
What is AA-Briefcase? The AI benchmark for real knowledge work, explained
{kind=link}
{kind=link}
Last edited June 23, 2026
{kind=link}
What AA-Briefcase actually measures
Most AI benchmarks ask short, self-contained questions: a math problem, a coding puzzle, a multiple-choice quiz. That's fine for measuring raw reasoning, but it's nothing like how people actually use these models at work. Real knowledge work is long, ambiguous, and buried in mess.
AA-Briefcase was built to close that gap. Instead of a prompt, each model is dropped into a multi-week business project with many linked tasks and thousands of source files, and asked to produce the kind of deliverables a real analyst or PM would: financial models, board presentations, design mock-ups, strategy memos. The scenarios were developed over months by industry experts from companies including Google, McKinsey and Boston Consulting Group, so the work resembles what those firms actually do.
The numbers give a sense of the scale. There are four held-out project scenarios and 91 tasks in total, drawn from data science, product management, and corporate strategy. Across them sit nearly 2,000 source files, including more than 3,500 emails and 25,000 Slack messages, deliberately fragmented and full of realistic contradictions. The four scoring scenarios are a Data Science project, a Product Management project, a Banking Operations transformation, and a Heavy Industry Strategy build; a fifth Due Diligence scenario is public and doesn't count toward scores.
That framing matters because it mirrors the failure mode of every AI agent I've ever shipped: the model rarely struggles with the idea, it struggles with finding the one requirement hidden in file 1,400 and not contradicting the email that quietly overrode it.
How AA-Briefcase grades a model
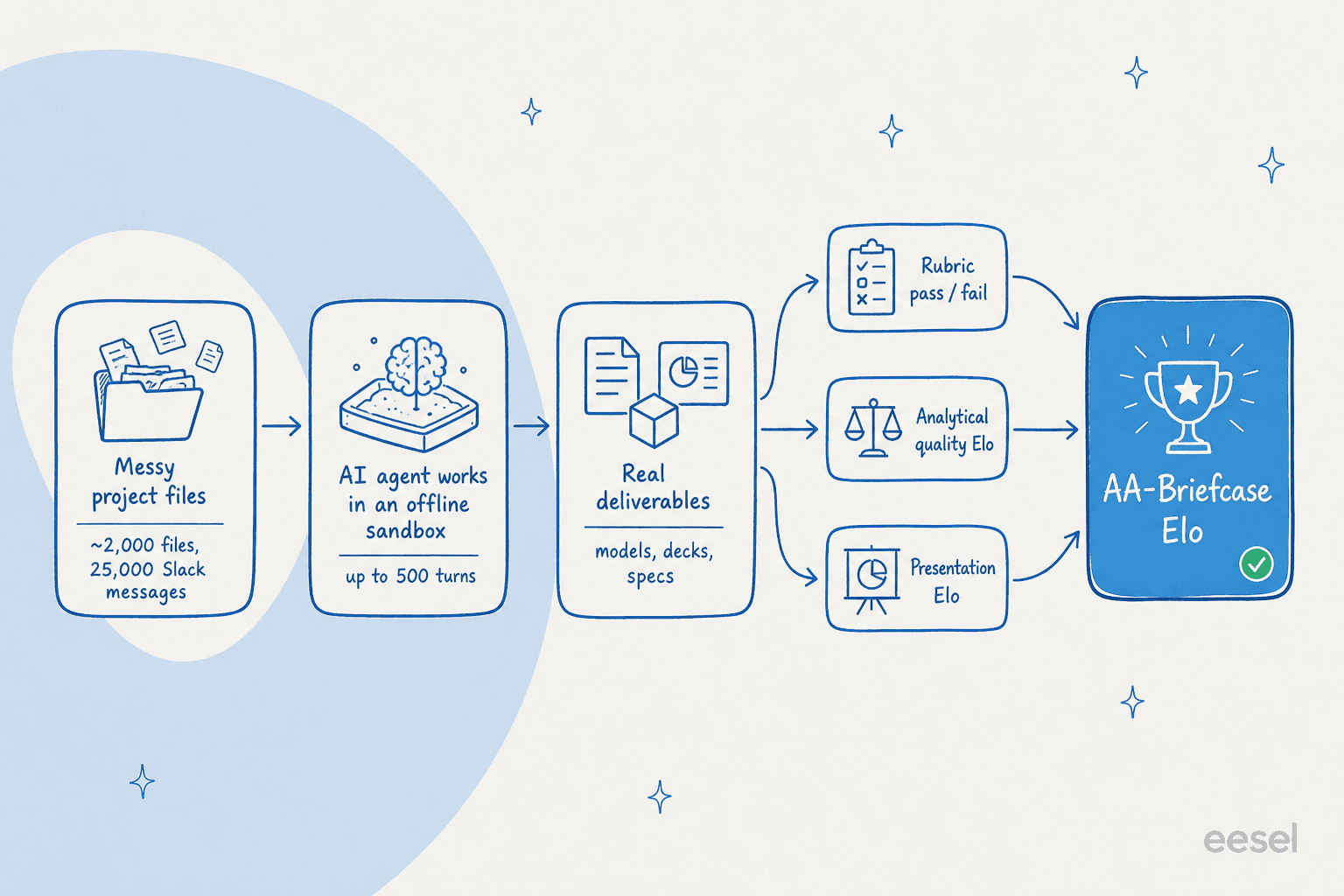
Here's where AA-Briefcase gets clever. A single score would hide the most interesting thing about AI output, which is that looking professional and being correct are two completely different skills. So every task is graded on three separate dimensions.
