
When we run certain commands in Linux to read or edit text from a string or file, we often try to filter the output to a specific section of interest. This is where using regular expressions comes in handy.
Please refer to our previous tutorials in the Awk series:
- How to Filter Text or String Using Awk and Regular Expressions – Part 1
- How to Use Awk to Print Fields and Columns in File – Part 2
- How to Use Awk to Filter Text Using Pattern Specific Actions – Part 3
- How to Use Comparison Operators with Awk in Linux – Part 4
- How to Use Compound Expressions with Awk in Linux – Part 5
- How to Use ‘next’ Command with Awk in Linux – Part 6
- How to Read Awk Input from STDIN in Linux – Part 7
- How to Use Awk Variables, Numeric, and Assignment Operators – Part 8
- How to Use Awk Special Patterns ‘BEGIN and END’ – Part 9
- How to Use Awk Built-in Variables in Linux – Part 10
- How to Allow Awk to Use Shell Variables in Linux – Part 11
- How to Use Flow Control Statements in Awk – Part 12
- How to Write Scripts Using Awk Programming Language – Part 13
What are Regular Expressions?
A regular expression can be defined as strings that represent several sequences of characters. One of the most important things about regular expressions is that they allow you to filter the output of a command or file, edit a section of a text or configuration file, and so on.
Features of Regular Expression
Regular expressions are made of:
- Ordinary characters such as space, underscore(_), A-Z, a-z, 0-9.
- Meta characters that are expanded to ordinary characters, include:
(.)it matches any single character except a newline.(*)it matches zero or more existences of the immediate character preceding it.[ character(s) ]it matches any one of the characters specified in character(s), one can also use a hyphen(-)to mean a range of characters such as[a-f],[1-5], and so on.^it matches the beginning of a line in a file.$matches the end of the line in a file.\it is an escape character.
