWE-bench Verified evaluation, which measures real-world software coding abilities. Practically speaking, we’ve observed it maintaining focus for more than 30 hours on complex, multi-step tasks.
Claude Sonnet 4.5 underwent rigorous testing. Its performance stands out against competitors. Benchmarks show its strength in diverse domains. These results highlight its advanced capabilities.
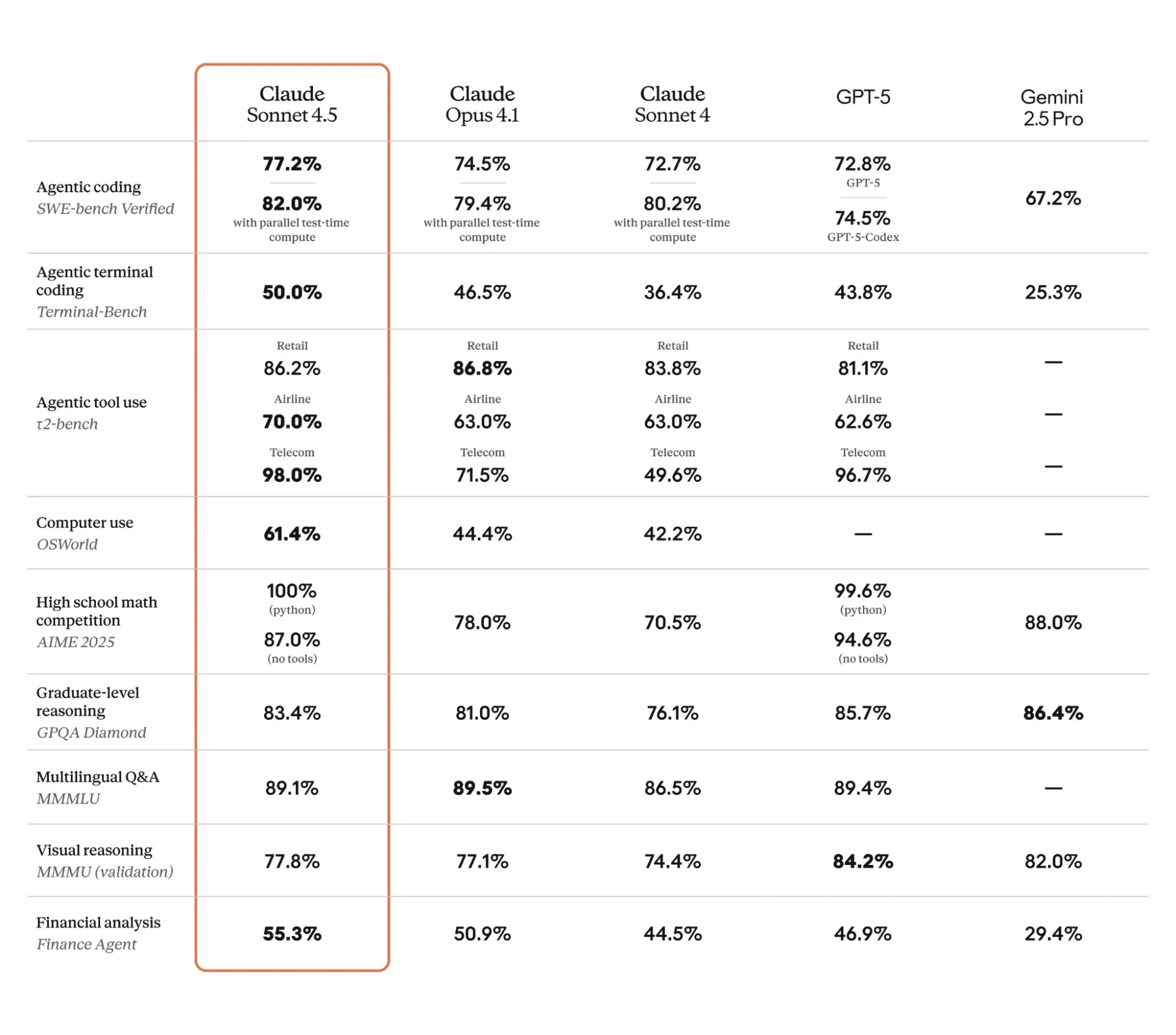
Sonnet 4.5 shows leading performance in agentic tasks. On the SWE-bench, it achieved 77.2% verified accuracy. This rises to 82.0% with parallel test-time computation. This surpasses Claude Opus 4.1 (74.5%) and GPT-5 Codex (74.5%). Its strength in code generation is clear. For agentic terminal coding (Terminal-Bench), Sonnet 4.5 scored 50.0%. This leads all other models, including Opus 4.1 (46.5%). In agentic tool use (t2-bench), Sonnet 4.5 scored 70.0% for airline tasks. It achieved an impressive 98.0% for telecom tasks. This demonstrates its practical utility for Agentic AI workflows. The model also scored 61.4% on OSWorld for computer use. This leads Opus 4.1 (44.4%) significantly.
