 |
VOOZH | about |
|
VOOZH | about |
Data Structures and Algorithms (DSA) are fundamental for effective problem-solving and software development. Python, with its simplicity and flexibility, provides a wide range of libraries and packages that make it easier to implement various DSA concepts. This "Last Minute Notes" article offers a quick and concise revision of the essential topics in Data Structures using Python.
Table of Content
In Python, collections are specialized container data types used to store and manage multiple items. They provide alternatives to built-in data types like lists, tuples, and dictionaries, offering enhanced functionality and efficiency for specific use cases.
1. List
In Python, a list is an ordered, mutable collection that can hold elements of different types. Lists are one of the most commonly used data types in Python because of their flexibility and ease of use.
Syntax:
my_list = [1, 2, 3, "Python", 4.5]Features:
append(), remove(), insert(), and pop().2. Tuples
In Python, a tuple is an ordered, immutable collection of items. Once a tuple is created, its elements cannot be modified, added, or removed. Tuples can store items of different data types, just like lists, but they offer a more efficient and safer alternative when you don't want the data to change.
Syntax:
my_tuple = (1, 2, 3, "Python", 4.5)Features:
3. Sets
In Python, a set is an unordered collection of unique elements. Sets do not allow duplicate values, making them useful for storing distinct items. Since they are unordered, the elements do not have a specific index and cannot be accessed by position.
Syntax:
my_set = {1, 2, 3, 4}Features:
4. Dictionary
A dictionary is an unordered collection of key-value pairs. Each key is unique, and it maps to a specific value. Dictionaries are useful for storing and retrieving data quickly based on a unique key.
Syntax:
my_dict = {"key1": "value1", "key2": "value2"}Features:
5. List Comprehension
List comprehension is a concise way to create lists in Python. It provides a more readable and efficient alternative to traditional for loops for generating lists. You can use it to apply expressions or conditions while building a new list from an existing iterable.
Syntax:
new_list = [expression for item in iterable if condition]Features:
6. NamedTuple
A NamedTuple is a subclass of the built-in tuple that allows you to define a tuple with named fields. It is useful for creating simple classes that hold data and allow you to access values using field names instead of relying on index positions.
Syntax:
from collections import namedtuple# Define a named tuple with fields 'name' and 'age'Person = namedtuple('Person', ['name', 'age'])Features:
A deque (short for Double-Ended Queue) is a collection type from the collections module that allows fast appends and pops from both ends (front and rear) of the container. It is highly efficient for tasks that require adding or removing elements from both ends.
Syntax:
from collections import dequemy_deque = deque([1, 2, 3])Features:
A Counter is a subclass of the dict class from the collections module, designed to count the frequency of elements in an iterable. It helps to quickly tally and store counts of items, making it especially useful for tasks like frequency analysis.
Syntax:
from collections import Countermy_counter = Counter([1, 2, 2, 3, 3, 3])Features:
An OrderedDict is a specialized dictionary from the collections module that maintains the order of key-value pairs as they are added. Unlike a regular dictionary (which does not guarantee order before Python 3.7), an OrderedDict remembers the insertion order of items.
Syntax:
from collections import OrderedDictmy_ordered_dict = OrderedDict([('key1', 'value1'), ('key2', 'value2')])Features:
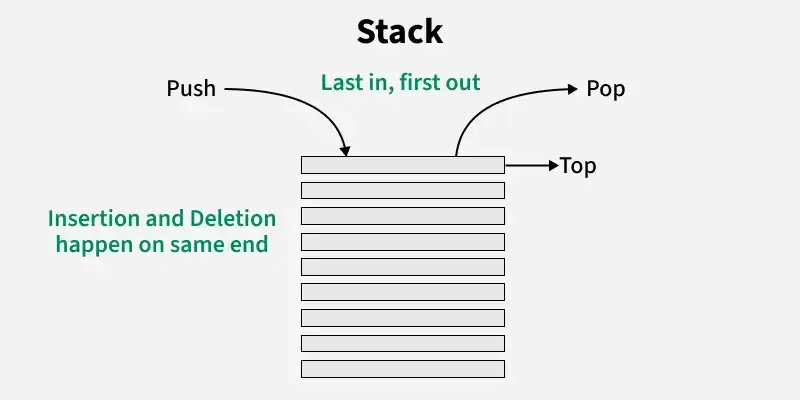
OrderedDict remembers the order in which items were inserted.get(), keys(), and items(), are supported.A stack is a linear data structure that follows the Last-In/First-Out (LIFO) principle. Elements are added and removed from the same end, with the operations called push (insert) and pop (delete).