In order to filter text, one has to use a text filtering tool such as awk. You can think of awk as a programming language of its own. But for the scope of this guide to using awk, we shall cover it as a simple command line filtering tool.
The general syntax of awk is:
awk 'script' filename
Where 'script' is a set of commands that are understood by awk and are executed on file, filename.
It works by reading a given line in the file, making a copy of the line, and then executing the script on the line. This is repeated on all the lines in the file.
The 'script' is in the form '/pattern/ action' where the pattern is a regular expression and the action is what awk will do when it finds the given pattern in a line.
How to Use Awk Filtering Tool in Linux
In the following examples, we shall focus on the meta characters that we discussed above under the features of awk.
Printing All Lines from File Using Awk
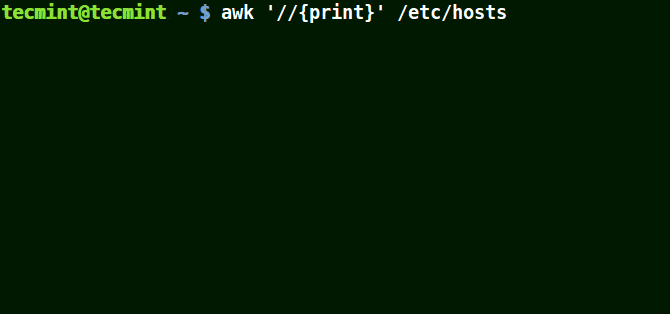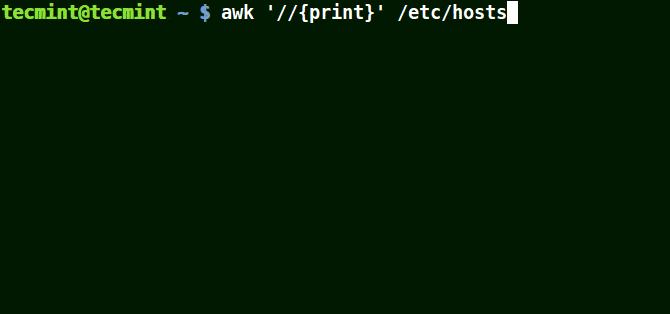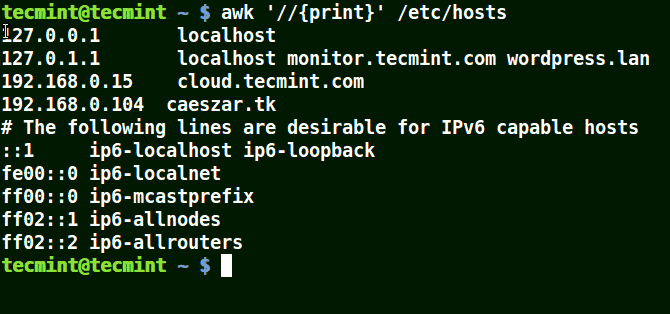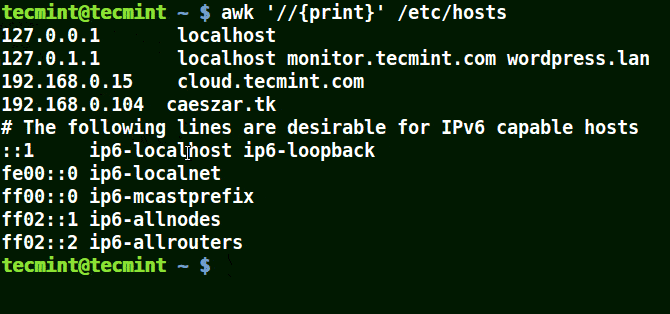
The example below prints all the lines in the file /etc/hosts since no pattern is given.
awk '//{print}'/etc/hosts
{kind=link}
Use Awk Patterns: Matching Lines with ‘localhost’ in File
In the example below, a pattern localhost has been given, so awk will match the line having localhost in the /etc/hosts file.
awk '/localhost/{print}' /etc/hosts
{kind=link}
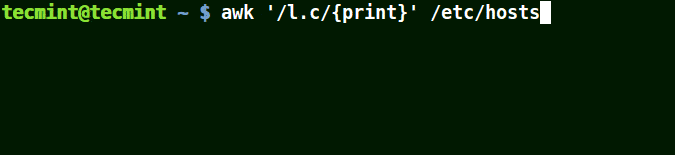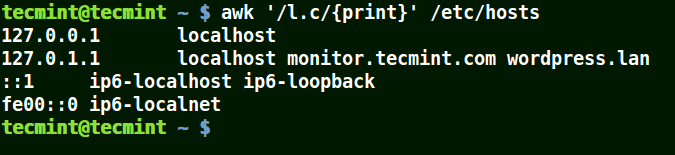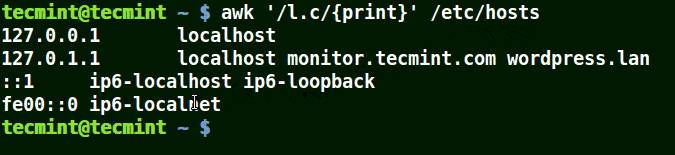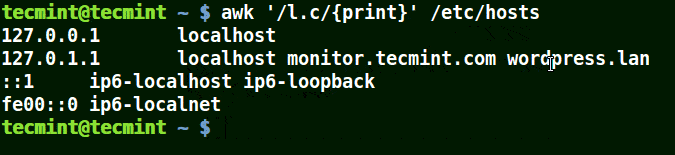
Using Awk with (.) Wildcard in a Pattern
The (.) will match strings containing loc, localhost, localnet in the example below.
