
Introducing Firecrawl v2.5 - The World's Best Web Data API
{kind=link}
Eric CiarlaOct 30, 2025
{kind=link}
Today, we're excited to announce Firecrawl v2.5, which delivers the highest quality and most comprehensive web data API. This release represents a significant leap forward in web data extraction, powered by two major infrastructure improvements: our new Semantic Index and a completely custom browser stack.
A Custom Browser Stack Built for Quality
To achieve maximum data quality, we built our own browser stack from the ground up. This wasn't a decision we made lightly, but the results speak for themselves.
Our custom browser stack automatically detects how each page is rendered, allowing us to extract data at high speeds while maintaining an exceptionally high quality bar. The browser fleet is designed to handle any content type (PDFs, paginated tables, dynamic JavaScript applications) and convert them into clean, agent-ready formats that work seamlessly with AI systems.
This architecture enables us to index complete pages rather than partial content, which is critical for maintaining data integrity. The impact on quality is substantial, as demonstrated in our benchmarks against leading competitors:
👁 Firecrawl v2.5 Quality Benchmarks
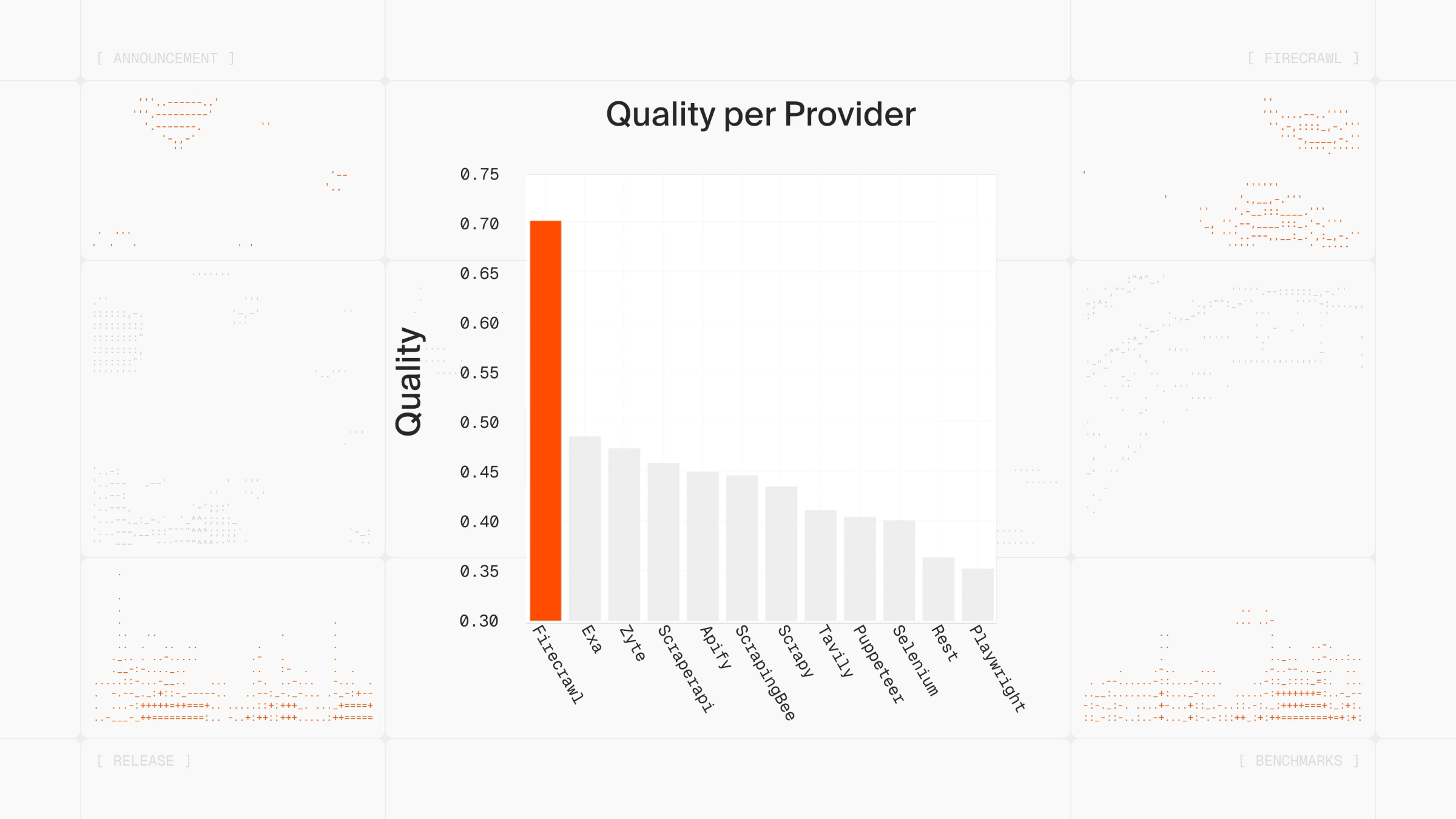{kind=link}
Introducing Our Semantic Index
Alongside our custom browser stack, we've built a semantic index that fundamentally improves both coverage and speed. This index already serves 40% of all API calls, enabling us to deliver top-tier data quickly across most websites.
