 |
VOOZH | about |
|
VOOZH | about |
Pattern searching is an algorithm that involves searching for patterns such as strings, words, images, etc.
We use certain algorithms to do the search process. The complexity of pattern searching varies from algorithm to algorithm. They are very useful when performing a search in a database. The Pattern Searching algorithm is useful for finding patterns in substrings of larger strings. This process can be accomplished using a variety of algorithms that we are going to discuss in this blog.
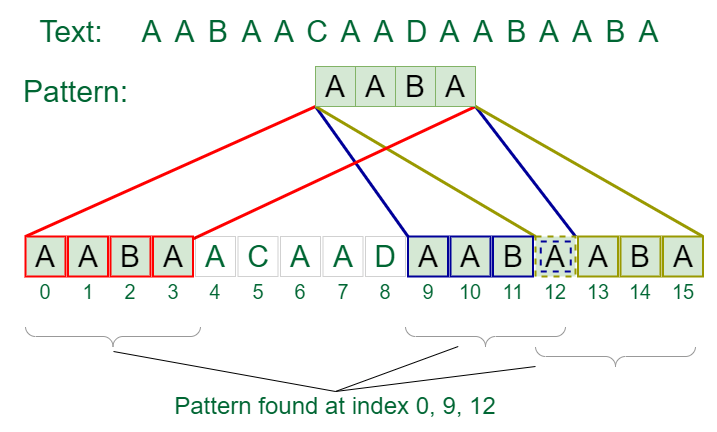