{kind=link}
The first is a binary rubric: pass or fail on each check, no partial credit. Did the model follow instructions, dig out requirements scattered across files, use the right evidence, and reach the correct conclusion? The second is analytical quality, judged by pairwise comparison against another model's submission: which deliverable is more thorough and better supported? The third is presentation, also pairwise: which output is more professionally put together?
Those three feed into one headline number, the AA-Briefcase Elo, which blends analytical-quality Elo, presentation Elo, and rubric pass rate using maximum-likelihood Elo aggregation. To keep any one model family from grading itself favourably, every comparison is decided by a panel of three judges: Claude Opus 4.8, GPT-5.5, and Gemini 3.1 Pro Preview.
The plumbing is open too. Models run on Stirrup, Artificial Analysis' open-source agent harness, inside an offline sandbox with no internet, for up to 500 turns per task. It's a genuinely demanding setup, and it's a fair bit closer to a real agentic workflow than a chat window is.
What the results actually say
The leaderboard up top tells the happy story (Claude Fable 5 in front, capability tiers neatly stacked). The harder story is in the pass rates.
{kind=link}
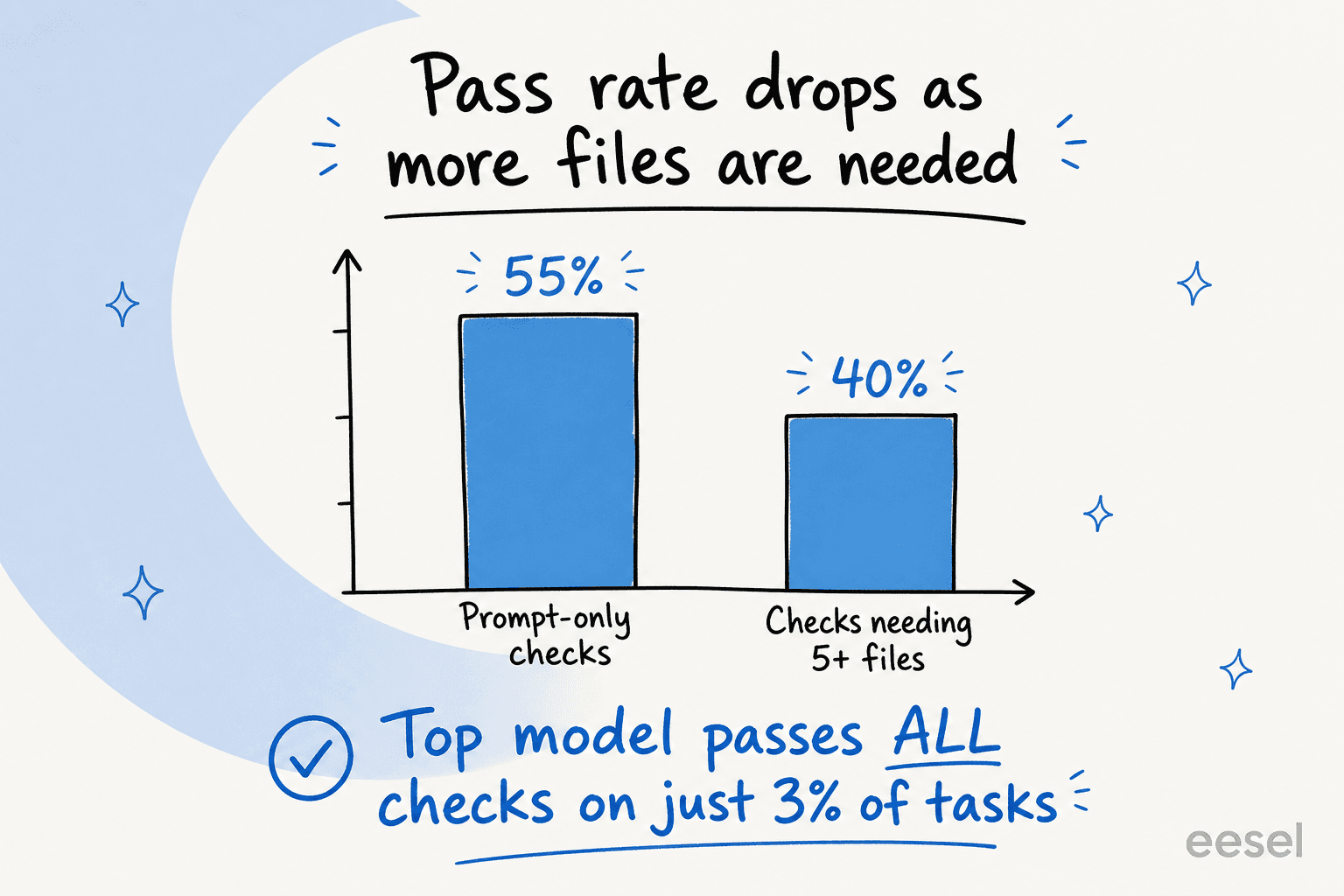
Even the leading model satisfies all rubric criteria on just 3% of tasks, and on 31 of the 91 tasks no model scores above 50%. Difficulty also scales with the number of required files: high-intelligence models drop from around 55% on prompt-only checks to about 40% once a task needs five or more. The more a task looks like real work, the worse everyone does.
