 |
VOOZH | about |
|
VOOZH | about |
“China is going to win the AI race.” A recent statement made by the CEO of Nvidia, Jensen Huang, has created a lot of buzz. Models that have been made in China have outgrown the initial assumptions of them being “GPT knock-offs”. With model releases pushing the boundary of what was possible before, while being economical and open-source, they’ve garnered a lot of attention. Newer models even surpassing AI colossi like ChatGPT, Claude and Gemini, at a fraction of the cost.
This article would elucidate how Chinese AI models have advanced tremendously in such a short span, and what countries playing catch up in this race, can learn from them.
“The best optimization is often subtraction.” This motto lies at the crux of the AI models that China produces. Chinese models are winning not because they have more resources, but because they’ve learned to use fewer resources better.
Western labs like OpenAI, Anthropic, and Google have built incredible hardware infrastructure by scaling computation and data. Chinese labs on the other hand, were forced by export bans, cost ceilings, and limited access to Nvidia chips, to do the opposite: make models that are smaller, faster, cheaper, and still competitive. The optimization route wasn’t a choice—it was a compulsion.
This is how the above phenomenon played out:
Unlike AI development in the west where progress is made solely by companies or startups, China’s government heavily incentivised making progress in the domain of AI. This is done by offering:
The aforementioned attempts ensure that development of AI isn’t considered as separate from the rest, and instead is seen as an enabler by all.
This is a major problem for AI development in the US, as the government’s stringent policy towards foreign imports and exorbitant tariffs makes it hard for its tech hubs to do business with foreign countries. U.S. restrictions on sale of advanced AI chips to China backfired, by pushing China to build its own stack.
China took the Apple route to AI, creating tightly integrated systems, where everything from building specialized hardware, to creating aligned software, and all the way to having a local supply chain, was done in China. Instead of using GPUs that are generalized for a multitude of tasks like Gaming, Video Processing, Programming, the hardware was optimized specially for training models.
Many Western AI operations still lean heavily on general-purpose GPUs (originally built for graphics or broad compute workloads) rather than chips custom-designed for specific AI workloads. General-purpose hardware is optimized for a broad use case. This means less tailoring for certain AI-specific operations like massive matrix-multiplication, sparse models, and low-precision inference. This puts them at an inherent disadvantage, where they are using a fraction of the total compute capacity of what they offer as a whole.
The shift to specialized hardware is progressing, but at a slow pace. Where models in China are already being trained on tailored hardware, such scenarios in the west are still far and few.
Most of the talent that is housed in the US, isn’t of the US itself. Western countries for the longest time, benefitted from the brains across the world, by offering them lucrative pay and better standard of living than what was on offer in their country. But with tariffs and other strict policies in place, this has become difficult.
China on the other hand, boasts one of the largest skilled population pools in the world. The statement “They (China) have many AI researchers, in fact 50% of the world’s AI researchers are in China. And they develop very good AI technology.” made by Jensen Huang, captures this perfectly. China not only benefits from a centralized system established by its government, but also from the massive resourceful population.
One aspect of AI in which China is the undisputed leader is in Open-Source. Now let me get this straight: China didn’t opt to take the open-source route due to altruism from its side. Instead, its due to competition, necessity, and strategy all colliding at once.
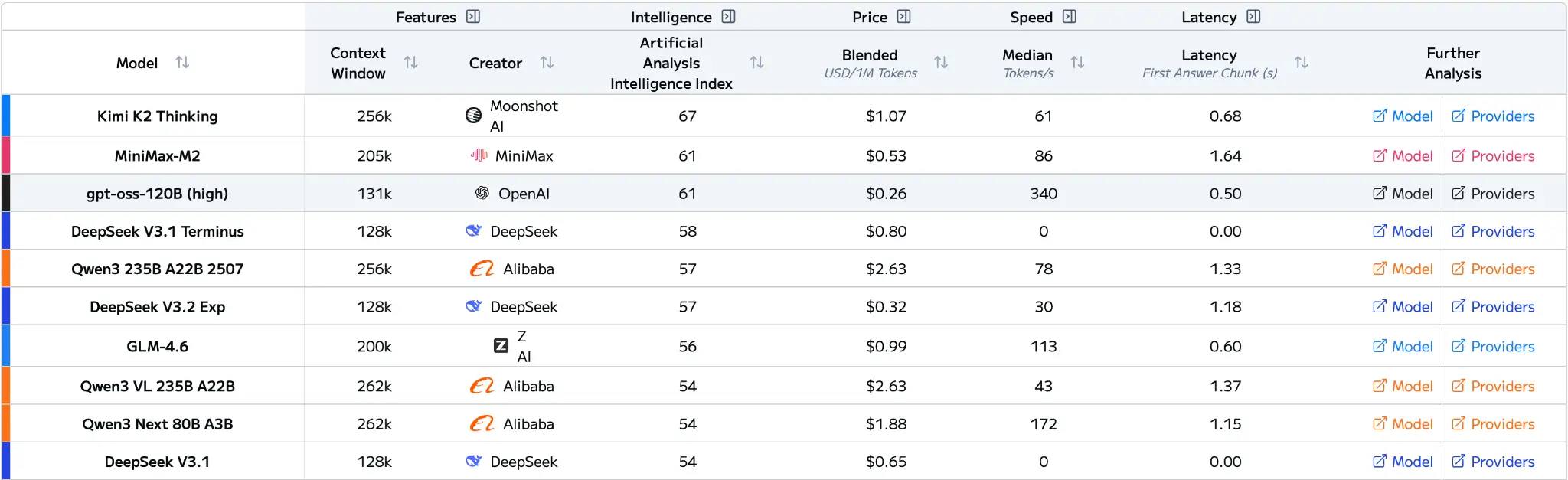
The open ended approach of China’s LLMs clearly paid off, considering that most of the top models that are open-sourced are developed in China.
There isn’t a single winner. Where the West leads in frontier intelligence, China leads in efficiency, scale, and accessible open-source models. When Western labs were closed, China filled the gap and basically took over the innovation loop for affordable and modifiable models. But Western models have an advantage when it comes to performance.
And the race is shifting from “who can build the biggest model?” to “who can deploy AI everywhere?”
A. They were pushed into extreme optimization. Limited access to top Nvidia chips forced them to build smaller, cheaper, highly efficient models instead of brute-forcing scale.
A. Open-sourcing wasn’t charity. It gave them global feedback, boosted adoption, and created an edge where Western labs stayed closed.
A. It depends on the metric. The West still leads in raw capability, but China dominates efficiency, cost, scale, and open-source momentum.
I specialize in reviewing and refining AI-driven research, technical documentation, and content related to emerging AI technologies. My experience spans AI model training, data analysis, and information retrieval, allowing me to craft content that is both technically accurate and accessible.
GPT-4 vs. Llama 3.1 – Which Model is Better?
Llama-3.1-Storm-8B: The 8B LLM Powerhouse Surpa...
A Comprehensive Guide to Building Agentic RAG S...
Top 10 Machine Learning Algorithms in 2026
45 Questions to Test a Data Scientist on Basics...
90+ Python Interview Questions and Answers (202...
8 Easy Ways to Access ChatGPT for Free
Prompt Engineering: Definition, Examples, Tips ...
What is LangChain?
What is Retrieval-Augmented Generation (RAG)?
Edit
Resend OTP
Resend OTP in 45s
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}