Naive pattern searching is the simplest method among other pattern-searching algorithms. It checks for all characters of the main string to the pattern. This algorithm is helpful for smaller texts. It does not need any pre-processing phases. We can find the substring by checking once for the string. It also does not occupy extra space to perform the operation.
The time complexity of Naive Pattern Search method is O(m*n). The m is the size of pattern and n is the size of the main string.
Pattern found at index 0 Pattern found at index 9 Pattern found at index 13
Time Complexity: O(N*M)
Auxiliary Space: O(1)
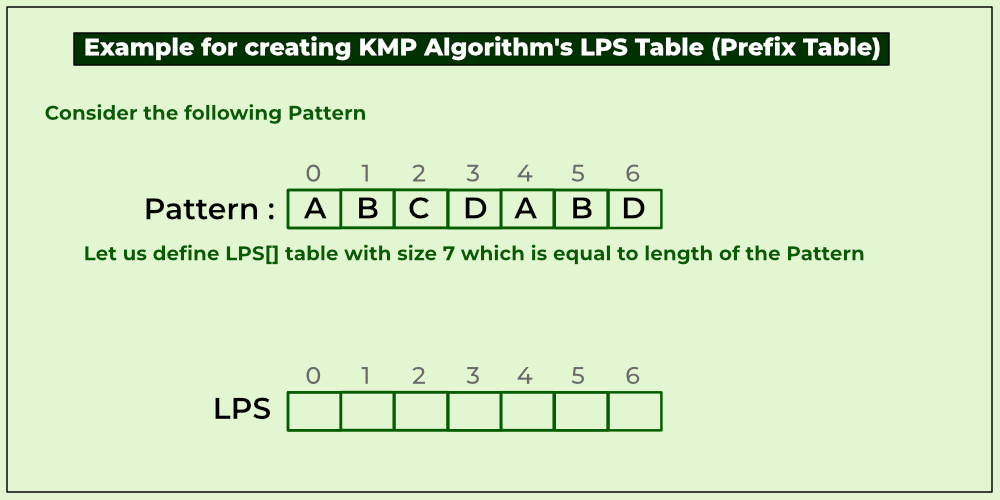