The leaderboard has a few takeaways worth pulling out. GLM-5.2 is the clear open-weight leader and the price/performance standout, landing roughly 90 Elo below Claude Opus 4.8 for less than a quarter of the cost. MiniMax-M3 and GLM-5.2 both overperform relative to their general intelligence scores, while Google's Gemini models actually underperform on AA-Briefcase compared to where they sit on broad intelligence rankings. And as the cost view in the widget shows, the spread between the priciest and cheapest model runs over 800×, which is a useful reminder when you're weighing the real cost of an AI agent against the metrics that actually move.
The "looks right but is wrong" problem
My favourite finding in the whole release is a behavioural one, and it explains a lot about why AI work can feel untrustworthy.
{kind=link}
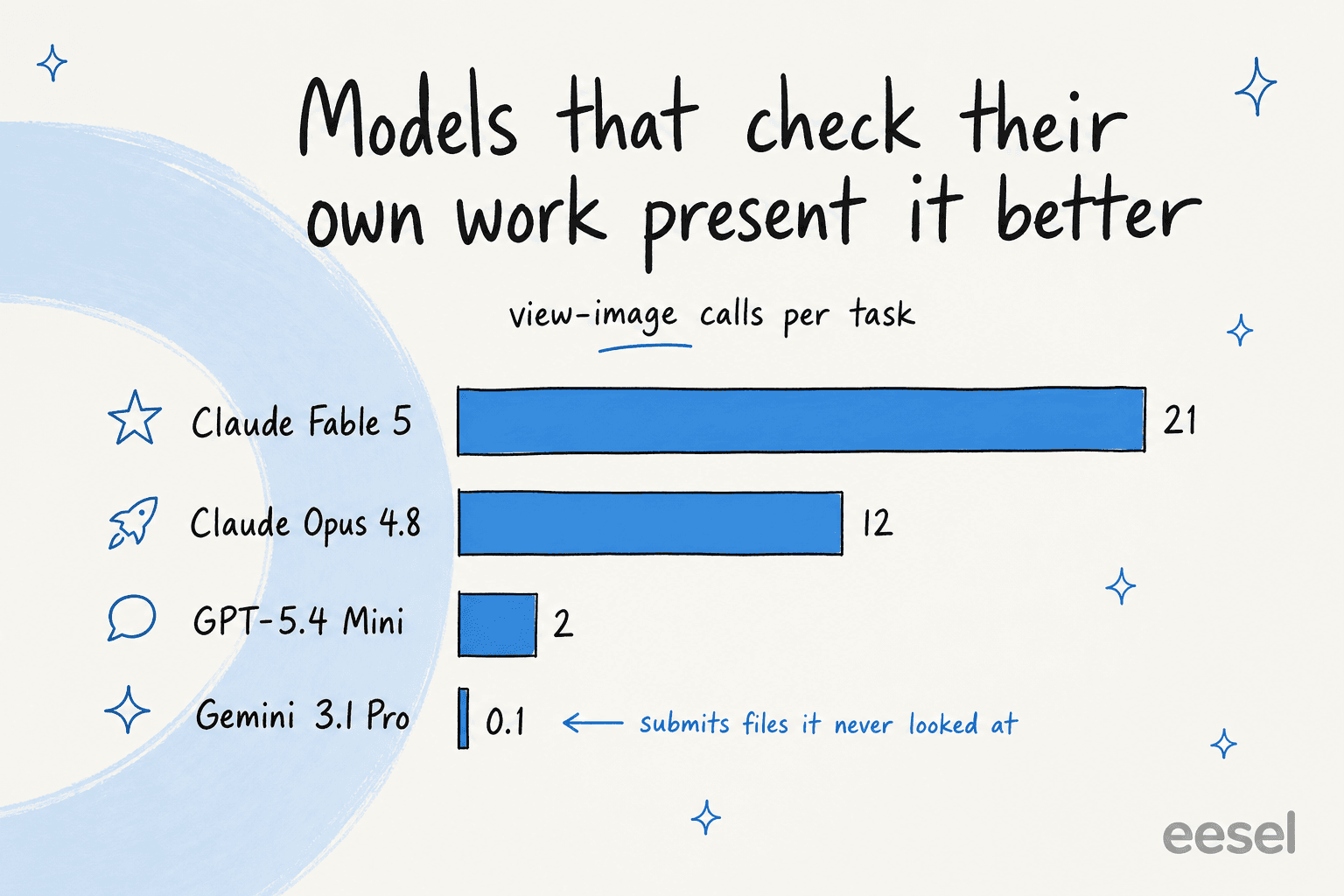
The models that score best on presentation are the ones that actually look at their own rendered output. Claude Fable 5 made about 21 view-image calls per task and Opus 4.8 about 12, while some models submitted files they'd barely glanced at (Gemini 3.1 Pro Preview averaged roughly 0.1 view-image calls). It turns out "check your work before you hand it in" is as good advice for an AI as it is for a person.
There's a deeper point underneath. AA-Briefcase separates polish from correctness precisely because a confident, well-formatted answer that's quietly wrong is more dangerous than an obviously incomplete one. That's the exact risk that shows up when an AI chatbot answers a customer, and it's why preventing hallucinations is the whole ballgame in support, not a nice-to-have.
Why a leaderboard score isn't a deployment plan
So a frontier model can do real knowledge work, sometimes brilliantly, and still whiff most of the time on the hardest, most file-heavy tasks. If you take one thing from AA-Briefcase, take this: a benchmark rank is a general capability signal, not a promise about how a model behaves on your messy data.