That is to say * l some_single_character c *.
awk '/l.c/{print}' /etc/hosts
{kind=link}
Using Awk with (*) Character in a Pattern
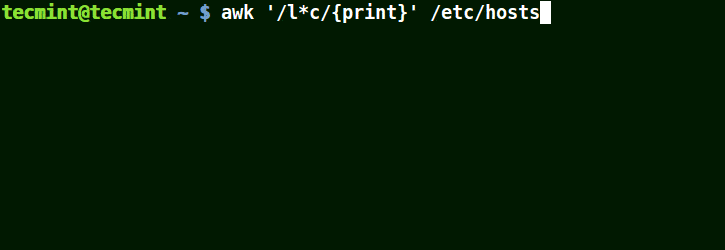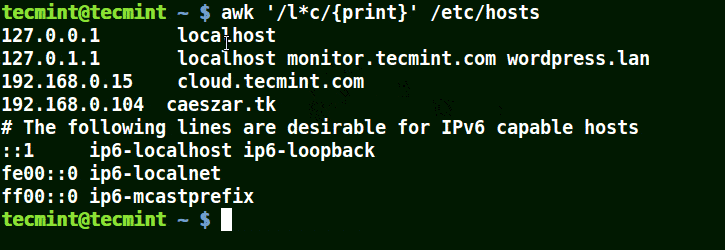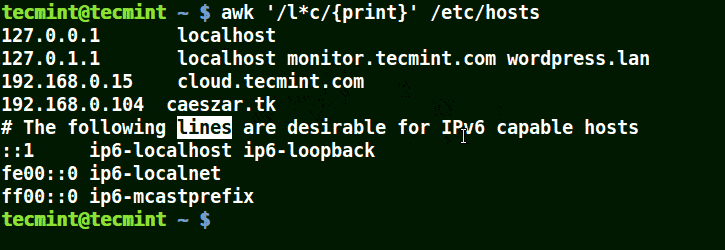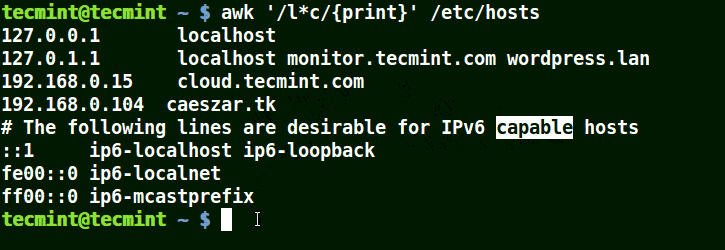
It will match strings containing localhost, localnet, lines, capable, as in the example below:
awk '/l*c/{print}' /etc/localhost
{kind=link}
You will also realize that (*) tries to get you the longest match possible it can detect.
Let’s look at a case that demonstrates this, take the regular expression t*t which means matching strings that start with the letter t and end with t in the line below:
this is tecmint, where you get the best good tutorials, how to's, guides, tecmint.
You will get the following possibilities when you use the pattern /t*t/:
this is t this is tecmint this is tecmint, where you get t this is tecmint, where you get the best good t this is tecmint, where you get the best good tutorials, how t this is tecmint, where you get the best good tutorials, how tos, guides, t this is tecmint, where you get the best good tutorials, how tos, guides, tecmint