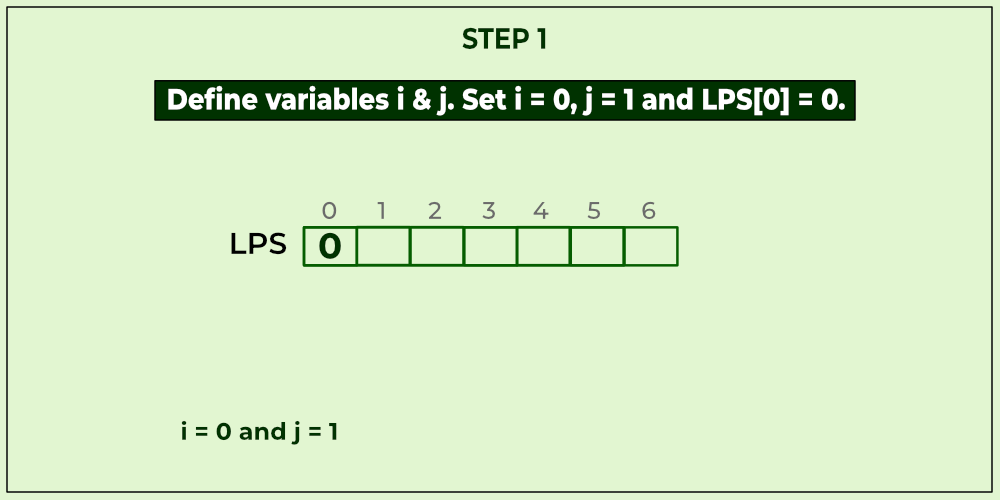
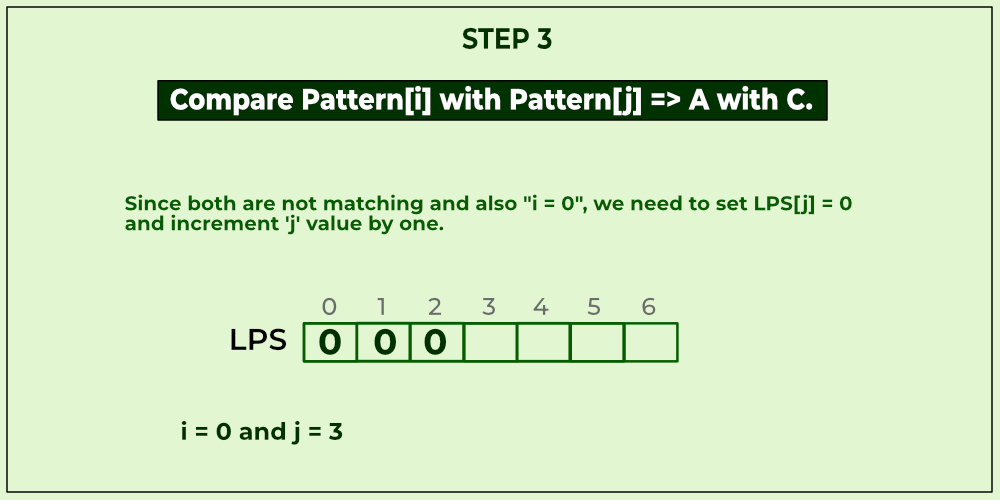
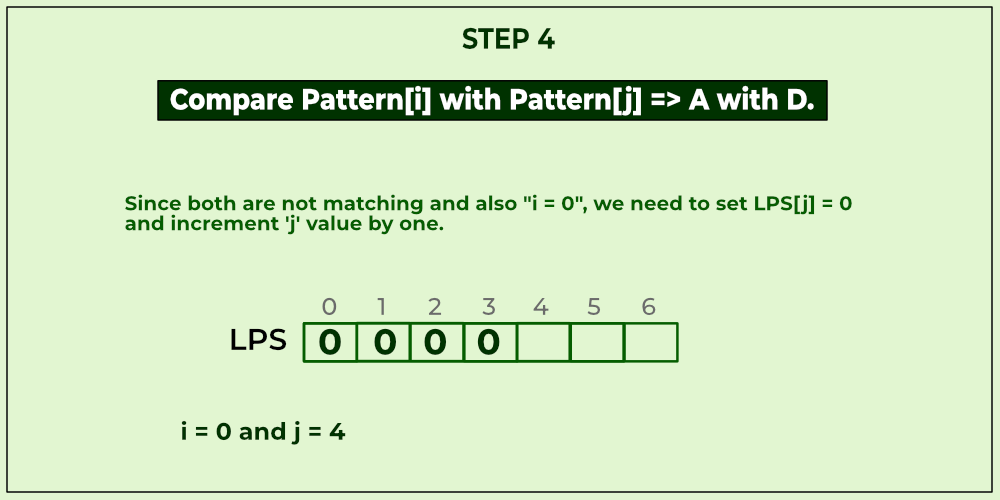
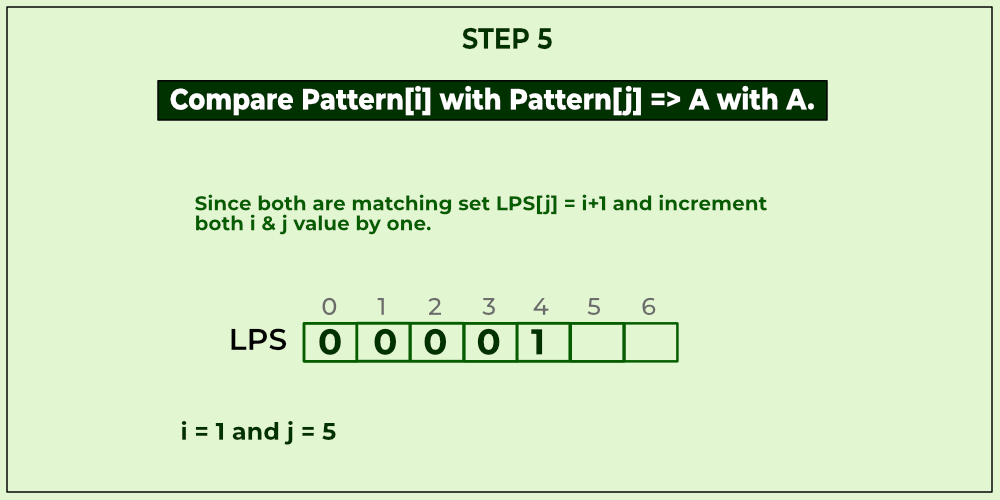
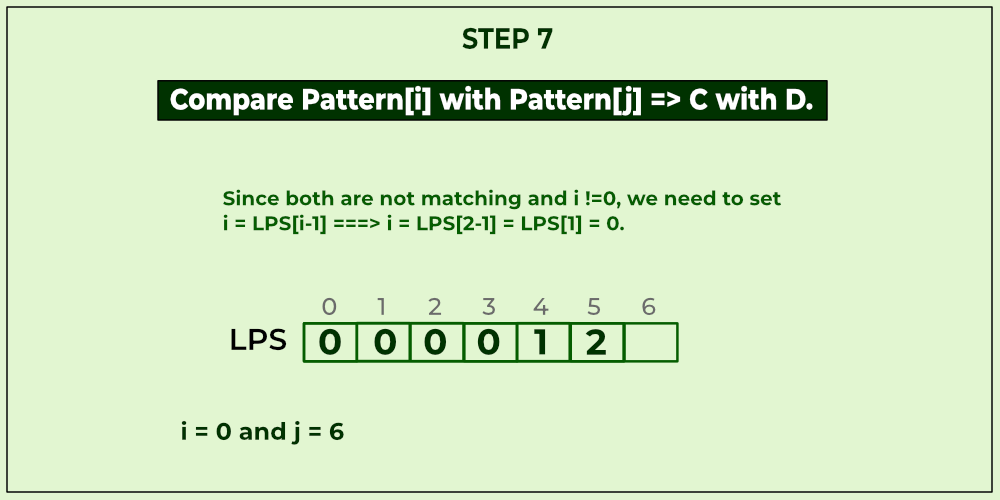
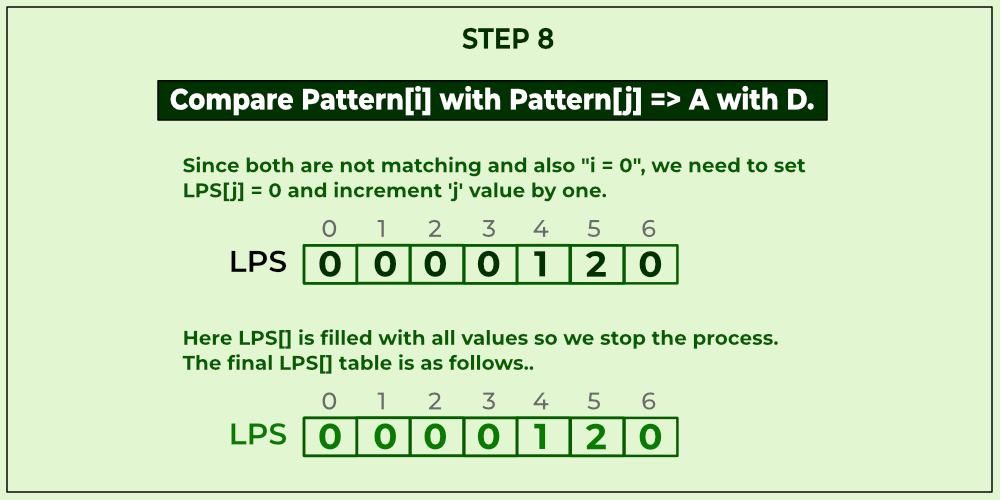
KMP algorithm is used to find a "Pattern" in a "Text". This algorithm compares character by character from left to right. But whenever a mismatch occurs, it uses a preprocessed table called "Prefix Table" to skip characters comparison while matching. Sometimes prefix table is also known as LPS Table. Here LPS stands for "Longest proper Prefix which is also Suffix".