I've watched this play out firsthand. We've spent years putting AI agents on live support queues, and the thing that bites teams isn't whether the underlying model is smart enough in the abstract, it's whether it stays accurate on their specific tickets, their product quirks, and their edge cases. A model that tops every public leaderboard can still confidently misquote your refund policy on day one, long before it ever gets to automated ticket resolution. That's not a knock on the model; it's the difference between a benchmark and production.
The fix is the same instinct AA-Briefcase is built on: grade the work against ground truth before you trust it. For a helpdesk, that means running the AI against your own historical tickets and seeing exactly what it would have replied, rather than reading a spec sheet and hoping. Think of it as running your own private AA-Briefcase, where the test set is your real support history.
Try eesel for AI support you can actually trust
If AA-Briefcase convinced you that capability and reliability aren't the same thing, that's the exact problem eesel AI is built around. eesel works like a new support teammate that plugs into your existing helpdesk and knowledge base in minutes, then lets you simulate it on thousands of your past tickets before it ever talks to a customer, so you see its real resolution rate and exact answers up front instead of guessing from a leaderboard.
{kind=link}
You stay in control of what it's allowed to answer and when it escalates, and it's free to try on your own data. If you're evaluating AI for customer service, that simulate-first approach is the closest thing to bringing AA-Briefcase's "prove it on real work" rigour to your own queue.
Frequently Asked Questions
{kind=link}
Share this article
{kind=link}
Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}