 |
VOOZH | about |
|
VOOZH | about |
Web Crawler is a bot that downloads the content from the internet and indexes it. The main purpose of this bot is to learn about the different web pages on the internet. This kind of bots is mostly operated by search engines. By applying the search algorithms to the data collected by the web crawlers, search engines can provide the relevant links as a response for the request requested by the user. In this article, let's discuss how the web crawler is implemented.
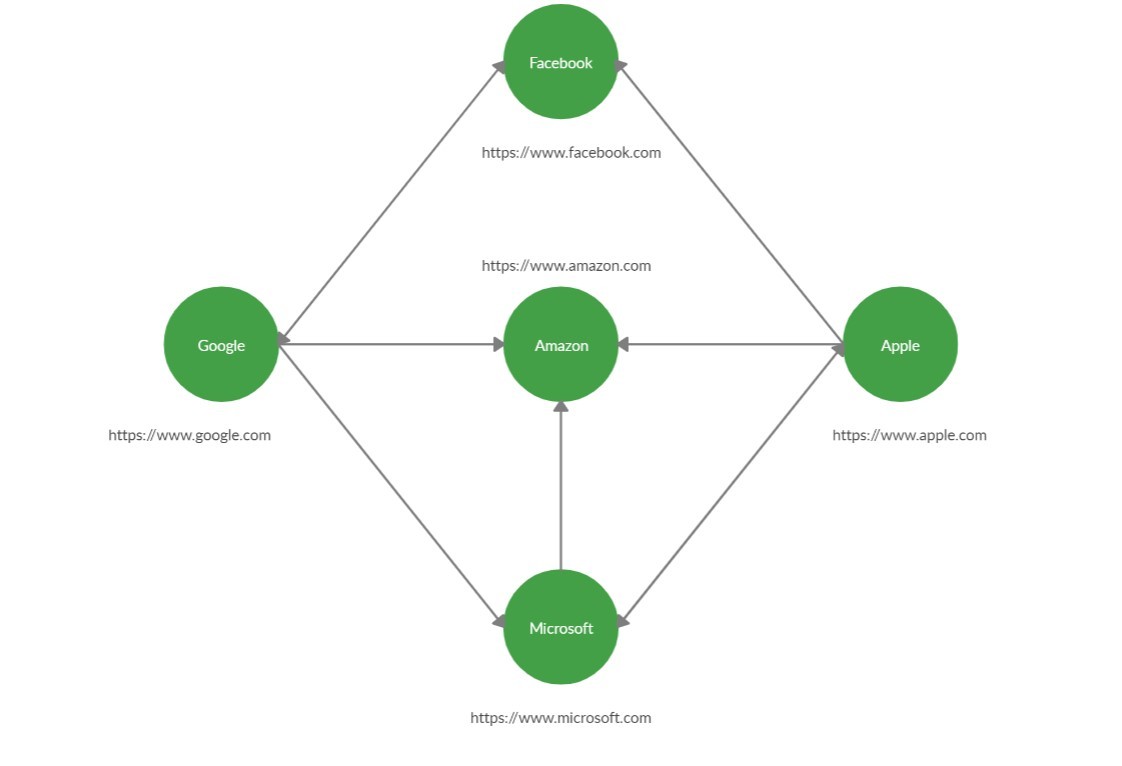
Webcrawler is a very important application of the Breadth-First Search Algorithm. The idea is that the whole internet can be represented by a directed graph:
Example:
Approach: The idea behind the working of this algorithm is to parse the raw HTML of the website and look for other URL in the obtained data. If there is a URL, then add it to the queue and visit them in breadth-first search manner.
Note: This code will not work on an online IDE due to proxy issues. Try to run on your local computer.
Output:
Website found: https://www.google.com/ Website found: https://www.facebook.com/ Website found: https://www.amazon.com/ Website found: https://www.microsoft.com/en-us/ Website found: https://www.apple.com/
Problem caused by web crawler: Web crawlers could accidentally flood websites with requests to avoid this inefficiency web crawlers use politeness policies. To implement politeness policy web crawler takes help of two parameters:
Applications: This kind of web crawler is used to acquire the important parameters of the web like:
{kind=link}
{kind=link}