We use the LPS table to decide how many characters are to be skipped for comparison when a mismatch has occurred.
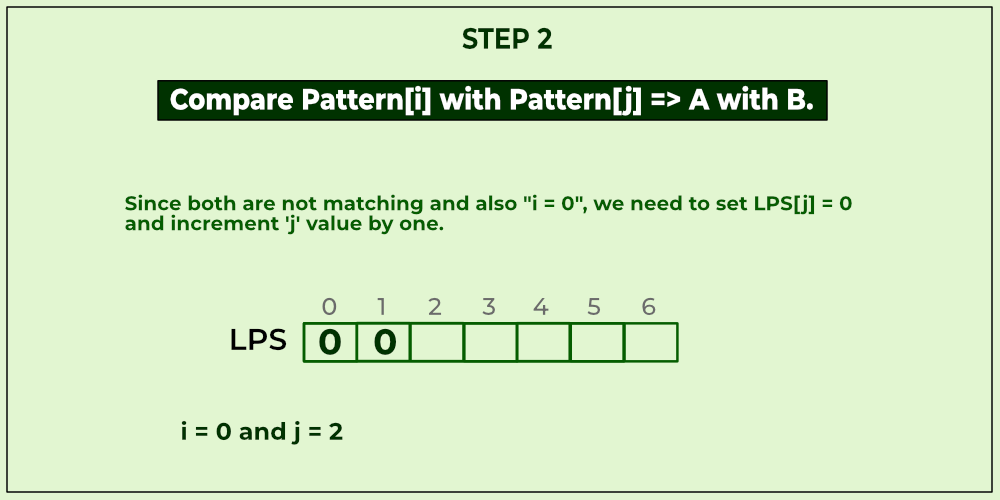
When a mismatch occurs, check the LPS value of the previous character of the mismatched character in the pattern. If it is '0' then start comparing the first character of the pattern with the next character to the mismatched character in the text. If it is not '0' then start comparing the character which is at an index value equal to the LPS value of the previous character to the mismatched character in pattern with the mismatched character in the Text.
Let's take a look on working example of KMP Algorithm to find a Pattern in a Text.
