Compiler design is the study of how to build a compiler, which is a program that translates high-level programming languages (like Python, C++, or Java) into machine code that a computer's hardware can execute directly. The focus is on how the translation happens, ensuring correctness and making the code efficient.
Helps understand how programming languages work internally.
Essential for building compilers, interpreters, IDEs, and language tools.
Improves knowledge of program analysis and optimisation.
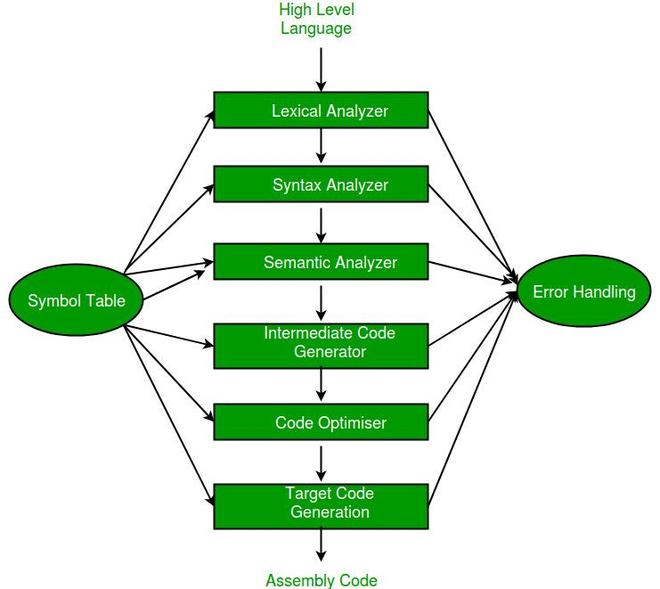
Phases of a Compiler:
Lexical Analysis: Tokenisation of source code into meaningful units (tokens).
Syntax Analysis: Construction of a parse tree based on grammar rules.
Semantic Analysis: Ensures correctness of meaning (e.g., type checking).
Intermediate Code Generation: Produces an intermediate representation (IR) for optimisation and portability.
Code Optimisation: Enhances the efficiency of the intermediate code.
Code Generation: Translates optimised IR into target machine code.
Linking is the process of combining multiple object files into a single executable file.
It resolves symbolic references such as function calls and global variables.
Performed by a linker after compilation.
Example: Linking connects a function call in one file to its actual definition in another file.
Loading
Loading is the process of placing the executable into main memory.
It assigns actual memory addresses and prepares the program for execution.
Performed by a loader before the CPU starts execution.
Read more about Difference Between Linker and Loader, Here.
Lexical Analysis
Lexical analysis is the first phase of a compiler. It breaks the source code into small meaningful units called tokens.
Key Functions:
Tokenization: Converts the source code into tokens (e.g., keywords, identifiers, operators, literals). Example: int a = 5; → Tokens: int, a, =, 5, ;
Removing Whitespaces and Comments: These are ignored during token generation.
Error Detection: Identifies errors like invalid symbols or unknown characters in the source code.
Components:
Lexical Analyzer (Lexer): Performs the actual tokenization.
Symbol Table: Stores information about variables, functions, and other identifiers.
Output of Lexical Analysis: A sequence of tokens is sent to the next phase (Syntax Analysis).
Token Categories in Lexical Analysis
Keywords:
Reserved words with specific meaning in the language.
Example: int, if, while, return.
Identifiers:
Names given to variables, functions, arrays, etc.
Example: x, count, _value.
Literals (Constants):
Fixed values in the code.
Example: 10, 3.14, 'a', "hello".
Operators:
Symbols used to perform operations.
Example: +, -, *, ==, &&.
Punctuation (Delimiters):
Symbols that structure the program.
Example: ;, ,, (), {}.
Special Symbols:
Special-purpose symbols in some languages.
Example: #, $.
Read more about Introduction of Lexical Analysis , Here.
Syntax Analysis and Parsing
Syntax analysis is the second phase of a compiler. It checks whether the tokens generated by lexical analysis follow the rules of the programming language's grammar.
Key Functions:
Parse Tree Construction: Converts tokens into a hierarchical structure (parse tree) that represents the program’s syntactic structure.
Grammar Validation: Ensures the code adheres to the grammar rules of the language (e.g., correct placement of operators, brackets).
Error Detection: Identifies syntax errors like missing semicolons or unmatched parentheses.
Input: Sequence of tokens from the lexical analyzer.
Output: Parse tree or syntax errors.
Types of Grammar Used:
Context-Free Grammar (CFG): Used to define the syntax rules of programming languages.
