In today's technology-driven world, it's critical to handle computing tasks across different systems efficiently. A Distributed Job Scheduler system helps coordinate the running of tasks across multiple computers in a distributed computing environment. It manages the scheduling, distributing, and tracking of these tasks, including data processing, analysis, batch job runs, and resource assignment.
1. System Requirements
This section defines the functional and non-functional requirements for the system.
1. Functional Requirements
This section describes the core features the system must support.
Job Scheduling: Enable users to submit jobs for execution at specific times or intervals.
Distributed Execution: Execute jobs across multiple worker nodes in parallel.
Monitoring and Reporting: Track job status, system health, and resource usage.
2. Non-Functional Requirements
This section outlines system qualities like performance, scalability, and reliability.
Reliability: Ensure jobs are executed correctly and on time.
Performance: Execute jobs efficiently with low latency and minimal overhead.
Scalability: Support horizontal scaling to handle many concurrent jobs.
Fault Tolerance: Handle failures with retries and recovery mechanisms.
Security: Protect data with proper authentication and access control.
2. Capacity Estimations
This section estimates system capacity in terms of traffic, storage, bandwidth, and memory requirements.
1. Traffic Estimate
This section calculates the expected number of job requests over time.
Job Submissions: Estimate jobs per unit time (e.g., 1000 jobs/hour during peak).
Helps in sizing schedulers and worker nodes.
2. Storage Estimate
This section estimates data storage requirements.
Job Metadata: If each job uses ~1 KB and there are 1 million jobs - ~1 GB storage.
Logs & Configuration: Additional storage based on logging level and retention policies.
3. Bandwidth Estimate
This section calculates network usage between system components.
Communication Overhead: If each message is 1 KB and 1000 messages/sec - ~1 MB/s bandwidth.
Important for scheduler-worker communication and coordination.
4. Memory Estimate
This section estimates RAM usage for active processing.
Job Queues: If each job takes 100 bytes and 10,000 concurrent jobs - ~1 MB memory.
Execution Context: Additional memory for job state, processing logic, and concurrency handling.
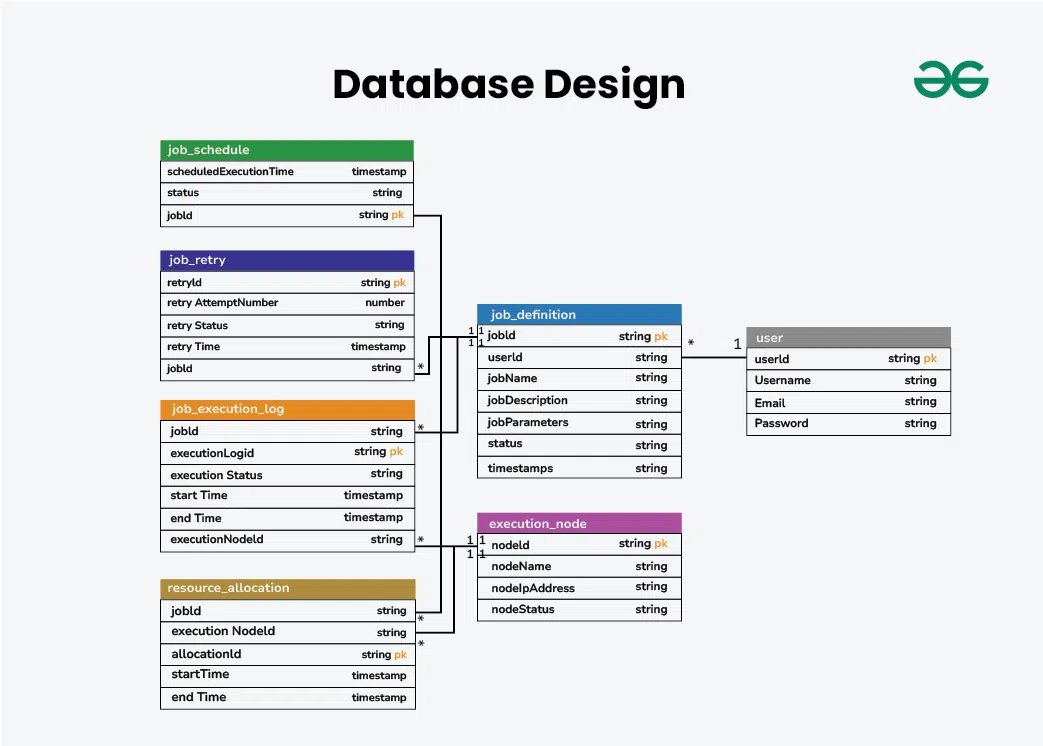
3. High-Level Design
This section explains the major components involved in the job scheduling system and how they interact.
Includes user ID, username, email, password (hashed), and other details.
Used for authentication and tracking job ownership.
6. Microservices and API
In a job scheduler designed for distributed systems, a microservices architecture offers scalability, flexibility, and modularity. It achieves this by splitting the system into independent, smaller services, each handling specific tasks. These services communicate through clearly defined APIs (Application Programming Interfaces). Here's a rundown of the microservices and APIs in such a system:
1. Job Management Microservice
This service handles job creation, scheduling, and tracking execution.
Create, update, and delete job definitions.
Schedule jobs and monitor execution status.
APIs: /jobs/create, /jobs/schedule, /jobs/status
2. Execution Node Microservice
This service manages worker nodes and their availability.

{kind=link}
.webp){kind=link}
{kind=link}
{kind=link}