Implementation of the KMP algorithm:
Found pattern at index 10
Time complexity: O(n + m)
Auxiliary Space: O(M)
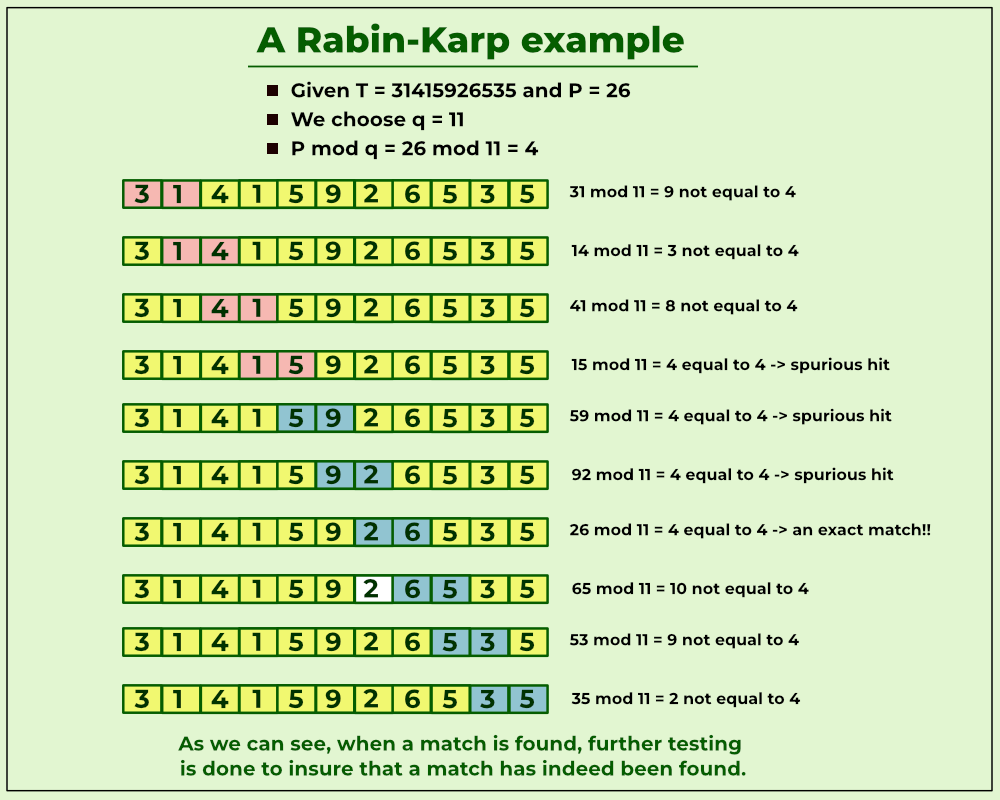
Rabin-Karp algorithm is an algorithm used for searching/matching patterns in the text using a hash function. Unlike Naive string-matching algorithm, it does not travel through every character in the initial phase rather it filters the characters that do not match and then perform the comparison.
Rabin-Karp compares a string's hash values, rather than the strings themselves. For efficiency, the hash value of the next position in the text is easily computed from the hash value of the current position.
Below is the implementation of the Rabin-Karp algorithm.
Pattern found at index 0 Pattern found at index 10
Time Complexity:
Space Complexity :
The space complexity of the Rabin-Karp algorithm is O(1), which means that it is a constant amount of memory that is required, regardless of the size of the input text and pattern. This is because the algorithm only needs to store a few variables that are updated as the algorithm progresses through the text and pattern. Specifically, the algorithm needs to store the hash value of the pattern, the hash value of the current window in the text, and a few loop counters and temporary variables. Since the size of these variables is fixed, the space complexity is constant.
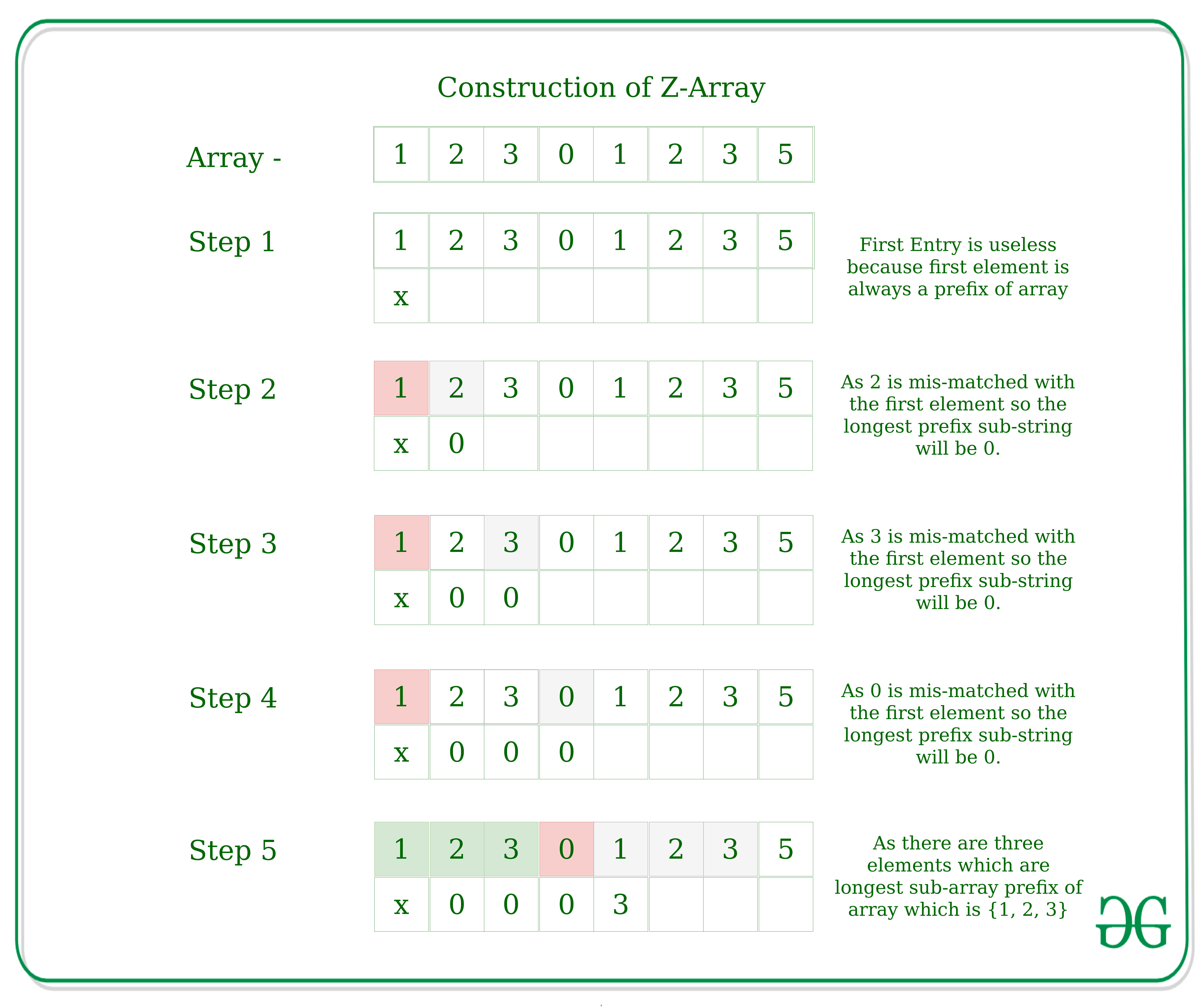
This algorithm finds all occurrences of a pattern in a text in linear time. Let length of text be n and of pattern be m, then total time taken is O(m + n) with linear space complexity. Z algorithm works by maintaining an auxiliary array called the Z array. This Z array stores the length of the longest substring, starting from the current index, that also it's prefix.
