 |
VOOZH | about |
|
VOOZH | about |
AI Technical Writer
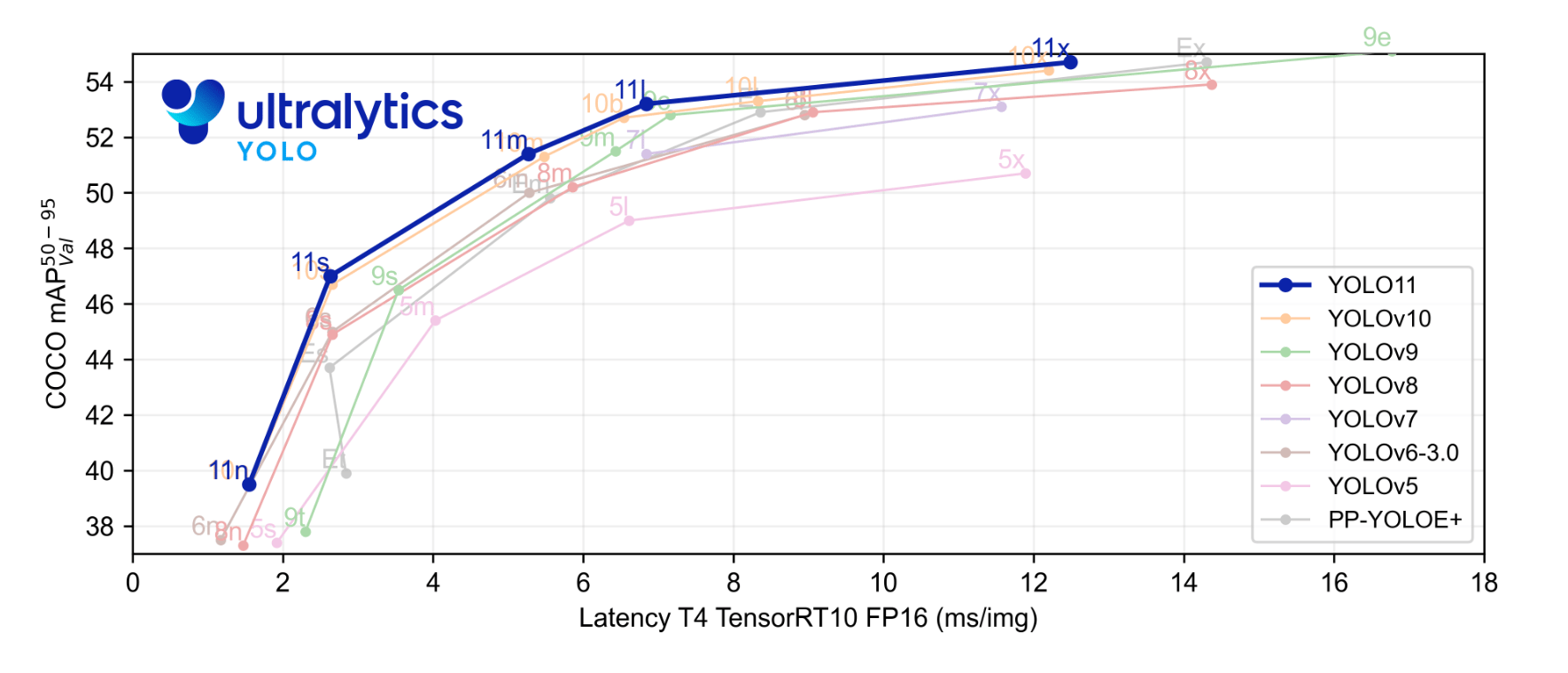
At the YOLO Vision 2024 event, Ultralytics announced a new member to the YOLO series called YOLOv11. This article will provide an overview of the new model, instructions on how to run inference using YOLOv11, and the key advancements and highlights of the model compared to its predecessor. The YOLOv11 model is designed to be fast, accurate, and easy to use for tasks such as object detection, image segmentation, image classification, pose estimation, and real-time object tracking. The new state-of-the-art (SOTA) model has achieved faster inference speed and improved accuracy compared to the previous YOLO models. Before we begin, let’s take a look at the benchmark results provided by Ultralytics. In the benchmark plot, the YOLOv11 model has been compared to YOLOv5, v6, v7, v8, v9, and v10.
The highlighted blue plot is the performance of YOLOv11 and as we can see that it has surpassed pretty much all the yolo model or the series on mean average precision on COCO dataset and on inference speed as plotted on the x-axis.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
Full documentation for every DigitalOcean product.
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}