The semantic index contains previously captured full page snapshots, embeddings, and structural metadata. This allows us to offer a unique capability: users can request data "as of now" or "as of last known good copy," effectively providing access to any previous or current state of the web at any moment. You can control this behavior using the maxAge parameter, which lets you specify how recent the data should be.
This dual-mode approach ensures both reliability and freshness, giving developers the flexibility to choose the right data retrieval strategy for their use case. Our coverage benchmarks demonstrate the effectiveness of this approach:
👁 Firecrawl v2.5 Coverage Benchmarks
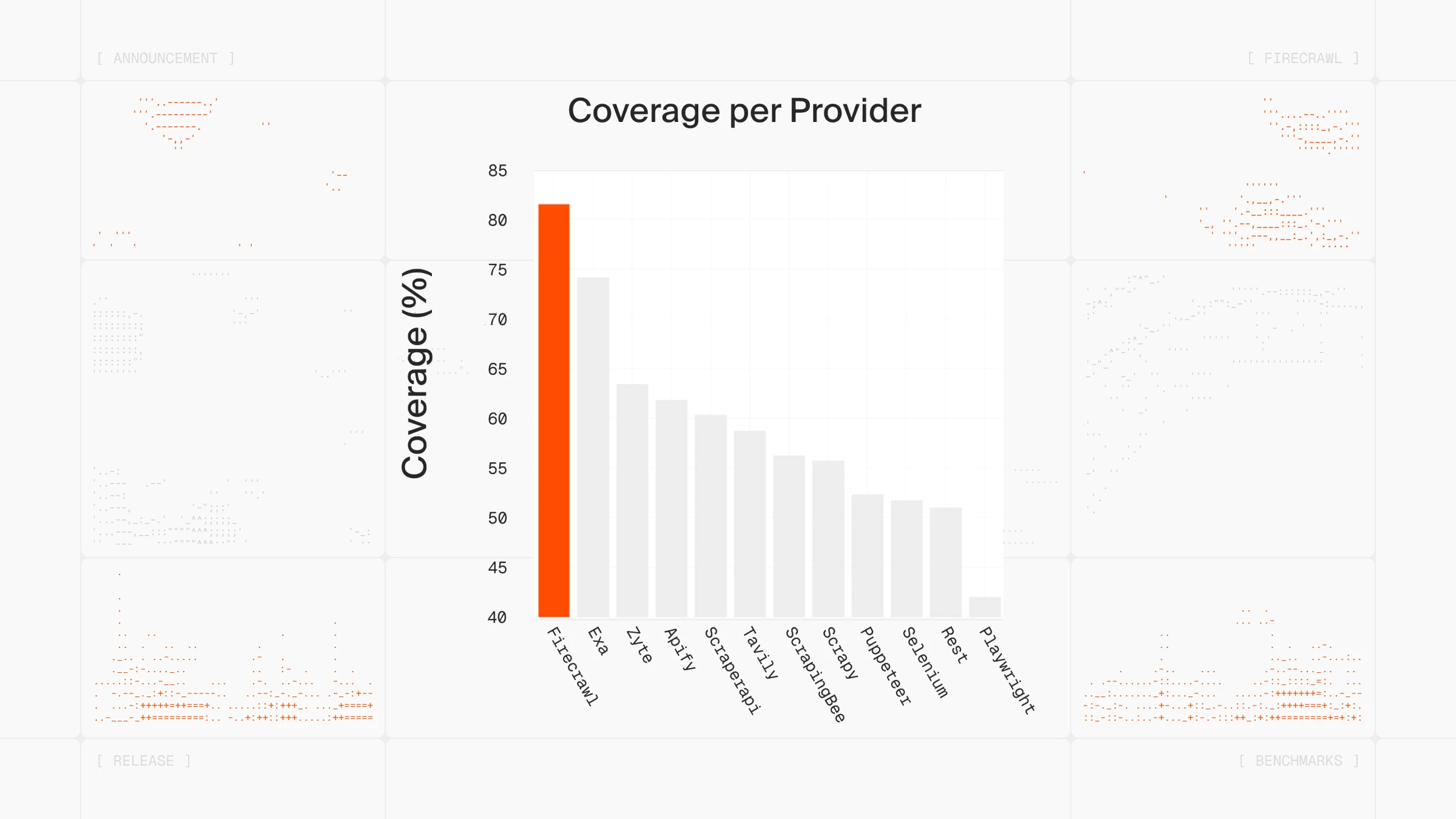{kind=link}
Building the Future of Web Data
Firecrawl v2.5 represents another step toward our larger vision: building a new programmatic layer for the internet. We're creating a web data interface specifically designed for AI agents and modern applications, where accessing web content is as simple and reliable as calling any other API.
We're also committed to transparency and community contribution. In the coming weeks, we'll be open sourcing our web data retrieval benchmarks, allowing the broader developer community to validate and build upon our work.
If you're passionate about this mission and want to help shape the future of web data infrastructure, we're actively hiring. Visit our careers page to learn more about open positions.
Get Started with Firecrawl v2.5
Firecrawl v2.5 is available now for all users - no code changes required. You can start experiencing the improved quality and coverage today:
- Experiment in our interactive playground
- Review the complete documentation
- Sign up to integrate Firecrawl into your applications
We're excited to see what you build with the world's most reliable web data API.
-- Eric and the Firecrawl team
{kind=link}