
Large language models (LLMs) are incredibly useful. They're not perfect, but when prompted and used effectively, they can enhance your productivity and allow you to free up some valuable time for other tasks. Most of the grunt work happens in the cloud with ChatGPT, Claude, NotebookLM, and Copilot, to name but a few. Servers in datacenters are spun up to handle incoming requests, and you've probably read a news feature or two on just how much power these vast complexes require for handling AI. If you thought Bitcoin mining was wasting resources, you'll be stunned to see AI do just the same.
But that's where running your own LLMs can make a world of difference. Being able to load heavily optimized models onto free and open software, requiring just a PC to run it and some electricity each time the system ramps up to handle your requests. It's never going to be as smooth and capable as cloud-based AI, but so long as you keep expectations in check and learn how best to prompt each model, you can achieve some incredible results with nothing but a discrete GPU and basic desktop setup. Throw in an Nvidia GeForce RTX 5090, and you've suddenly got access to some seriously powerful models.
Using LXC-powered Ollama and Open WebUI
It's easy, quick, and what I already know
I never really bothered with using the CPU or, specifically, the integrated GPU found on the chip itself. That was until I decided I had had enough of my LLM box pulling 100 watts at idle and up to 300 watts or so when handling a request. I switched it out for a compact, low-power mini PC with a fairly mediocre processor, and the results weren't as awful as I expected. I decided to keep the mini PC running as my new LLM box, excited to see how the future further refines models and improves things with some fairly strong restrictions. Should you run LLMs on a budget-friendly mini PC? Not if you expect ChatGPT levels of responsiveness, but it can be a fun project.
I fired up Proxmox on the mini PC, checked that all available CPU cores and RAM were locked and loaded. Then, a quick trip to the Proxmox community scripts page to take the command for installing Open WebUI with Ollama. Once that was installed and configured with a dedicated IP address through OPNsense — replacing the previous Open WebUI running on a beefier PC — I was good to go. Just like many other home lab projects, there are countless ways to go about it, but I felt like Proxmox and an LXC were the best way to make the most of the available hardware.
I'm not after the best possible outcome (the CPU has a TDP of just 15W), at least not yet anyway. I know I'm going to have hardware constraints before anything relating to Ollama. Using llama.cpp may provide a performance upswing, but even then, there's the question as to whether it's worth it. This is something I'll look into later. For reference, this Minisforum U850 mini PC has the Intel Core i5-10210U CPU with four cores, and there's 16 GB of DDR4-2666 RAM. That's fairly underwhelming for a local LLM setup, especially the memory, since we're going to be CPU-bound and that RAM is super-slow compared to DDR5 and a discrete GPU.
{kind=link}
Low-power CPUs are surprisingly capable
But it has absolutely nothing on dedicated hardware
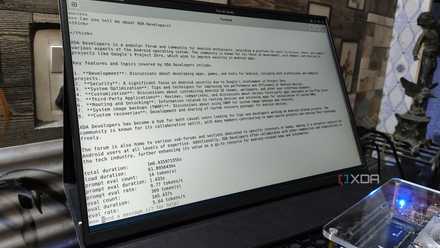
It's fairly easy to configure Open WebUI, too. After creating the first account (also with admin privileges), I downloaded qwen3:4b-14_k_m and qwen2.5coder:7b-instruct-q4_k_s, which would be my two test beds to see how capable this system is at running smaller yet highly optimized LLMs. The results were surprising, as my esteemed colleague Ayush Pande discovered when running a similar test on a mini PC with an Intel N100 CPU. For Qwen3 on my compact system, the 4B model managed around 4 tok/s with a simple question, and when asked what XDA Developers is. Not brilliant, but more than sufficient for loading queries while doing something else.
The Intel Core i5-10210U was never designed with local LLMs in mind. It's a mobile chip slapped onto a compact mini PC motherboard. Getting it to do much heavy lifting will result in slow waits, but the four physical cores and upgradable RAM do provide some wiggle room for heavier tasks, such as running local models. I found anything under 10B to be entirely possible without entering swap territory and waiting an absolute age for the CPU to handle everything. The downloaded test model qwen3:4b is great for general queries, and the slightly larger qwen2.5coder:7b is solid for assisting.
I did find it humorous how Qwen3 believes XDA does not cover LLMs and PC hardware, though it's interesting how the model relied heavily on the community forum. That's the thing with these more compact models with smaller parameter totals. You need to prompt them the right way to get the most out of the technology. It's no good simply asking whether XDA covers PC hardware and LLMs, especially after querying what XDA is. The LLM will base its follow-up response on the forum, but that's where people can struggle with interacting with local and cloud-based models.
{kind=link}
Here's how I get the most out of my self-hosted LLM, especially when limited by VRAM
Don't have an RTX 5090? No problem!
It's not a great daily driver
Though around 4 tok/s is perfectly fine for my needs with a local LLM, it's not an ideal setup for running models daily. If you expect prompt responses and high accuracy, you'll need the cloud or compelling hardware to run it all locally, but then you run into the costs of electricity. Sometimes, depending on where you reside and what PC parts you have available, cloud AI may be more affordable. For those of us who don't mind waiting a minute or two for a response and use LLMs for specific needs, even a low-power, budget mini PC with a 15W CPU like this can get the job done.
Deals on mini PCs and PC gear for local AI setups
Have the cash for a mini PC designed for running AI? Grab something like the GMKtec EVO-X2 AI.
GMKtec EVO-X2 AI Mini PC
- Brand
- GMKtec
- CPU
- AMD Ryzen AI Max+ 395
- Memory
- LPDDR5X-8000
- Operating System
- Windows 11 / Ubuntu
- Graphics
- AMD Radeon 8060S