Sonnet 4.5 shows strong reasoning skills. It scored 100% on high school math problems. These problems were from AIME 2025 using Python. This outcome highlights its precise mathematical abilities. For graduate-level reasoning (GPQA Diamond), it achieved 83.4%. This places it among the top LLMs.
In Multilingual Q&A (MMMLU), Sonnet 4.5 achieved 89.1%. This shows its global language comprehension. Its visual reasoning (MMMU validation) score was 77.8%. This capability supports diverse data inputs. This strengthens its multimodal reasoning.
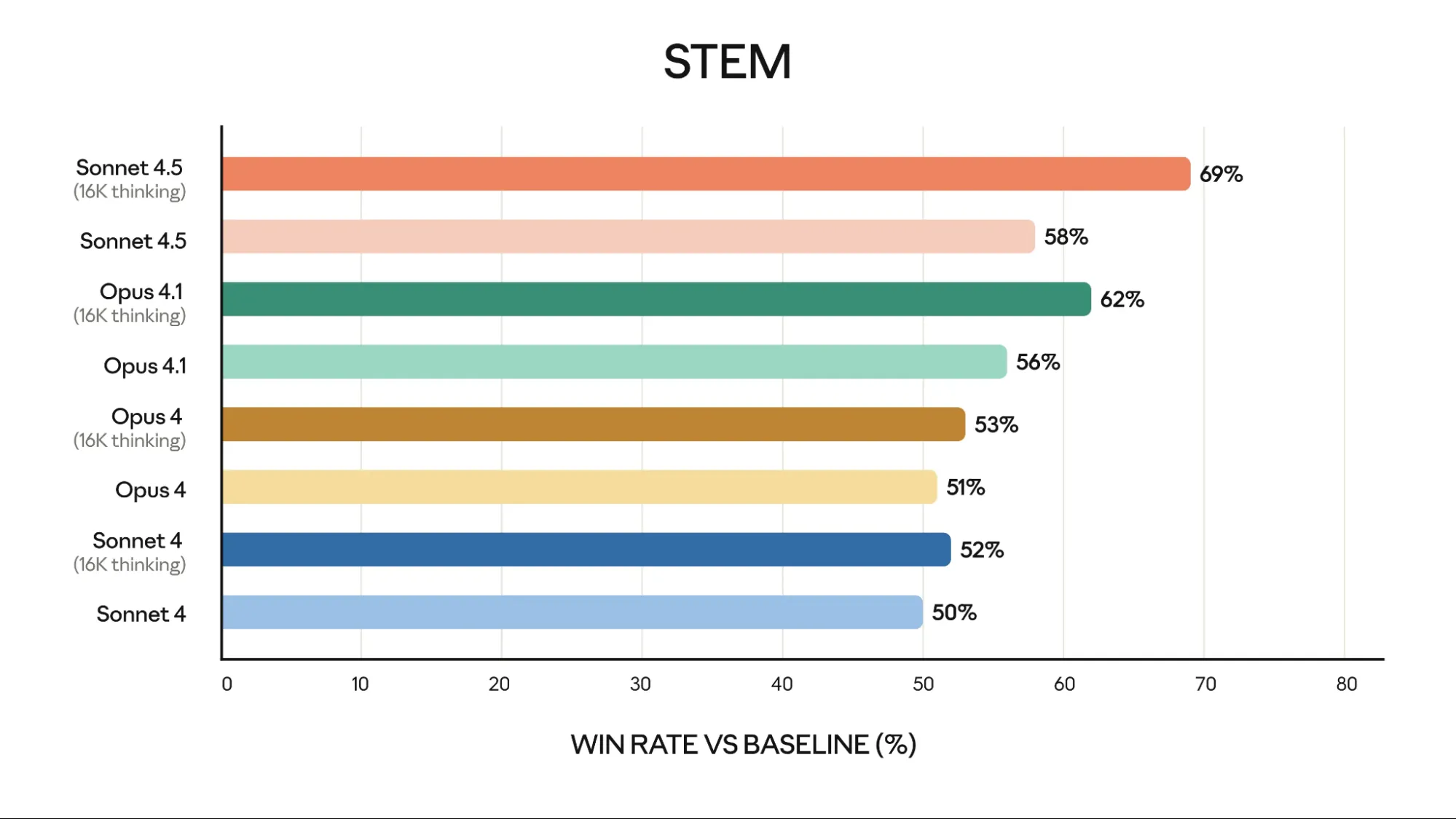
Sonnet 4.5 thinking excels in financial tasks. It achieved 69% on the STEM benchmark. This performance surpasses Opus 4.1 thinking (62%) and GPT-5 (46.9%). This indicates its value for specialized financial analysis.
