
I’m a fan of hosting my own large language models, partly because I want to avoid sending prompts and files to external servers, and also because I don’t want to waste extra money on subscription fees every month. In fact, I’ve been hosting LLMs across my GTX 1080, RTX 3080 Ti, and MacBook M4 since late 2025, and they’ve worked well for all my AI-powered needs, be it extracting text from documents, helping me troubleshoot random errors in my server experiments, or controlling my smart home with voice commands.
But I wanted to see how far I could take my LLM escapades, so I figured I could try hosting some models on my Raspberry Pi 5 (8GB). Well, it’s not going to replace Perplexity, ChatGPT, or other cloud providers by any means. But it’s semi-decent at running tiny LLMs on its own web UI, and even remains accessible from remote networks.
{kind=link}
I ran local LLMs on a "dead" GPU, and the results surprised me
My Pascal card may not be ideal for intensive workloads, but it's more than enough for light LLM-powered tasks
I chose llama.cpp as the local LLM provider
But Ollama works well for a straightforward setup
Considering that I was working with a single-board computer that’s several magnitudes weaker than the GPUs in my home lab, I had to avoid bottlenecking my Raspberry Pi with useless packages. This meant even the desktop UI had to go if I wanted a bearable experience when running LLMs on the SBC. So, I went with the Raspberry Pi OS Lite, as it’s light enough for this project and includes essential QoL services, and enabled SSH to access it from my main PC.
With the distro configured, I had a couple of tools I could choose for managing my LLMs. I initially wanted to opt for Ollama due to its simple setup process, but it’s far from efficient and lacks sheer performance. In the end, I opted for llama.cpp, which is faster than Ollama and remains compatible with most of the AI-powered tools I use every day. Just to make things a bit easier on myself, I went with the homebrew package manager to install llama.cpp. Setting up homebrew involved installing git via sudo apt install git -y before executing the /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)" command.
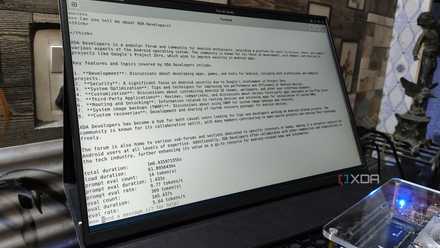
Then, I ran brew install llama.cpp and waited for the package manager to work its magic. Soon, llama.cpp finished installing, and it was time to build my LLM deck. Since the Raspberry Pi 5 is far from ideal for running high-parameter models, I initially went with the Qwen3.5-0.8B model, specifically the one from bartowski’s repo. Once I ran the command llama-cli -hf bartowski/Qwen3.5-0.8B:Q4_K_M -p "Tell me about XDA Developers" -n 128, the LLM provider pulled the model, loaded it on the Raspberry Pi, and began processing the prompt. With the 0.8B model working without any issues, I wanted to scale the parameters up and went with Llama-3.2-3B. Sadly, the Raspberry Pi would run out of memory unless I configured the context window to remain abysmally low. With nothing to lose, I ran llama-cli -hf bartowski/Llama-3.2-3B-Instruct-GGUF:Q4_K_M -p "Tell me about XDA Developers?" -n 128 -c 1024, and my tiny tinkering companion was able to process the prompt at 5.6 tokens/second. Not great, but not unusable either.
{kind=link}
I don't pay for ChatGPT, Perplexity, Gemini, or Claude – I stick to my self-hosted LLMs instead
There's no point in relying on AI tools when my local LLMs can handle everything
I wanted a neat web UI when accessing my local models
Open WebUI was my top choice
Although I consider myself a terminal warrior as much as the next server enthusiast, I didn’t want to run long commands every time I wanted to query my LLMs. So, the next step was to add a convenient interface for my LLM misadventures, which is where Open WebUI comes in. I’ve already got an instance of this app running on my home server, and I could’ve just paired it with my Raspberry Pi-powered llama.cpp workstation. But I wanted to build a completely standalone LLM-hosting RPi machine, so I spun up a Docker container for Open WebUI by executing docker run -d -p 3000:8080 -v open-webui:/app/backend/data --name open-webui ghcr.io/open-webui/open-webui:main in the Raspberry Pi's terminal.
But unlike Ollama, I still needed to enable server access on llama.cpp before I could pair it with the containerized LLM chat interface. Just to make things easier for my Raspberry Pi, I swapped back to Qwen 3.5 (0.8B) for the LLM server by running llama-server -hf bartowski/Qwen_Qwen3.5-0.8B-GGUF:Q4_K_M --host 0.0.0.0 --port 8082. Then, I logged into Open WebUI and added the IP address of my Raspberry Pi, followed by port 8082 under the Models section of the Admin Settings tab. I also tinkered around with different models, but I had to modify the num_ctx option for larger parameter models. Otherwise, my llama.cpp server would crash and leave Open WebUI marooned without any models.
Tailscale made my Raspberry Pi-flavored workstation remotely accessible
And it’s a lot safer than exposing everything to the Internet
So far, my Raspberry Pi has become a reliable 0.8B-3B LLM workstation, but I could only use it if my client devices were connected to the same network. But I wanted remote access from external networks, without the added risks of exposing ports on my home router. That’s why I went with good ol’ Tailscale, which I’d already set up on my smartphones, tablets, laptops, and other portable devices ages ago.
For the Raspberry Pi, setting up Tailscale was as simple as running the curl -fsSL https://tailscale.com/install.sh | sh command, executing sudo tailscale up, and pasting the URL generated within the terminal onto a web browser before signing in to my Tailscale account. With that, Tailscale was up and running on my Raspberry Pi, and I used the IPv4 address generated by Tailscale (with the port number 3000) to access Open WebUI after switching to the cellular network on my smartphone. With that, my self-hosted LLM control interface was now accessible outside my home lab.
But the Raspberry Pi is too underpowered for dedicated LLM-aided tasks
While it was a fun experiment using my Raspberry Pi to run AI models, this setup isn’t all that powerful for everyday tasks. After all, I’m accustomed to running Qwen 3.5 (9B) with enough context length to support multiple MCP servers on my RTX 3080 Ti – all while getting responses in a few seconds. But if all you want is an embedding model, a light chatbot, or a light LLM for edge projects, a mainline Raspberry Pi board should be good enough, provided it’s not lacking on the RAM front. In fact, I plan to look into some DIY edge computing experiments where I can utilize my pint-sized LLM-hosting workstation.
llama.cpp
Llama.cpp is an open-source framework that runs large language models locally on your computer.