I've spent years pushing the boundaries of pretraining—first as lead author on PaLM, then as a lead contributor on Gemini pre-training. Now I'm at Reflection, building open-weight agentic models at the frontier
from the ground up.
Today we're announcing our Series B to
Today we're sharing the next phase of Reflection.
We're building frontier open intelligence accessible to all.
We've assembled an extraordinary AI team, built a frontier LLM training stack, and raised $2 billion.
Why Open Intelligence Matters
Technological and scientific
Today I’m launching @reflection_ai with my friend and co-founder @real_ioannis.
Our team pioneered major advances in RL and LLMs, including AlphaGo and Gemini.
At Reflection, we're building superintelligent autonomous systems. Starting with autonomous coding.
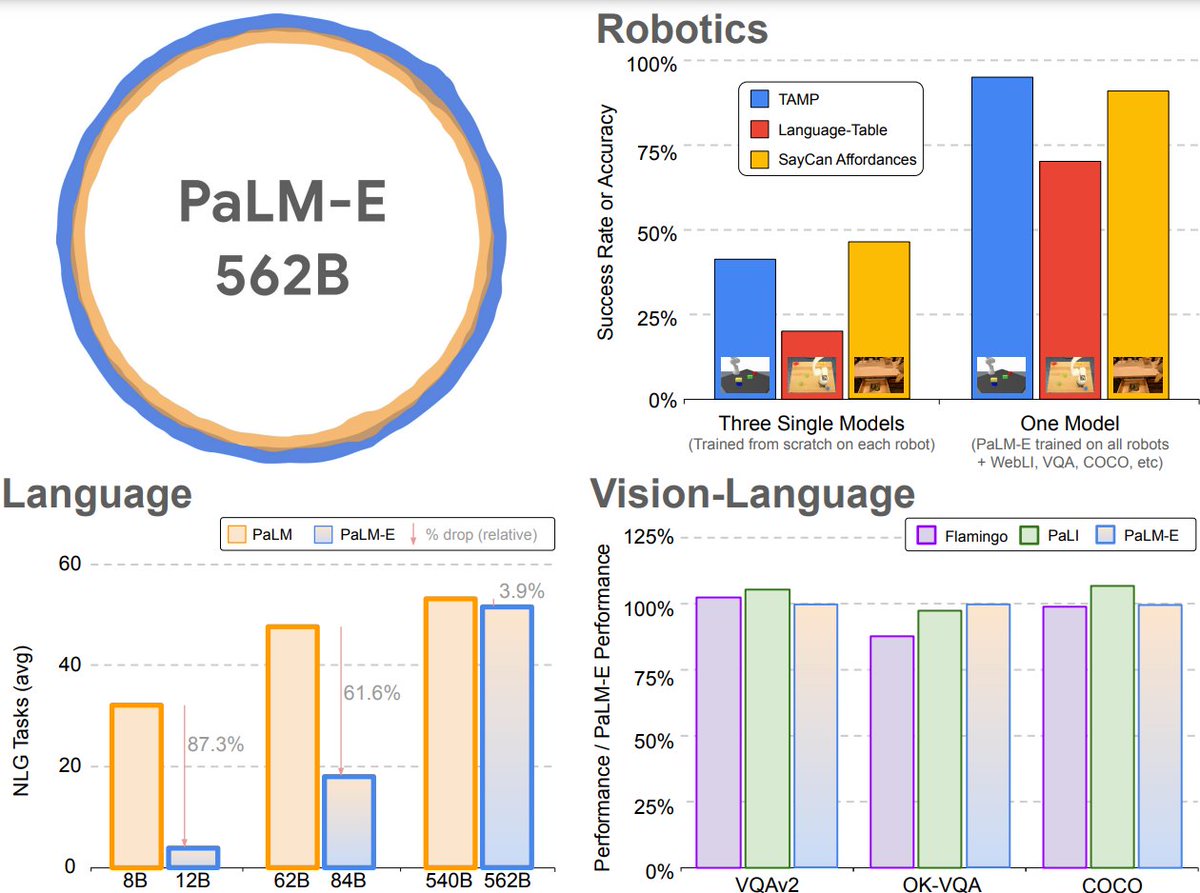
Presenting PaLM-E 562B, one-model generalist across robotics, language, and vision-language. It showcases multimodal chain-of-thought reasoning and the ability to reason over multiple images!
And positive transfer enables it to work well on robots!!!
Check out Danny's thread 👇
What happens when we train the largest vision-language model and add in robot experiences?
The result is PaLM-E 🌴🤖, a 562-billion parameter, general-purpose, embodied visual-language generalist - across robotics, vision, and language.
Website: palm-e.github.io
1/ Reflecting back on 2022: we shared our most advanced language model PaLM - a single 540B-parameter dense language model for multiple domains & tasks, trained over two TPUv4 Pods.
Research paper: goo.gle/palm-paper
Blog post:
Introducing the 540 billion parameter Pathways Language Model. Trained on two Cloud #TPU v4 pods, it achieves state-of-the-art performance on benchmarks and shows exciting capabilities like mathematical reasoning, code writing, and even explaining jokes. goo.gle/3j6eMnK
Large language models have been shown to achieve remarkable performance across a variety of natural language tasks using few-shot learning, which drastically reduces the number of task-specific...
Today we launch Asimov.
Asimov is our code research agent that is best-in-class in codebase comprehension.
It is built for teams, built for enterprises, and built to remember.
We use it everyday to accelerate our velocity and streamline distributed ops.
Link below to sign up
This quarter, Stanford’s Advances in Foundation Models Class (CS 324) will be partnering with the Stanford MLSys Seminar to host a special talk series on foundation models!
Our first talk will be @tri_dao. Catch us *TOMORROW* at 3:30 PT: youtube.com/watch?v=gMOAud…
Introducing the 540 billion parameter Pathways Language Model. Trained on two Cloud #TPU v4 pods, it achieves state-of-the-art performance on benchmarks and shows exciting capabilities like mathematical reasoning, code writing, and even explaining jokes. goo.gle/3j6eMnK
#palm But how long did it need to train? Training PaLM 62B to 1.3 trillion tokens results in significant gains as suggested by Chinchilla data scaling. However it does not bridge the gap to PaLM 540B that 5x training FLOP count.
See updated results in: arxiv.org/pdf/2204.02311…
Incredibly fun and interesting panel discussion with Percy Liang (@percyliang) and Angela Fan! Thank you so much to Sasha (@srush_nlp) for the amazing work at organizing and moderating this panel!
Very cool open-source work from @PyTorch on reinforcement learning environments (we helped a tiny bit)!
Feels like early days on the topic with already exciting work from @PrimeIntellect@MechanizeWork@mercor_ai for example but exciting to make this topic as open-source and
Super excited about discussing Gemini and LLM related advances from Google at the Beyond Scaling Panel tomorrow afternoon at NeurIPS, jointly with Sasha Rush (@srush_nlp) , Angela Fan, Percy Liang (@percyliang), and Jie Tang (@jietang).
{kind=link}
{kind=link}

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}