Also, Claude Sonnet 4.5 excels in finance, law, medicine, and STEM. It shows Claude Sonnet 4.5 dramatically has better domain-specific knowledge and reasoning compared to older models, including Opus 4.1.
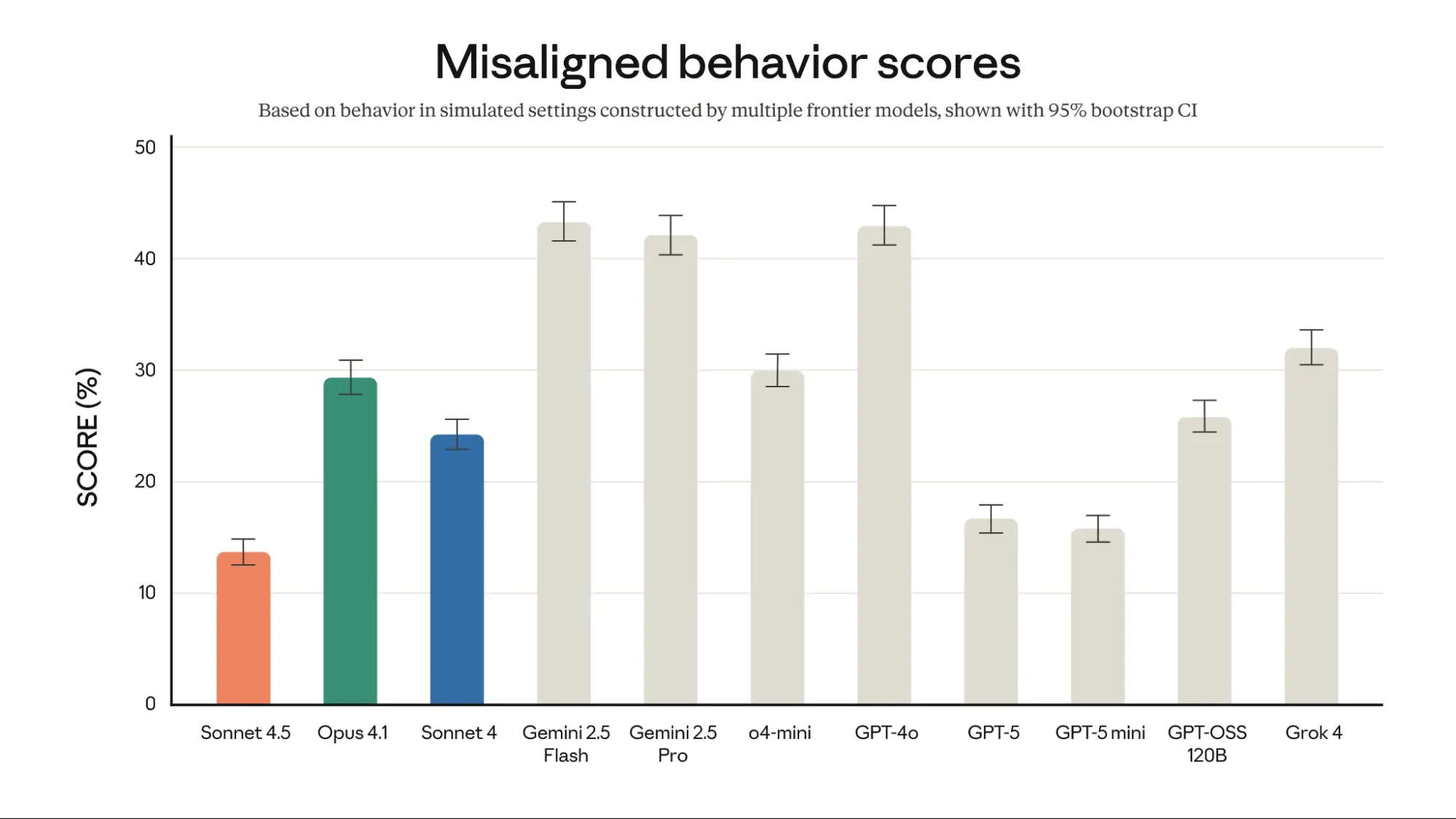
Anthropic prioritizes safety in its LLMs. Claude Sonnet 4.5 shows low misaligned behavior scores. It scored approximately 13.5% in simulated settings. This is notably lower than GPT-4o (~42%) and Gemini 2.5 Pro (~42-43%). This focus on safety makes Claude Sonnet 4.5 a reliable option. Anthropic’s research ensures safer interactions.
