 |
VOOZH | about |
|
VOOZH | about |
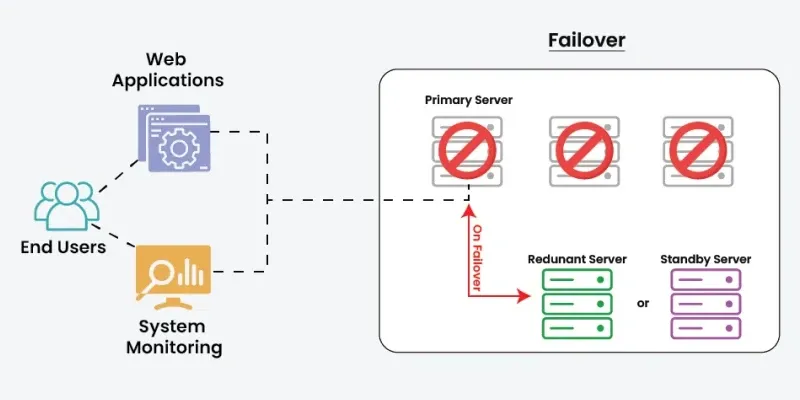
Failover Mechanism is a technique used in system design to maintain service availability when a component fails. It automatically transfers operations to a backup or standby component, ensuring minimal disruption and continuous system operation.
Example: A web application may automatically redirect traffic to a backup server if the primary server crashes. Similarly, a database cluster can switch to a standby database when the main database becomes unavailable.
This section highlights the common conditions that can trigger a failover in a system.
The following events can trigger a failover mechanism to maintain system availability and reliability.
Various types of failover exist, depending on the degree of redundancy offered and the manner in which it is implemented. Here are a few typical failover types:
A standby system or component is available but not actively operating in this kind of failover. Compared to other forms of failover, standby systems usually need more downtime because they must be initiated and brought online in the event of a failure.
In the event of a failure, a warm standby system is prepared to take over, operating partially. Even though the standby system might not be handling live traffic, it is typically partially configured and has a short downtime when brought online.
Keeping a fully functional, synchronized backup system up to date so it can take over right away in the event that the primary system fails is known as hot standby failover. The quickest recovery time with the least amount of service disruption is offered by this kind of failover.
Just one system or component is active at a time in an active-passive failover configuration, with the others operating in standby mode. The passive system kicks in when the active system malfunctions. High availability clustering and database mirroring frequently use this configuration.
Both the primary and standby systems are concurrently processing traffic and fulfilling requests in an active-active failover arrangement. The burden is automatically reassigned to the surviving operational systems in the event that one system fails. This configuration is frequently used to increase load balancing and scalability.
Failover mechanisms are essential for maintaining system reliability, availability, and business continuity when failures occur.
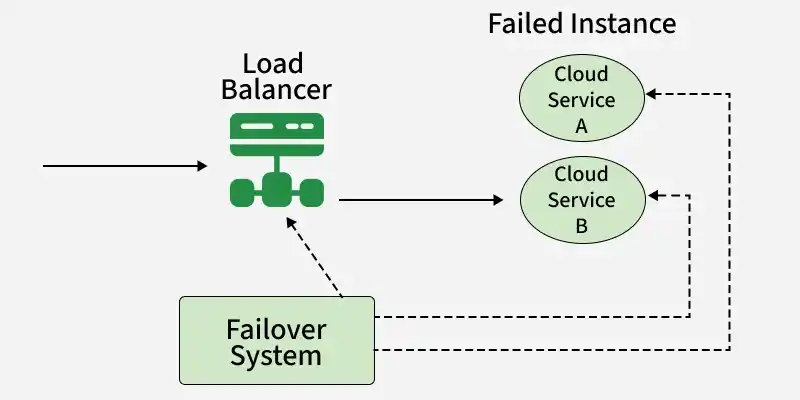
Failover architecture is a system design approach that ensures continuous service availability by automatically switching to backup resources when failures occur. It combines redundancy, monitoring, and automated recovery mechanisms to minimize downtime and maintain reliability.
Example: A cloud application may run on multiple servers in different data centers. If one server or data center fails, traffic is automatically routed to another available location, ensuring uninterrupted service.
A wide range of sectors and technologies have real-world instances of failover systems. Here are a few instances:
Google Cloud Platform enables users to distribute resources over various geographical areas by providing regional failover for its services. GCP automatically reroutes traffic to reliable resources in other regions in the case of a regional failure or outage, guaranteeing high availability.
One tool that Netflix uses in their Chaos Engineering process is called Chaos Monkey. In production scenarios, Chaos Monkey randomly ends virtual machine instances to mimic failures and assess how resilient their systems are. In order to maintain continuous service for its streaming platform, this aids Netflix in identifying flaws and strengthening its failover methods.
Incoming traffic is automatically split up among several Availability Zones or EC2 instances by Amazon Elastic Load Balancer. Apps hosted on AWS are guaranteed to be continuously available and reliable even in the event of an instance or zone failure, thanks to ELB's ability to reroute traffic to healthy instances or zones.
Global Load Balancers (GSLBs) are used by Facebook to disperse user traffic among its global data centers. To guarantee the best possible user experience and uptime, the GSLB constantly checks the health and performance of data centers and reroutes traffic away from underperforming or unavailable data centers.
Failover mechanisms are used across different systems to ensure continuous operation and minimize service disruptions during failures.
{kind=link}
{kind=link}
{kind=link}