And (*) in /t*t/ wild card character allows awk to choose the last option:
this is tecmint, where you get the best good tutorials, how to's, guides, tecmint
Using Awk with set [ character(s) ]
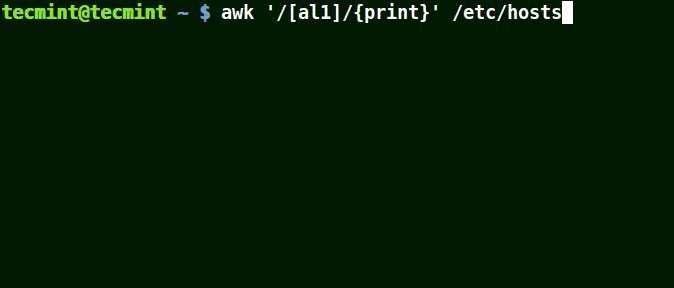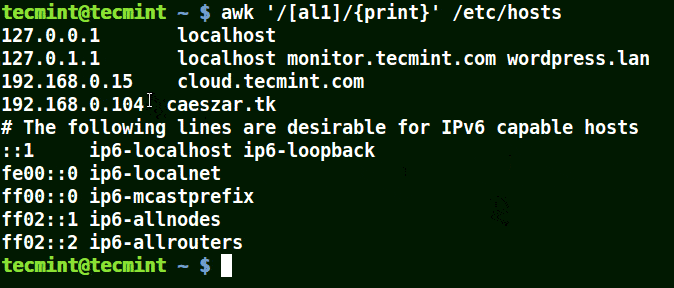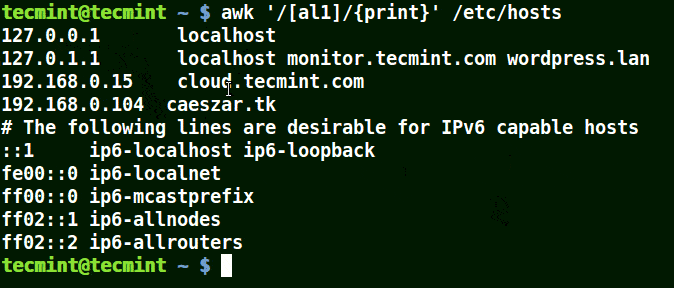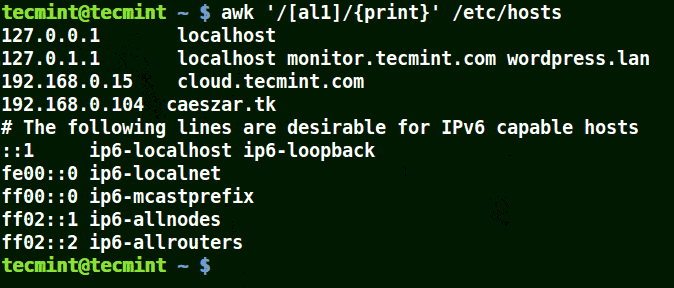
Take for example the set [al1], here awk will match all strings containing character a or l or 1 in a line in the file /etc/hosts.
awk '/[al1]/{print}' /etc/hosts
{kind=link}
The next example matches strings starting with either K or k followed by T:
# awk '/[Kk]T/{print}' /etc/hosts
{kind=link}
Specifying Characters in a Range
Understand characters with awk:
[0-9]means a single number[a-z]means match a single lowercase letter[A-Z]means match a single upper-case letter[a-zA-Z]means match a single letter[a-zA-Z 0-9]means match a single letter or number
Let’s look at an example below:
awk '/[0-9]/{print}' /etc/hosts