Production Rules: Defines how tokens can be combined (e.g., E → E + T | T).
Predicts the next production based on input tokens.
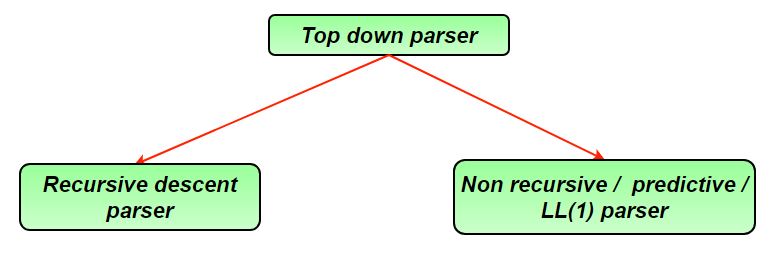
LL(1) Parser
An LL(1) parser is a top-down parser that reads input Left-to-right, constructs a Leftmost derivation, and uses 1 lookahead token to decide parsing actions.
LL(1) Grammar Conditions
For a grammar A → α | β:
First(α) ∩ First(β) = ∅ → No overlap in first symbols.
If ϵ ∈ First(β), then Follow(A) ∩ First(α) = ∅ → Avoid ambiguity when ε-productions exist.
Steps to Construct LL(1) Parsing Table:
1. Remove Left Recursion: Rewrite rules to eliminate left recursion.
2. Left Factoring: Remove common prefixes in grammar rules.
3. Find First and Follow Sets:
First Set: First terminal symbol derivable from a non-terminal.
Follow Set: Terminals that can appear immediately after a non-terminal in derivations.
4. Construct Parsing Table: Use the First and Follow sets to fill the table.
Read more about Construction of LL(1) Parsing Table, Here.
First and Follow Sets Calculation
1. First Set: Contains terminals that can appear first in strings derived from a variable.
Rules to Calculate First Set:
If X is a terminal, First(X) = {X}.
If X → ε, include ε in First(X).
If X → Y1 Y2...Yn, then:
Add First(Y1) to First(X), excluding ε.
If Y1 derives ε, check Y2, and so on.
2. Follow Set: Contains terminals that can appear immediately after a variable in input.
Rules to Calculate Follow Set
Start symbol always has $ in its Follow set
For a production A → αBβ, add First(β) (excluding ε) to Follow(B)
If β → ε, add Follow(A) to Follow(B)
If the production is A → αB, add Follow(A) to Follow(B)
Read more about First and Follow in Compiler Design, Here.
Example: Consider the Grammar:
E --> TE' E' --> +TE' | ε T --> FT' T' --> *FT' | ε F --> id | (E)
*ε denotes epsilon
Step 1: The grammar satisfies all properties in step 1.
Step 2: Calculate first() and follow().
Find their First and Follow sets:
First
Follow
E –> TE’
{ id, ( }
{ $, ) }
E’ –> +TE’/
ε
{ +, ε }
{ $, ) }
T –> FT’
{ id, ( }
{ +, $, ) }
T’ –> *FT’/
ε
{ *, ε }
{ +, $, ) }
F –> id/(E)
{ id, ( }
{ *, +, $, ) }
Step 3: Make a parser table.
Now, the LL(1) Parsing Table is:
id
+
*
(
)
$
E
E –> TE’
E –> TE’
E’
E’ –> +TE’
E’ –> ε
E’ –> ε
T
T –> FT’
T –> FT’
T’
T’ –> ε
T’ –> *FT’
T’ –> ε
T’ –> ε
F
F –> id
F –> (E)
Recursive Descent Parser
A Top-Down Parser that uses recursive functions to process input and build the parse tree.
Key Features:
Parsing Direction: Left-to-right on the input.
Derivation: Constructs Leftmost Derivation.
Implementation: Uses a set of mutually recursive functions, one for each non-terminal in the grammar.
Steps in Recursive Descent Parsing:
Start with the start symbol of the grammar.
For each non-terminal, call a corresponding recursive function.
For each terminal, match it with the input token.
Backtrack if there’s a mismatch (limited capability without modifications).
Starts with input symbols and gradually reduces them to the start symbol.
Operator Precedence Parser:
A type of Bottom-Up Parser used for operator grammars only.
Operator Grammar Conditions:
No production’s RHS contains ε (epsilon).
No two non-terminals appear adjacent on RHS.
Operator Precedence Relation:
Symbol
Meaning
a ⋗ b
Terminal a has higher precedence than b
a ⋖ b
Terminal a has lower precedence than b
a ≐ b
Terminals a and b have equal precedence
Read more about Operator Precedence Grammar and Parser, Here.