Overall misaligned behavior scores from an automated behavioral auditor (lower is better). Misaligned behaviors include (but are not limited to) deception, sycophancy, power-seeking, encouragement of delusions, and compliance with harmful system prompts.
Developers can access Sonnet 4.5 immediately. It is available through Anthropic’s API. Simply use claude-sonnet-4-5 via the Claude API. Pricing remains the same as Claude Sonnet 4, at $3-$15 per million tokens.
pip install anthropic
import anthropic
# Initialize the Anthropic client using the API key from your environment variables.
client = anthropic.Anthropic()
def get_claude_response(prompt: str) -> str:
"""
Sends a prompt to the Claude Sonnet 4.5 model and returns the response.
"""
try:
response = client.messages.create(
model="claude-sonnet-4-5-20250929", # Use the latest model ID
max_tokens=1024,
messages=[
{"role": "user", "content": prompt}
]
)
# Extract and return the content of the response.
return response.content[0].text
except Exception as e:
return f"An error occurred: {e}"
# Example usage
user_prompt = "Explain the concept of quantum computing in simple terms."
claude_response = get_claude_response(user_prompt)
print(f"Claude's response:\n{claude_response}")Users can also access it via the developer console. Various partnering platforms will also offer access. These include Amazon Bedrock and Google Cloud Vertex AI. The model aims for broad accessibility. This supports diverse development needs.
There is also a limited, free version of Sonnet 4.5 available to the public. The free version is intended for general use and has significant usage restrictions compared to paid plans. The Session-based limitations reset every five hours. Instead of a fixed daily message count, your limit depends on the complexity of your interactions and current demand.
Go to Claude, and you can try Sonnet 4.5 for free.
Testing Claude Sonnet 4.5 with specific tasks reveals its power. These examples highlight its strengths. They showcase their advanced reasoning and code generation.