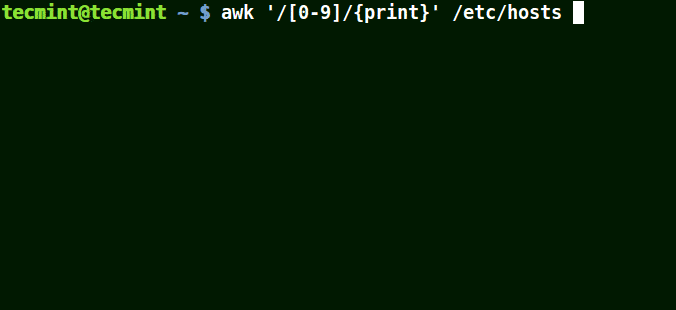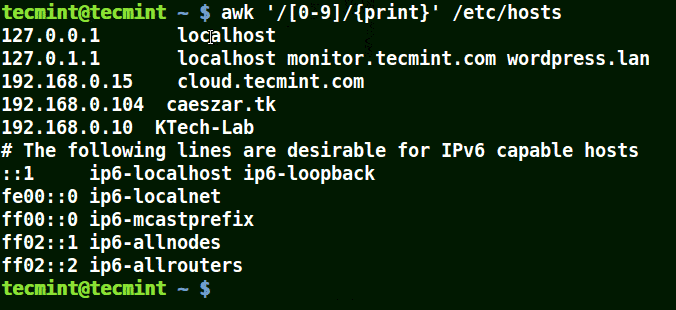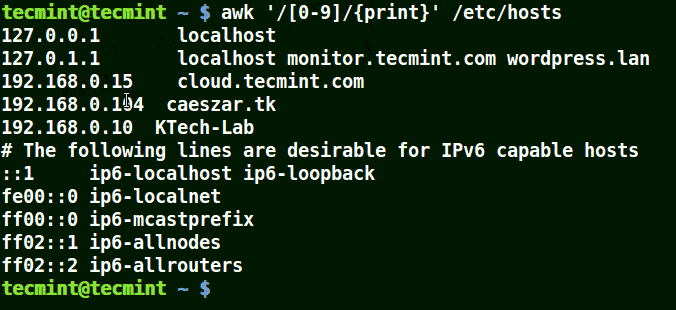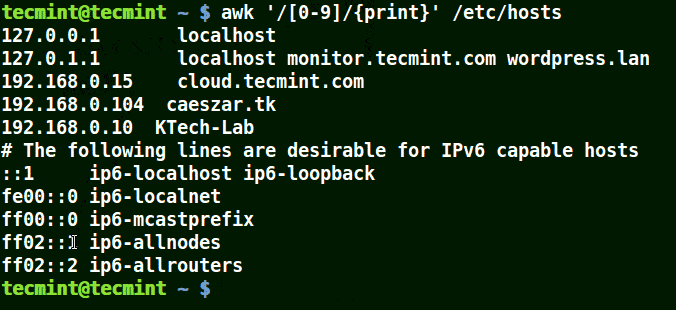{kind=link}
All the line from the file /etc/hosts contain at least a single number [0-9] in the above example.
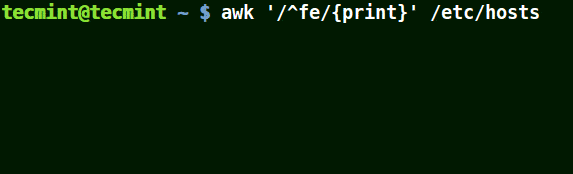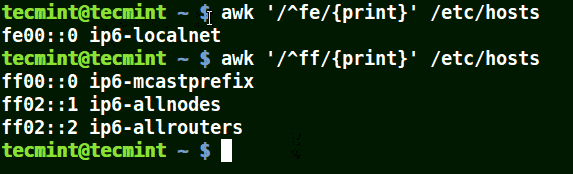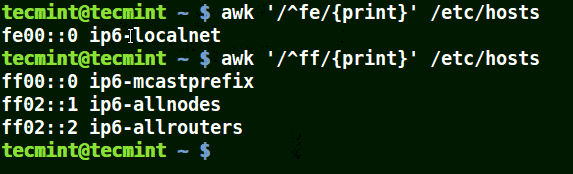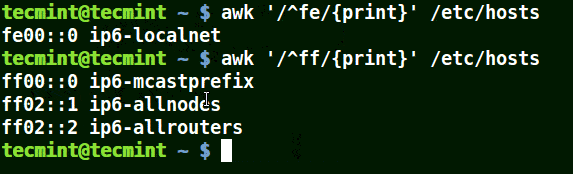
Use Awk with (^) Meta Character
It matches all the lines that start with the pattern provided as in the example below:
# awk '/^fe/{print}' /etc/hosts
# awk '/^ff/{print}' /etc/hosts
{kind=link}
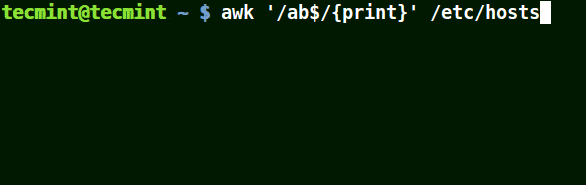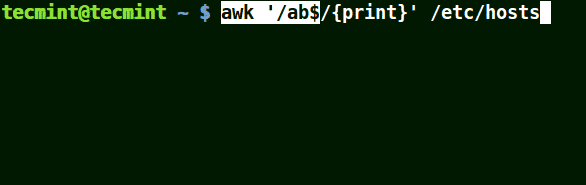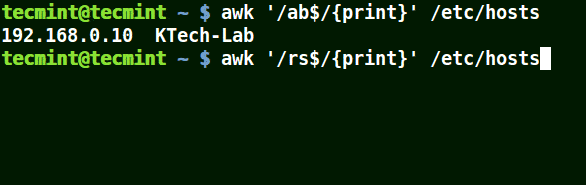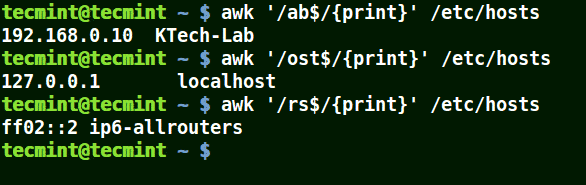
Use Awk with ($) Meta Character
It matches all the lines that end with the pattern provided:
awk '/ab$/{print}' /etc/hosts
awk '/ost$/{print}' /etc/hosts
awk '/rs$/{print}' /etc/hosts
{kind=link}
Use Awk with (\) Escape Character
It allows you to take the character following it as a literal that is to say consider it just as it is.
