Shortest job first (SJF) or shortest job next, is a scheduling policy that selects the waiting process with the smallest execution time to execute next. SJN is a non-preemptive algorithm.
- Shortest Job first has the advantage of having a minimum average waiting time among all scheduling algorithms.
- It is a Greedy Algorithm.
- It may cause starvation if shorter processes keep coming. This problem can be solved using the concept of ageing.
- It is practically infeasible as Operating System may not know burst time and therefore may not sort them. While it is not possible to predict execution time, several methods can be used to estimate the execution time for a job, such as a weighted average of previous execution times. SJF can be used in specialized environments where accurate estimates of running time are available.
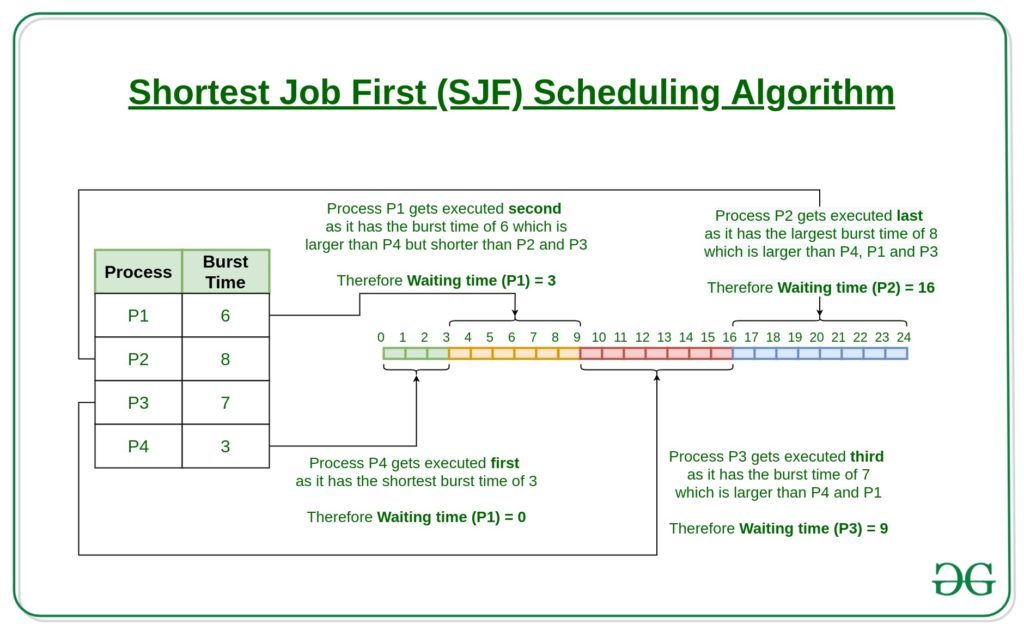
For example:
👁 Image
In the above example, since the arrival time of all the processes is 0, the execution order of the process is the ascending order of the burst time of the processes. The burst time is given by the column duration. Therefore, the execution order of the processes is given by:
P4 -> P1 -> P3 -> P2
One implementation for this algorithm has already been discussed in the article with the help of Naive Approach. In this article, the algorithm is implemented by using the concept of a segment tree.
Approach: The following is the approach used for the implementation of the shortest job first:
- As the name suggests, the shortest job first algorithm is an algorithm which executes the process whose burst time is least and has arrived before the current time. Therefore, in order to find the process which needs to be executed, sort all the processes from the given set of processes according to their arrival time. This ensures that the process with the shortest burst time which has arrived first is executed first.
- Instead of finding the minimum burst time process among all the arrived processes by iterating the
whole struct array, the range minimum of the burst time of all the arrived processes upto the current time is calculated using segment tree. - After selecting a process which needs to be executed, the completion time, turn around time and waiting time is calculated by using arrival time and burst time of the process. The formulae to calculate the respective times are:
- Completion Time: Time at which process completes its execution.
Completion Time = Start Time + Burst Time
- Turn Around Time: Time Difference between completion time and arrival time.
Turn Around Time = Completion Time – Arrival Time
- Waiting Time(W.T): Time Difference between turn around time and burst time.
Waiting Time = Turn Around Time – Burst Time
- After calculating, the respective times are updated in the array and the burst time of the executed process is set to infinity in the segment tree base array so that it is not considered as the minimum burst time in the further queries.
Below is the implementation of the shortest job first using the concept of segment tree:
OutputProcessId Arrival Time Burst Time Completion Time Turn Around Time Waiting Time
1 1 7 8 7 0
2 2 5 16 14 9
3 3 1 9 6 5
4 4 2 11 7 5
5 5 8 24 19 11
Time Complexity: In order to analyze the running time of the above algorithm, the following running times needs to be understood first:
- The time complexity to construct a segment tree for N processes is O(N).
- The time complexity to update a node in a segment tree is given by O(log(N)).
- The time complexity to perform a range minimum query in a segment tree is given by O(log(N)).
- Since the update operation and queries are performed for given N processes, the total time complexity of the algorithm is O(N*log(N)) where N is the number of processes.
- This algorithm performs better than the approach mentioned in this article because it takes O(N2) for execution.
Space Complexity: O(100000)

{kind=link}
{kind=link}