 |
VOOZH | about |
|
VOOZH | about |
AI Technical Writer
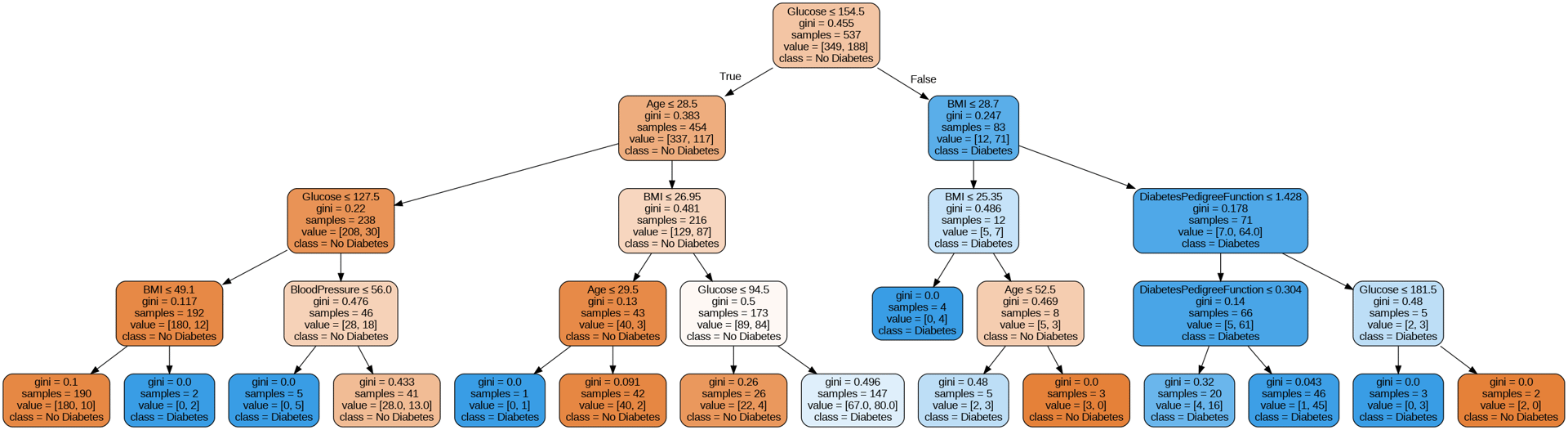
Ever wondered how machines make decisions that feel almost human? A lot of classical machine learning models is based on an algorithm known as Decision Trees. One of the most intuitive yet powerful tools in machine learning. They serve as the foundation for many popular algorithms like Random Forests, Bagging, and Boosted Trees, which are widely used in real-world applications such as fraud detection, medical diagnosis, and customer segmentation.
The concept of decision trees was introduced by Leo Breiman, a renowned statistician at the University of California, Berkeley. He proposed a method where data is represented as a branching tree structure: each internal node tests a specific feature or condition, each branch shows the result of that test, and each leaf node makes a final prediction — either a class label (for classification) or a value (for regression).
In fact, when you hear the term CART (Classification and Regression Trees), it’s just another name for decision trees. In this article, we’ll explain how decision trees work, how they’re constructed, and how to implement them in Python using real-world data. In this article, we’ll cover the following modules:
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
Full documentation for every DigitalOcean product.
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}