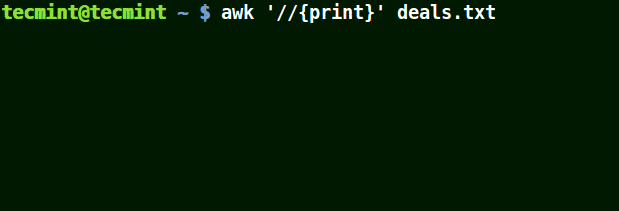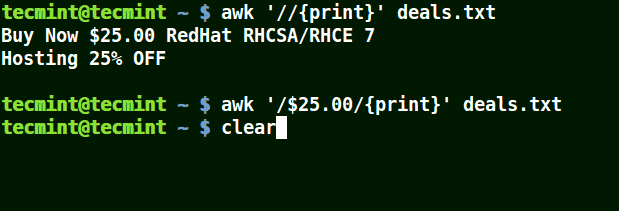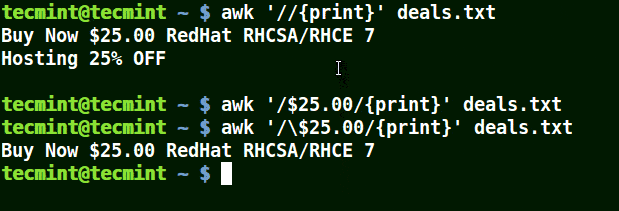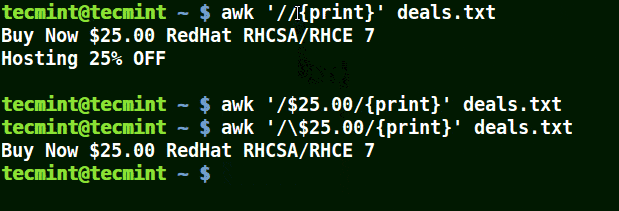
In the example below, the first command prints out all lines in the file, and the second command prints out nothing because I want to match a line that has $25.00, but no escape character is used.
The third command is correct since an escape character has been used to read $ as it is.
awk '//{print}' deals.txt
awk '/$25.00/{print}' deals.txt
awk '/\$25.00/{print}' deals.txt
{kind=link}
Summary
That is not all with the awk command line filtering tool, the examples above a the basic operations of awk. In the next parts, we shall be advancing on how to use complex features of awk.
For those seeking a comprehensive resource, we’ve compiled all the Awk series articles into a book, that includes 13 chapters and spans 41 pages, covering both basic and advanced Awk usage with practical examples.
| Product Name | Price | Buy |
|---|---|---|
| eBook: Introducing the Awk Getting Started Guide for Beginners | $8.99 | [Buy Now] |
Thanks for reading through and for any additions or clarifications, post a comment in the comments section.
If this article helped you solve a problem, consider buying a coffee. It helps keep TecMint free, supports the authors, and keeps the project going.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Got Something to Say? Join the Discussion... Cancel reply