
Simple Regularized Lasso Regression
L1 Regularization
{kind=link}
Introduction
When we observe high variance in the test data from the model that we fit using the training data, we understand that some bias is required to be introduced in the model. Otherwise, it will consistently generate high variance in the long run and thus, be considered as a weak model. One of the several ways to do that is lasso regression. Lasso regression is very similar to ridge regression but is has also a very important difference. The reader can check the article on ridge regression since I am going to use the same example for implementation of lasso regression.
Simple Regularized Linear and Polynomial Regression
Ridge vs Lasso
Let’s first talk about the simple linear regression. In this case, we try to minimize the square of the residuals which results in a line that generates the minimum sum of squared errors. An example of linear fit is shown below. This is a synthetic dataset created from the following dictionary.
The mean squared error in the following example is 0.055 which is the smallest among all other possible lines.
![👁 Training data with linear fit [Image by Author]](https://towardsdatascience.com/wp-content/uploads/2022/04/1yoQTpUkxA6A4J8fYgyp9ow.png){kind=link}
In ridge regression, we introduce a small bias at the cost of variance in training data but it reduces long term variance in the test data which is a typical scenario for bias-variance tradeoff. The core of ridge regression is to minimize the sum of squared residual as well as lambda times the square of the slope. However, in lasso the goal is same but the procedure is different. Here, the term to be minimized is the sum of squared residual plus lambda times absolute value of the slope. That’s it. that is the core difference. The term to be minimized in these regression models are summarized below. Of course, the term lambda can be determined by cross validation and take the best for the given dataset.
{kind=link}
Lasso in action
Let’s use the same dataset which was used to demonstrate ridge regression for the sake of comparison. The blue dots are training data and red dots are test data. The test dataset is also a synthetic dataset created from the following dictionary.
![👁 Training (blue) and test (red) data [Image by Author]](https://towardsdatascience.com/wp-content/uploads/2022/04/1gjgga6p1QtAHEKWgjmktJg.png){kind=link}
The mean squared error on test data in the above example when lasso regression is implemented and the model is fit on training data is 5.41 which is slightly smaller than that of ridge case where we obtained the value of 6.88 as mean squared error and also obviously smaller than simple linear regression result which ends up with 8.41 as mean squared error. Again, it is also true that higher the alpha value, the lesser the influence of the independent variable on the regression model. Which basically means that as we increase alpha value, the coefficient of the model approaches zero. It will be completely horizonal for very high alpha values leaving zero dependency on the independent variable. Therefore, optimization is required to determine the alpha value by cross validation.
{kind=link}
We can choose the value of alphas randomly from very low to very high. Here, we have swept alpha values for a specific dataset and determined the MSE (mean squared error) value in each case. The smallest MSE was for alpha =0.1 and then same result is obtained when LassoCV is utilized.
Conclusion
Both ridge and lasso regression are extremely useful tools to effectively remove overfitting on training dataset. Both approach punish the model coefficient and try to minimize the sum of squared error plus the penalty term. Only this penalty term varies between ridge and lasso approaches. As we dig deeper into the regression analysis for higher dimensions, we will see that when there are lots of unnecessary independent variables, ridge approach can reduce the coefficients of unnecessary variables whereas lasso can effectively make them zero and thus completely eliminating their effect on the result.
Share This Article
Towards Data Science is a community publication. Submit your insights to reach our global audience and earn through the TDS Author Payment Program.
Write for TDS{kind=link}
{kind=link}
{kind=link}
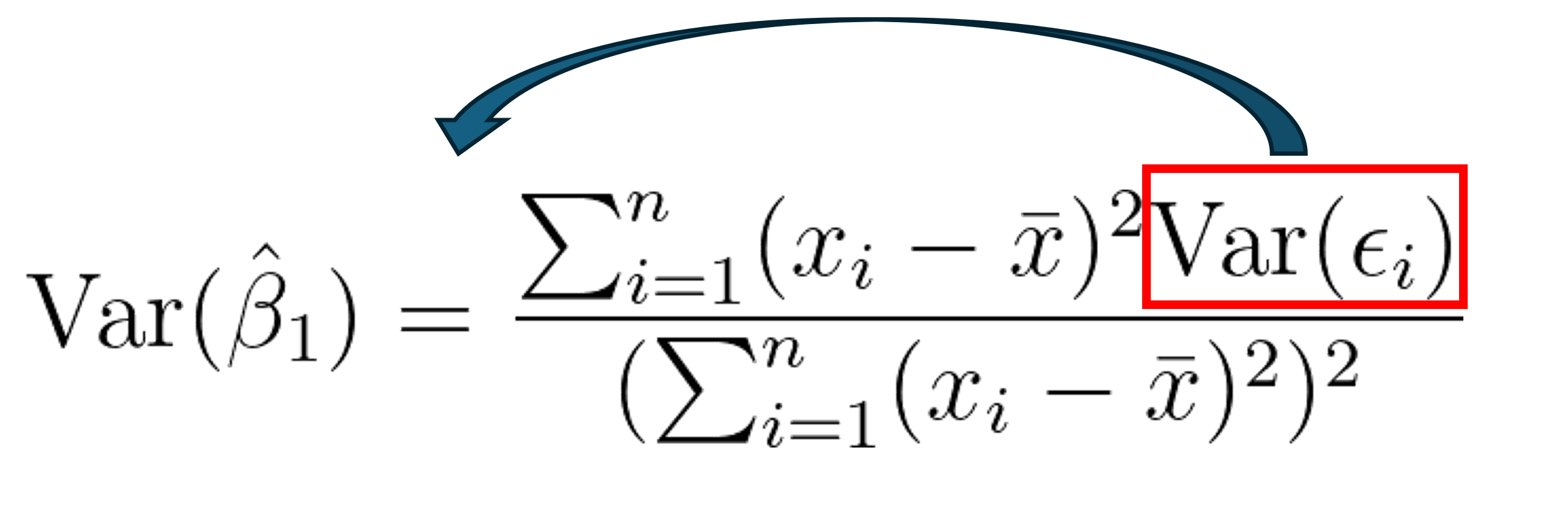{kind=link}
{kind=link}
{kind=link}