Shift-reduce parsing is a popular bottom-up technique used in syntax analysis, where the goal is to create a parse tree for a given input based on grammar rules. The process works by reading a stream of tokens (the input), and then working backwards through the grammar rules to discover how the input can be generated.
- Input Buffer: This stores the string or sequence of tokens that needs to be parsed.
- Stack: The parser uses a stack to keep track of which symbols or parts of the parse it has already processed. As it processes the input, symbols are pushed onto and popped off the stack.
- Parsing Table: Similar to a predictive parser, a parsing table helps the parser decide what action to take next.
Shift-reduce parsing works by processing the input left to right and gradually building up a parse tree by shifting tokens onto the stack and reducing them using grammar rules, until it reaches the start symbol of the grammar.
Four Main Operations of Shift Reduce Parser
- Shift: Move the next input symbol onto the stack when no reduction is possible.
- Reduce: Replace a sequence of symbols at the top of the stack with the left-hand side of a grammar rule.
- Accept: Successfully complete parsing when the entire input is processed and the stack contains only the start symbol.
- Error: Handle unexpected or invalid input when no shift or reduce action is possible.
Working
Shift-reduce parsers use a Deterministic Finite Automaton (DFA) to help recognize these handles. The DFA helps track what symbols are on the stack and decides when to shift or reduce by following a set of rules. Instead of directly analyzing the structure, the DFA helps the parser determine when reductions should occur based on the stack's contents.
The shift-reduce parser is a bottom-up parsing technique that breaks down a string into two parts: the undigested part and the semi-digested part. Here’s how it works:
- Undigested Part: This part contains the remaining tokens that still need to be processed. It is the input that hasn’t been handled yet.
- Semi-Digested Part: This part is on a stack. It's where tokens or parts of the string that have been processed are stored.
Parsing Process
At the beginning, the input string is entirely undigested, and the stack is empty.
The parser performs one of three actions at each step:
Shift
- When the parser can’t reduce the sequence on the stack (because the stack doesn’t match any production rule), it shifts the next token from the input to the stack.
- This means the parser takes one token from the undigested part (the input) and places it on the stack.
- The stack keeps growing as tokens are added until a valid reduction is possible.
Reduce
- If the sequence of tokens on the stack matches the right side of a production rule, the parser can reduce it. This means the sequence of tokens on the stack is replaced with a non-terminal symbol (the left side of the production rule).