This task combines visual data interpretation with deep textual analysis. It showcases Claude Sonnet 4.5’s multimodal reasoning. It also highlights its specific strengths in financial analysis.
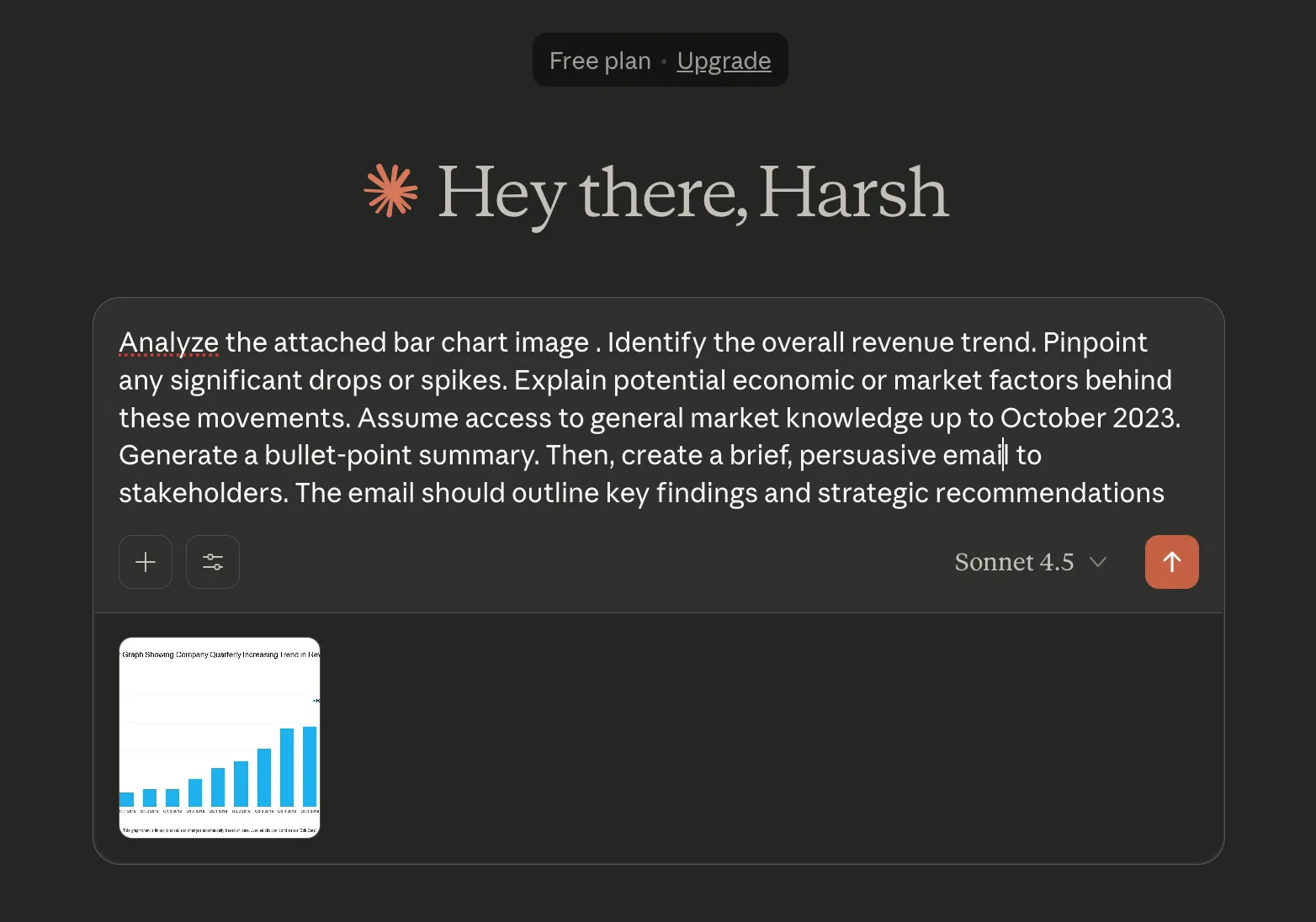
Prompt: “Analyze the attached bar chart image. Identify the overall revenue trend. Pinpoint any significant drops or spikes. Explain potential economic or market factors behind these movements. Assume access to general market knowledge up to October 2023. Generate a bullet-point summary. Then, create a brief, persuasive email to stakeholders. The email should outline key findings and strategic recommendations.”
Output:
Claude Sonnet 4.5 demonstrates its multimodal reasoning here. It processes visual information from a chart. Then it integrates this with its knowledge base. The task requires financial analysis to explain market factors. Generating a summary and an email tests its communication style. This shows its practical application.
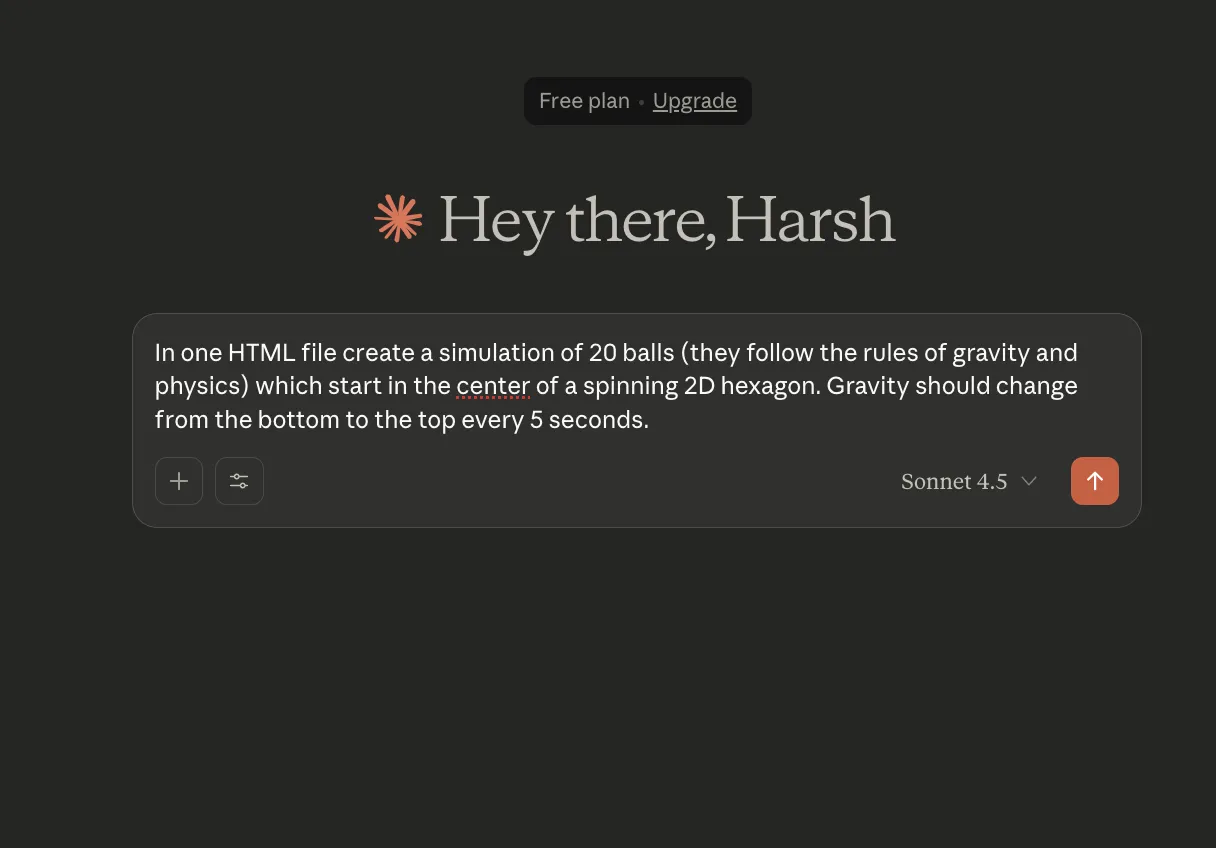
Prompt: “In one HTML file, create a simulation of 20 balls (they follow the rules of gravity and physics) which start in the center of a spinning 2D hexagon. Gravity should change from the bottom to the top every 5 seconds.”
Output:
You can access the deployed HTML file here: Claude
Claude Sonnet 4.5 demonstrates its multimodal reasoning here. It processes visual information from a chart. Then it integrates this with its knowledge base. The task requires financial analysis to explain market factors. Generating a summary and an email tests its communication style. This shows its practical application.
It shows Sonnet 4.5’s capabilities to handle complex multi-task prompts over an extended horizon. It shows the model’s reasoning as it simulated the gravity inside the 2D Hexagon. The generated HTML is error-free, and the hexagon is rendered in the first iteration only.
