 |
VOOZH | about |
|
VOOZH | about |
The compilation process can be organized in different ways based on how the source program is analyzed and translated. One common classification depends on the number of times the compiler processes the source code during compilation. Each complete traversal of the source program or its intermediate representation is called a compiler pass. Based on the number of passes performed, compilers are categorized into :
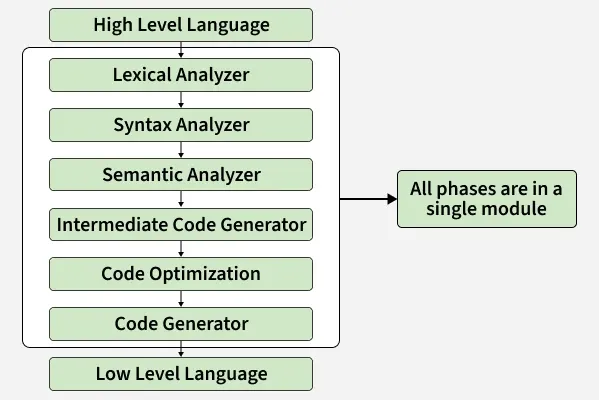
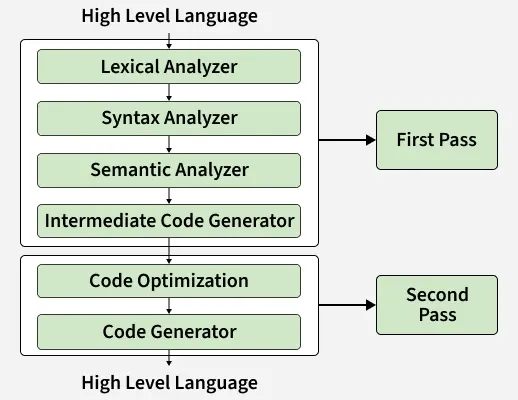
Compiler passes are classified based on how many times the source program is processed during compilation.
Reads the source code only once and performs all compilation phases in that single scan.
Typically divided into:
First Pass (Front-End / Analysis Phase)
Second Pass (Back-End / Synthesis Phase)
Case 1: Different Languages, Same Machine
If multiple programming languages target the same machine:
Case 2: Same Language, Different Machines
If one language targets multiple machines:
This modularity makes multi-pass compilers more flexible and reusable.
| One-Pass Compiler | Two-Pass Compiler |
|---|---|
| Compiles source code in a single pass | Compiles source code in two passes |
| Scans source code once | Scans source code twice |
| Faster | Slower |
| Limited optimization | Better optimization |
| Limited error detection | Better error detection |
| Simple design | More complex design |
| Less memory required | More memory required |
| May not generate intermediate code | Usually generates intermediate code |
| Suitable for simple languages | Suitable for complex languages |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}