The functions associated with stack are:
There are several ways to implement a stack in Python. A stack in Python can be implemented using the following approaches:
1. Implementation Using List
Python's built-in list can be used as a stack, where append() adds elements and pop() removes them in LIFO order. However, lists can face performance issues as they grow, as they require memory reallocation when the stack exceeds the current memory block, causing some append() operations to take longer.
Stack size: 3 3 2 Is stack empty? False 1
2. Implementation Using collections.deque
Python’s stack can be implemented using the deque class from the collections module. Deque is preferred over lists for faster append() and pop() operations, offering O(1) time complexity compared to O(n) for lists. It uses the same methods: append() and pop().
Stack size: 3 3 2 Is stack empty? False 1
3. Implementation Using Queue Module
The queue module in Python includes a LIFO Queue, which functions as a stack. Data is added using put() and removed using get().
Key functions:
True if the queue is empty.True if the queue is full.QueueEmpty if empty.QueueFull if full.Stack size: 3 3 2 Is stack empty? False 1
4. Implementation Using a Singly Linked List
A linked list can implement a stack with methods like addHead(item) and removeHead(), both running in constant time.
Key methods:
True if the stack is empty.Node Data: c a g b d Remove First Node: a g b d Remove Last Node: a g b Remove Node at Index 1: a b Linked list after removing a node: a b Update node Value at Index 0: z b Size of linked list: ...
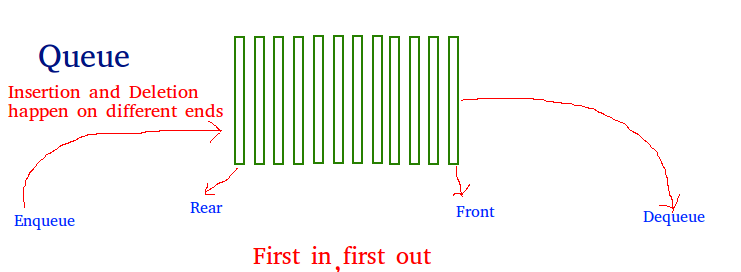
A queue is a linear data structure that follows the First In First Out (FIFO) principle, where the first item added is the first to be removed. It’s commonly used in scenarios like customer service, where the first customer to arrive is the first to be served.
Operations associated with queue are:
There are several ways to implement a queue in Python. This article explores different methods using Python's built-in data structures and modules. A queue can be implemented in the following ways:
1. Implementation Using List
Python’s built-in list can be used as a queue, using append() to enqueue and pop() to dequeue. However, lists are inefficient for queues, as removing elements from the beginning requires shifting all other elements, which takes O(n) time. The code simulates a queue by adding elements ('a', 'b', 'c') and then dequeuing them, resulting in an empty queue.
Queue size: 3 1 2 Is queue empty? False 3
2. Implementation Using collections.deque
In Python, a queue can be implemented using the deque class from the collections module, offering O(1) time complexity for append() and popleft() operations, unlike lists which have O(n) time complexity. The code demonstrates enqueueing ('a', 'b', 'c') using append() and dequeuing with popleft(), resulting in an empty queue. An attempt to dequeue from an empty queue raises an IndexError.
Queue size: 3 1 2 Is queue empty? False 3
3. Implementation Using queue.Queue
Python's queue module implements a FIFO queue with the Queue(maxsize) class, where maxsize limits the queue size (0 means infinite). Key functions include:
True if the queue is empty.True if the queue is full.QueueEmpty.QueueFull if full.Queue size: 3 Is queue full? True 1 2 Is queue empty? False 3
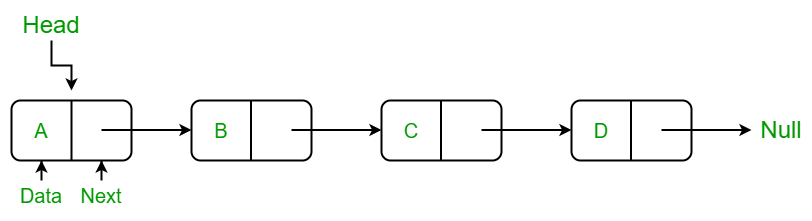
A linked list is a linear data structure consisting of nodes, where each node contains data and a link to the next node. The first node, pointed to by the head, allows access to all elements in the list. In Python, linked lists are implemented using classes.