Claude Sonnet 4.5 offers strong agentic capabilities that are a powerful yet safe option for developers. The model’s efficiency and multimodal reasoning enhance AI applications. This release underscores Anthropic’s commitment to responsible AI. It provides a robust tool for complex problems. Claude Sonnet 4.5 sets a high bar for future LLMs. As we know, Claude always focuses more on the coders, based on the clear advantage their models had in coding-related tasks in contrast to their contemporaries. This time, they have increased their specific domain knowledge abilities like Law, Finance, and Medicine.
Claude Sonnet 4.5 marks a notable advancement in Agentic AI. It provides enhanced code generation and multimodal reasoning. Its strong performance across benchmarks is clear. The model also features superior safety. Developers can integrate this powerful LLM today. Claude Sonnet 4.5 is a reliable solution for advanced AI challenges.
A. Claude Sonnet 4.5 features enhanced agentic capabilities, better code generation, and improved multimodal reasoning. It offers a strong balance of performance and safety.
A. It shows leading performance in SWE-bench and Terminal-Bench. This includes 82.0% on SWE-bench with parallel test-time compute, surpassing many competitors.
A. Yes, it achieved a 100% score on high school math competition problems (AIME 2025). This shows precise mathematical and reasoning abilities.
Harsh Mishra is an AI/ML Engineer who spends more time talking to Large Language Models than actual humans. Passionate about GenAI, NLP, and making machines smarter (so they don’t replace him just yet). When not optimizing models, he’s probably optimizing his coffee intake. 🚀☕
GPT-4 vs. Llama 3.1 – Which Model is Better?
Llama-3.1-Storm-8B: The 8B LLM Powerhouse Surpa...
A Comprehensive Guide to Building Agentic RAG S...
Top 10 Machine Learning Algorithms in 2026
45 Questions to Test a Data Scientist on Basics...
90+ Python Interview Questions and Answers (202...
8 Easy Ways to Access ChatGPT for Free
Prompt Engineering: Definition, Examples, Tips ...
What is LangChain?
What is Retrieval-Augmented Generation (RAG)?
Edit
Resend OTP
Resend OTP in 45s
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}