 |
VOOZH | about |
|
VOOZH | about |
AI Technical Writer
In today’s world, the use of artificial intelligence and machine learning has become essential in solving real-world problems. Models like large language models or vision models have captured attention due to their remarkable performance and usefulness. If these models are running on a cloud or a big device, this does not create a problem. However, their size and computational demands pose a major challenge when deploying these models on edge devices or for real-time applications.
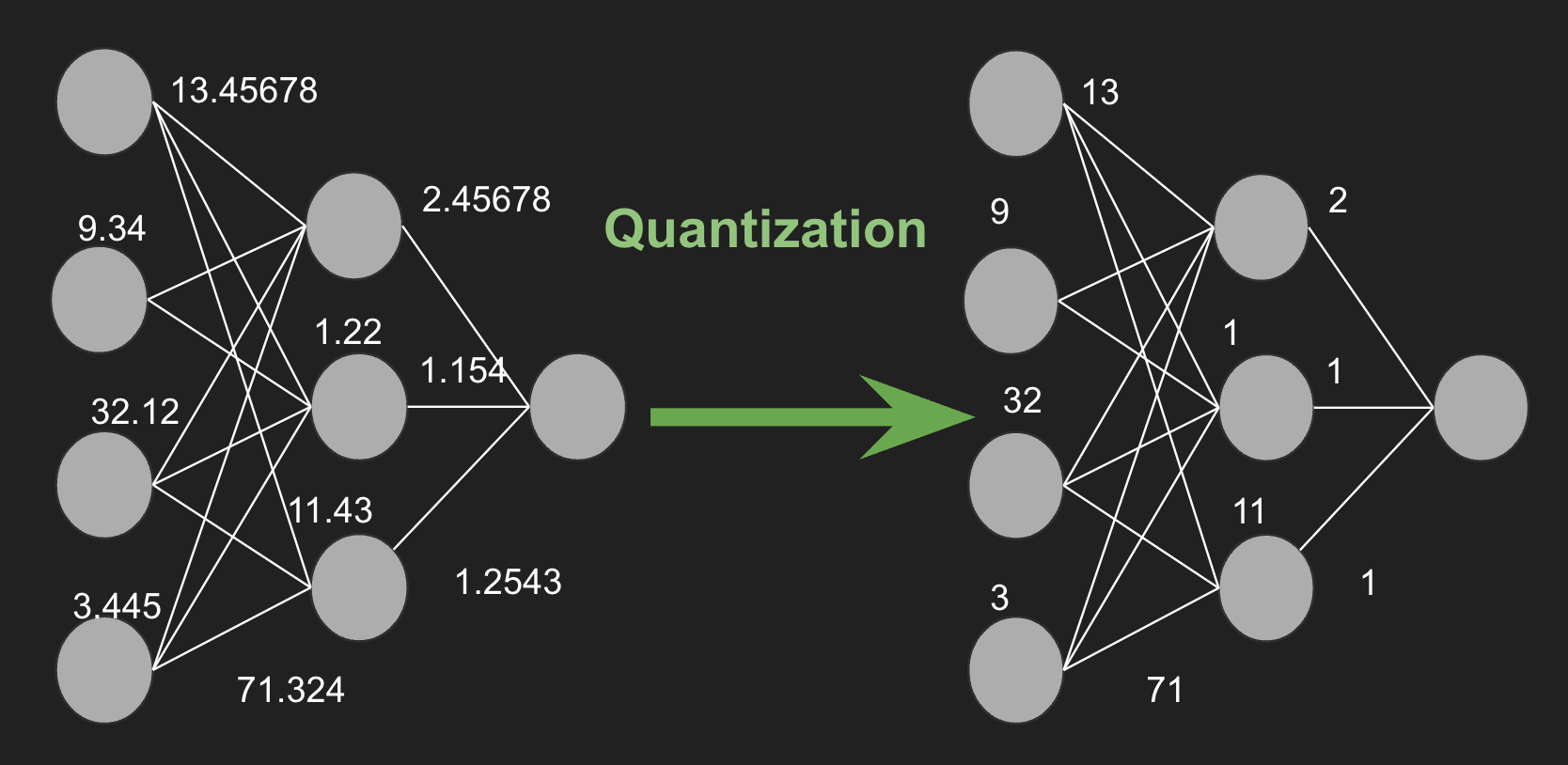
Devices like edge devices, what we call smartwatches or Fitbits, have limited resources, and quantization is a process to convert these large models in a manner that these models can easily be deployed to any small device.
With the advancement in A.I. technology, the model complexity is increasing exponentially. Accommodating these sophisticated models on small devices like smartphones, IoT devices, and edge servers presents a significant challenge. However, quantization is a technique that reduces machine learning models’ size and computational requirements without significantly compromising their performance. Quantization has proven useful in enhancing large language models’ memory and computational efficiency (LLMs). Hence making these powerful models more practical and accessible for everyday use.
Model quantization involves transforming the parameters of a neural network, such as weights and activations, from high-precision (e.g., 32-bit floating point) representations to lower-precision (e.g., 8-bit integer) formats. This reduction in precision can lead to substantial benefits, including decreased memory usage, faster inference times, and reduced energy consumption.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
Full documentation for every DigitalOcean product.
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}