In the LinkedList class, we use the Node class to create a linked list. The class includes methods to:
insertAtBegin(): Insert a node at the beginning.insertAtIndex(): Insert a node at a specific index.insertAtEnd(): Insert a node at the end.remove_node(): Delete a node with specific data.sizeOfLL(): Get the current size of the linked list.printLL(): Traverse and print the data of each node.The Node class has an __init__ function that initializes the node with the provided data and sets its reference to None, as there’s no next node if it’s the only node.
1. Insertion at Beginning in Linked List
This method inserts a node at the beginning of the linked list. It creates a new node with the given data and, if the head is empty, sets the new node as the head. Otherwise, the current head becomes the next node, and the new node is set as the head.
2. Insert a Node at a Specific Position in a Linked List
This method inserts a node at a specified index. It creates a new node with the given data and initializes a counter. If the index is 0, it calls the insertAtBegin() method. Otherwise, it traverses the list until reaching the desired position. If the index exists, the new node is inserted; if not, it prints "Index not present".
3. Insertion in Linked List at End
This method inserts a node at the end of the linked list. It creates a new node with the given data and checks if the head is empty. If it is, the new node becomes the head. Otherwise, it traverses the list to the last node and inserts the new node after it.
This code defines a method called updateNode in a linked list class. It is used to update the value of a node at a given position in the linked list.
1. Removing First Node from Linked List
This method removes the first node of the linked list by setting the second node as the new head.
2. Removing Last Node from Linked List
This method deletes the last node by first traversing to the second-last node, then setting its next reference to None, effectively removing the last node.
3. Deleting a Linked List Node at a given Position
This method removes a node at a given index, similar to the insert_at_index() method. If the head is None, it returns immediately. Otherwise, it initializes current_node with the head and position with 0. If the position matches the index, it calls remove_first_node(). Otherwise, it traverses the list using a while loop until current_node is None or the position reaches the target index minus 1. After the loop, if current_node or current_node.next is None, the index is out of range. If not, it bypasses the node to remove it.
3. Delete a Linked List Node of a given Data
This method removes the node with the specified data from the linked list. It starts by setting current_node to the head and traverses the list using a while loop. The loop breaks when current_node is None or the data of the next node matches the given data. After exiting the loop, if current_node is None, the node is not found, and the method returns. If the next node’s data matches, the node is removed by linking the current node's next to the next node’s next.
This method traverses the linked list, printing the data of each node. It starts with current_node as the head and iterates through the list, printing the data and moving to the next node until current_node is None.
This method returns the size of the linked list. It initializes a counter size to 0, then traverses the list, incrementing the size with each node until current_node becomes None. If the list is empty, it returns 0.
In this example, we define the Node and LinkedList classes and create a linked list named "llist." We insert four nodes with character data ('a', 'b', 'c', 'd', 'g') and print the list using the printLL() method. After removing some nodes, we print the list again to verify successful deletion, followed by printing the size of the linked list.
Node Data: c a g b d Remove First Node: a g b d Remove Last Node: a g b Remove Node at Index 1: a b Linked list after removing a node: a b Update node Value at Index 0: z b Size of linked list: ...
A tree is a hierarchical data structure consisting of nodes connected by edges. It is used to represent relationships, such as family trees, organizational structures, and file systems. The topmost node is called the root, and each node contains a value and references (or pointers) to its child nodes.
Key terms in Tree:
In-order traversal of the tree: 20 30 40 50 60 70 80
A Hash Table (also known as a Hash Map) is a data structure that stores data in key-value pairs, making it efficient for lookup, insertion, and deletion operations. It uses a hash function to compute an index into an array of buckets or slots, from which the desired value can be found.
In Python, dictionaries (dict) are implemented as hash tables, providing an easy way to store and retrieve data using keys.
Major concepts of Hash Tables:
In Python, dictionaries are implemented using hash tables. Here's how they work:
1. Creating a Dictionary:
my_dict = {'apple': 1, 'banana': 2, 'cherry': 3}
2. Adding Items:
my_dict['orange'] = 4 # Adds a new key-value pair
3. Accessing Values:
print(my_dict['apple']) # Output: 1
4. Updating Values:
my_dict['banana'] = 5 # Updates the value associated with the key 'banana'
5. Deleting Items:
del my_dict['cherry'] # Deletes the key 'cherry' and its value
6. Checking for a Key:
print('apple' in my_dict) # Output: True
7. Iterating Through a Dictionary:
for key, value in my_dict.items():
print(key, value)
8. Getting the Size:
print(len(my_dict)) # Output: 3 (number of items)
9. Clearing the Dictionary:
my_dict.clear() # Removes all items
Alice True name: Alice age: 26 job: Engineer 3
{kind=link}
{kind=link}
{kind=link}
{kind=link}