 |
VOOZH | about |
|
VOOZH | about |
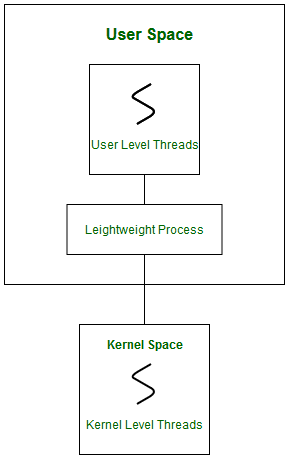
Thread scheduling refers to the mechanism that decides which thread will run and access system resources at a particular time. It ensures efficient CPU utilization and smooth execution of multiple threads. It operates at two levels.
Thread scheduling is influenced by factors such as thread priority, scheduling algorithms, and system load. It also helps improve responsiveness, fairness, and overall system performance in a multithreaded environment.
Light-weight process are threads in the user space that acts as an interface for the ULT to access the physical CPU resources. Thread library schedules which thread of a process to run on which LWP and how long. The number of LWPs created by the thread library depends on the type of application.
In real-time, the first boundary of thread scheduling is beyond specifying the scheduling policy and the priority. It requires two controls to be specified for the User level threads:
The word contention here refers to the competition or fight among the User level threads to access the kernel resources. Thus, this control defines the extent to which contention takes place. It is defined by the application developer using the thread library. It is classified as-
int Pthread_attr_setscope(pthread_attr_t *attr, int scope) The first parameter denotes to which thread within the process the scope is defined.
The second parameter defines the scope of contention for the thread pointed. It takes two values.
PTHREAD_SCOPE_SYSTEM
PTHREAD_SCOPE_PROCESS If the scope value specified is not supported by the system, then the function returns ENOTSUP.
The allocation domain is a set of one or more resources for which a thread is competing. In a multicore system, there may be one or more allocation domains where each consists of one or more cores.
Consider an operating system with three processes (P1, P2, P3) and 10 user-level threads (T1–T10) in a single allocation domain. The total CPU resources are shared among the processes, and allocation depends on contention scope, scheduling policy, thread priority, and both the thread library and system scheduler.
👁 Kernel SpaceIn this case, the contention for allocation domain takes place as follows:
PCS threads (T1, T2, T3) of process P1 compete among themselves and may share LWPs. The thread library uses preemptive priority scheduling, allowing higher-priority threads to preempt lower-priority ones within the same process. However, threads cannot preempt threads from other processes. If priorities are equal, the system scheduler decides the allocation of ULTs to LWPs.
SCS threads (T4, T5) of process P2 compete with process P1 as a whole and with SCS threads (T8, T9, T10) and PCS threads (T6, T7) of process P3. The system scheduler allocates CPU resources by treating each as a separate entity. In this case, the thread library does not control the scheduling of ULTs to kernel resources.
In a combination of PCS and SCS threads, if the system scheduler allocates 50% CPU to process P3, it may split it into 25% for PCS threads (T6, T7) and 25% for SCS threads (T8, T9, T10). PCS threads are scheduled by the thread library based on priority, while SCS threads are scheduled by the system scheduler and access kernel resources through separate LWPs and KLTs.
Note:
For every system call to access the kernel resources, a Kernel Level thread is created
and associated to separate LWP by the system scheduler. Number of Kernel Level Threads = Total Number of LWP
Total Number of LWP = Number of LWP for SCS + Number of LWP for PCS
Number of LWP for SCS = Number of SCS threads
Number of LWP for PCS = Depends on application developer Here,
Number of SCS threads = 5
Number of LWP for PCS = 3
Number of SCS threads = 5
Number of LWP for SCS = 5
Total Number of LWP = 8 (=5+3)
Number of Kernel Level Threads = 8 The second boundary of thread scheduling involves CPU scheduling by the system scheduler. The scheduler considers each kernel-level thread as a separate process and provides access to the kernel resources.
{kind=link}
{kind=link}
{kind=link}