- For example, if the stack has
id, and there’s a production rule T → id, the stack would change from id to T. - This process is like reversing the rule. It’s called a reduction.
- The shift-reduce process continues until the entire stack is reduced to the start symbol of the grammar with no input remaining, indicating a successful parse, and the sequence of symbols being reduced at each step (such as id in the rule T → id) is called a handle, whose correct identification is a key task of a shift-reduce parser.
Error
- If neither shift nor reduce actions are possible, the parser encounters an error.
- An error occurs when the sequence of symbols on the stack does not match any production rule and no reduction is possible, or when shifting the next input token would lead to a stack configuration that can never be reduced to the start symbol—for example, if the stack contains E + and the next input token is ), neither reduction nor a valid shift is possible, indicating a syntax error.
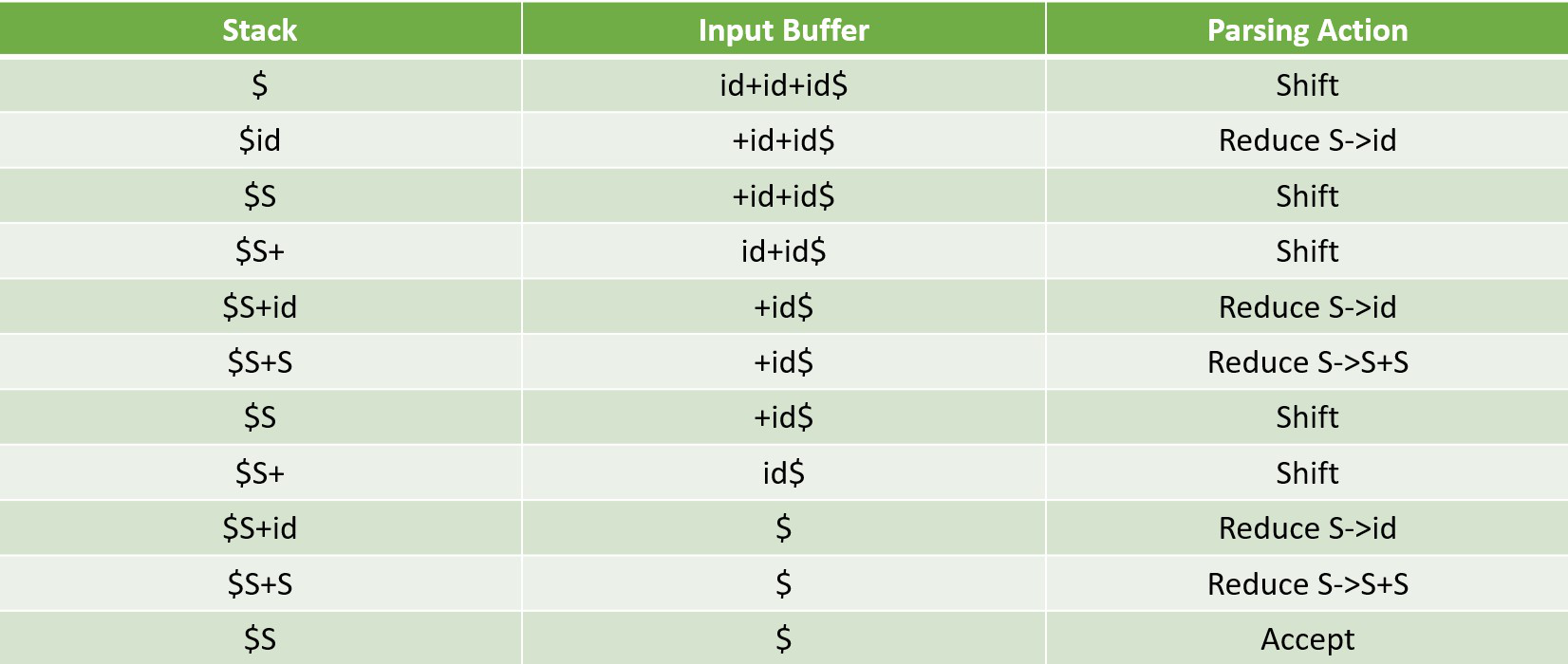
Example 1 - Consider the grammar
S --> S + S
S --> S * S
S --> id
Perform Shift Reduce parsing for input string "id + id + id".
👁 Image
Example 2 - Consider the grammar
E --> 2E2
E --> 3E3
E --> 4
Perform Shift Reduce parsing for input string "32423".
👁 Image
Example 3 - Consider the grammar
S --> ( L ) | a
L --> L , S | S
Perform Shift Reduce parsing for input string "( a, ( a, a ) ) ".
| Stack | Input Buffer | Parsing Action |
|---|
| $ | ( a , ( a , a ) ) $ | Shift |
| $ ( | a , ( a , a ) ) $ | Shift |
| $ ( a | , ( a , a ) ) $ | Reduce S → a |
| $ ( S | , ( a , a ) ) $ | Reduce L → S |
| $ ( L | , ( a , a ) ) $ | Shift |
| $ ( L , | ( a , a ) ) $ | Shift |
| $ ( L , ( | a , a ) ) $ | Shift |
| $ ( L , ( a | , a ) ) $ | Reduce S → a |
| $ ( L , ( S | , a ) ) $ | Reduce L → S |
| $ ( L , ( L | , a ) ) $ | Shift |
| $ ( L , ( L , | a ) ) $ | Shift |
| $ ( L , ( L , a | ) ) $ | Reduce S → a |
| $ ( L, ( L, S | ) ) $ | Reduce L →L, S |
| $ ( L, ( L | ) ) $ | Shift |
| $ ( L, ( L ) | ) $ | Reduce S → (L) |
| $ ( L, S | ) $ | Reduce L → L, S |
| $ ( L | ) $ | Shift |
| $ ( L ) | $ | Reduce S → (L) |
| $ S | $ | Accept |
Program to Simulate Shift-Reduce Parsing
Following is the implementation-
OutputGRAMMAR is -
E->2E2
E->3E3
E->4
stack input action
$ 32423$ SHIFT
$3 2423$ SHIFT
$32 423$ SHIFT
$324 23$ REDUCE TO E -> 4
$32E 23$ SHIFT
$32E2 3$ REDUCE TO E -> 2E2
$3E 3$ SHIFT
$3E3 $ REDUCE TO E -> 3E3
$E $ Accept
Key Characteristics
- Efficient parsing technique for a wide range of context-free grammars.
- Commonly used in practical compiler implementations for many programming languages.
- Capable of handling both left-recursive and right-recursive grammars.
- Requires relatively small parse tables, leading to efficient memory usage.
- Works well for most programming language syntax constructs.

{kind=link}
{kind=link}
{kind=link}