For a string str[0..n-1], Z array is of same length as string. An element Z[i] of Z array stores length of the longest substring starting from str[i] which is also a prefix of str[0..n-1]. The first entry of Z array is meaning less as complete string is always prefix of itself.
Example:
Index 0 1 2 3 4 5 6 7 8 9 10 11
Text a a b c a a b x a a a z
Z values X 1 0 0 3 1 0 0 2 2 1 0
A Simple Solution is to run two nested loops, the outer loop goes to every index and the inner loop finds length of the longest prefix that matches the substring starting at current index. The time complexity of this solution is O(n2).
We can construct Z array in linear time. The idea is to maintain an interval [L, R] which is the interval with max R
such that [L, R] is prefix substring (substring which is also a prefix.
Steps for maintaining this interval are as follows –
- If i > R then there is no prefix substring that starts before i and ends after i, so we reset L and R and compute new [L, R] by comparing str[0..] to str[i..] and get Z[i] (= R-L+1).
- If i <= R then let K = i-L, now Z[i] >= min(Z[K], R-i+1) because str[i..] matches with str[K..] for atleast R-i+1 characters (they are in[L, R] interval which we know is a prefix substring).
Now two sub cases arise:
- If Z[K] < R-i+1 then there is no prefix substring starting at str[i] (otherwise Z[K] would be larger) so Z[i] = Z[K]and interval [L, R] remains same.
- If Z[K] >= R-i+1 then it is possible to extend the [L, R] interval thus we will set L as i and start matching from str[R] onwards and get new R then we will update interval [L, R] and calculate Z[i] (=R-L+1).