The operator precedence table for the grammar will be-
+
x
id
$
+
⋗
⋖
⋖
⋗
x
⋗
⋗
⋖
⋗
id
⋗
⋗
—
⋗
$
⋖
⋖
⋖
A
Operator Precedence Parser Algorithm :
1. If the front of input $ and top of stack both have $, it's done else 2. compare front of input b with ⋗ if b! = '⋗' then push b scan the next input symbol 3. if b == '⋗' then pop till ⋖ and store it in a string S pop ⋖ also reduce the popped string if (top of stack) ⋖ (front of input) then push ⋖ S if (top of stack) ⋗ (front of input) then push S and goto 3
Bottom-Up Parsing Actions
Shift: Move next input symbol onto the stack.
Reduce: Replace stack symbols matching a production RHS with the LHS non-terminal.
Accept: Parsing successful when start symbol is reduced and input is fully consumed.
Types of LR Parsers
LR(0) Parser
Uses closure() and goto() functions to construct canonical LR(0) item sets
May cause shift-reduce conflict when a state contains both shift and reduce items
May cause reduce-reduce conflict when two reduce actions appear in the same state
SLR (Simple LR) Parser
More powerful than LR(0) parser
Shift-reduce conflict occurs if FOLLOW set intersects with lookahead
Reduce-reduce conflict occurs when FOLLOW sets of left-hand side non-terminals intersect
CLR (Canonical LR) Parser
Similar to SLR parser
Reductions are placed only in FOLLOW of the left-hand side non-terminal
More powerful and resolves more conflicts than SLR
LALR (Look-Ahead LR) Parser
Constructed by merging CLR states with identical productions but different lookaheads
More efficient than CLR parser
Every LALR grammar is CLR, but not every CLR grammar is LALR
Steps for LR Parsing Table Construction:
1. Augment the Grammar: Add a new production S' → S, where S is the start symbol.
Action Table: Contains shift, reduce, accept, or error.
Goto Table: Specifies transitions for non-terminals.
4. Conflict Checking: Ensure no shift/reduce or reduce/reduce conflicts.
Parsers Comparison : LR(0) ⊂ SLR ⊂ LALR ⊂ CLR LL(1) ⊂ LALR ⊂ CLR If number of states LR(0) = n1, number of states SLR = n2, number of states LALR = n3, number of states CLR = n4 then, n1 = n2 = n3 <= n4 .
Definition:CFG represents a program as nodes (basic blocks) and edges (control flow).
Basic Block:
A basic block is a sequence of instructions with:
One entry point (leader)
Steps to Identify Basic Blocks
Start with the first instruction of the program which is always the leader.
Mark every instruction that is the target of a branch (jump/loop) as a leader.
Mark every instruction immediately following a branch (conditional/unconditional) as a leader.
For each leader, gather all subsequent instructions until the next leader or program end.
End the block at the last instruction before a new leader, a branch, or a return.
Ensure no block contains internal branches (except its last instruction).
Represent each block as a node in a Control Flow Graph (CFG).
Connect blocks with edges based on jumps/fall-through execution.
Applications
Detect independent code blocks
Enable optimizations like dead code elimination, loop optimization, and instruction scheduling
Code Optimization:
Objective: Reduce execution time and memory usage.
Techniques:
1. Constant Folding: Evaluate constant expressions at compile time. Example: x = 2 * 3 + y → x = 6 + y.
2. Copy Propagation: Replace redundant variables. Example: z = y + 2 → z = x + 2 (if x = y).
3. Strength Reduction: Replace expensive operations with cheaper ones. Example: x = 2 * y → x = y + y.
4. Dead Code Elimination: Remove code that does not affect the output. Example: Remove if (false) { ... }.
5. Common Subexpression Elimination: Eliminate repeated calculations using DAGs. Example:
x = (a + b) + (a + b) + c→ t1 = a + b→ x = t1 + t1 + c
6. Loop Optimization:
Code Motion: Move invariant code outside loops.
Induction Variable Elimination: Replace variables with simpler expressions.
Loop Jamming: Combine multiple loops.
Loop Unrolling: Reduce loop overhead by executing multiple iterations in a single iteration.
7. Peephole Optimization:
Analyze short sequences of code (peepholes) and replace them with faster alternatives. Applied to intermediate or target code. Following Optimizations can be used:
Redundant instruction elimination
Flow-of-control optimizations
Algebraic simplifications
Use of machine idioms
Read more about Code Optimization in Compiler Design, Here.

{kind=link}
{kind=link}
{kind=link}
{kind=link}