 |
VOOZH | about |
|
VOOZH | about |
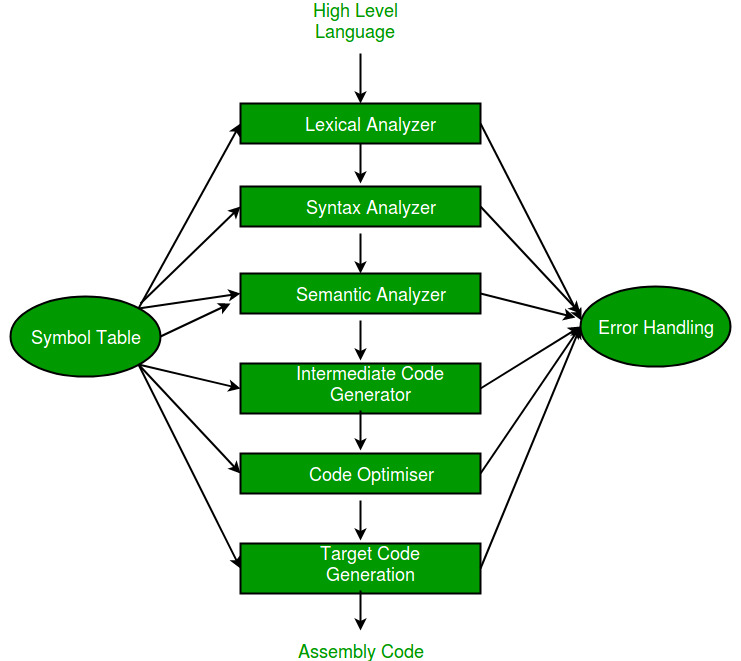
In C, the lexical analysis phase is the first phase of the compilation process. In this step, the lexical analyzer (also known as the lexer) breaks the code into tokens, which are the smallest individual units in terms of programming. In the lexical analysis phase, we parse the input string, removing the whitespaces. It also helps in simplifying the subsequent stages. In this step, we do not check for the syntax of the code. Our main focus is to break down the code into small tokens.
To know more about lexical analysis, refer to the article - Introduction to Lexical Analysis
A lexical token is a sequence of characters with a collective meaning in the grammar of programming languages. These tokens include Keyword, Identifier, Operator, Literal, and Punctuation.
For Example, the following are some lexical tokens:
The below program illustrates the implementation of a lexical analyzer in C.
Output :
For Expression 1: Token: Keyword, Value: int Token: Identifier, Value: a Token: Operator, Value: = Token: Identifier, Value: b Token: Operator, Value: + Token: Identifier, Value: c For Expression 2: Token: Keyword, Value: int Token: Identifier, Value: x Token: Operator, Value: = Token: Identifier, Value: ab Token: Operator, Value: + Token: Identifier, Value: bc Token: Operator, Value: + Token: Integer, Value: 30 Token: Operator, Value: + Token: Keyword, Value: switch Token: Operator, Value: + Token: Unidentified, Value: 0y
Explanation:
The above program implements the following functions :
Note Syntax Errors are not evaluated in lexical analysis phase. It will be taken care of in the next compilation phase (syntax analysis phase).
The above program is an implementation of a lexical analyzer program in C language. In the compilation process, the Lexical analysis phase is the first step. In this step, the lexical analyzer breaks down the input code into small units called tokens ( for example keywords, identifiers, operators, literals, and punctuation).
The lexical Analyser function parses the input code and then prints all the tokens identified by the program with their corresponding values. The lexical analyzer's major focus is on breaking down the code and identifying the tokens.
{kind=link}
{kind=link}