Below is the implementation of the Z algorithm:
Pattern found at index 0 Pattern found at index 10
Time Complexity: O(m+n), where m is length of pattern and n is length of text.
Auxiliary Space: O(m+n)
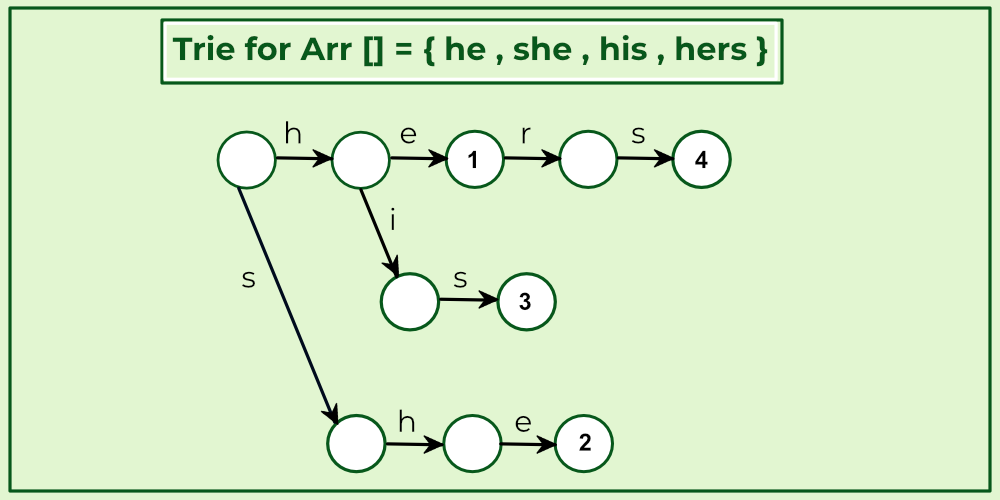
Aho-Corasick Algorithm finds all words in O(n + m + z) time where z is the total number of occurrences of words in text. The Aho–Corasick string matching algorithm formed the basis of the original Unix command "fgrep".
Preprocessing: Build an automaton of all words in arr[] The automaton has mainly three functions:
Go To: This function simply follows edges of Trie of all words in arr[].
It is represented as 2D array g[][] where we store next state for current state and character.Failure: This function stores all edges that are followed when current character doesn't have edge in Trie.
It is represented as1D array f[] where we store next state for current state.Output: Stores indexes of all words that end at current state.
It is represented as 1D array o[] where we store indices of all matching words as a bitmap for current state.
Matching: Traverse the given text over built automaton to find all matching words.
Preprocessing:
Preprocessing: We first Build a Trie (or Keyword Tree) of all words.
Go to: We build Trie. And for all characters which don’t have an edge at the root, we add an edge back to root.
Failure: For a state s, we find the longest proper suffix which is a proper prefix of some pattern. This is done using Breadth First Traversal of Trie.
Output: For a state s, indexes of all words ending at s are stored. These indexes are stored as bitwise map (by doing bitwise OR of values). This is also computing using Breadth First Traversal with Failure.
Below is the implementation of the Aho-Corasick Algorithm:
Word his appears from 1 to 3 Word he appears from 4 to 5 Word she appears from 3 to 5 Word hers appears from 4 to 7
Time Complexity: O(n + l + z), where ‘n’ is the length of the text, ‘l’ is the length of keywords, and ‘z’ is the number of matches.
Auxiliary Space: O(l * q), where ‘q’ is the length of the alphabet since that is the maximum number of children a node can have.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![👁 Compare pattern[0] and pattern[1] values](https://media.geeksforgeeks.org/wp-content/uploads/20221108112047/step3.png){kind=link}
![👁 Compare pattern[0] with next characters in text.](https://media.geeksforgeeks.org/wp-content/uploads/20221108112048/step4.png){kind=link}
![👁 Compare pattern[2] with mismatched characters in text.](https://media.geeksforgeeks.org/wp-content/uploads/20221108112049/step5.png){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![👁 ills entries in goto g[][] and output o[]](https://media.geeksforgeeks.org/wp-content/uploads/20221108113225/aho2.png){kind=link}