 |
VOOZH | about |
|
VOOZH | about |
This article was published as a part of the Data Science Blogathon.
Source: Canva|Arxiv
In 2018 GoogleAI researchers developed Bidirectional Encoder Representations from Transformers (BERT) for various NLP tasks. However, one of the key limitations of this technique was the quadratic dependency, due to which the BERT-like model can handle sequences of 512 tokens at a time because of their full attention mechanism. To overcome this, Manzil Zaheer, Guru Guruganesh, Avinava Dubey, et al proposed BigBird having a sparse attention mechanism that can handle sequences of length up to 8x of what was previously possible by similar hardware.
In this article, we will take a look at the proposed work in greater detail.
Now, let’s dive in!
BigBird employs a sparse attention mechanism that turns the quadratic dependency of the transformer-based model into a linear one. It is a universal approximator of sequence functions that retain the properties of the quadratic, full-attention model.
With the help of BigBird and its Sparse attention mechanism, the complexity of BERT (O(n2)) is reduced to O(n). As a result, the input sequence limited to 512 tokens is now increased to 4096 tokens (8 * 512). Hence, BigBird can handle longer sequences of length ie. up to 8x of what was previously possible by similar hardware.
The capability to accommodate longer context allows BigBird to perform dramatically better on a variety of NLP tasks, including question answering and summarising.
The key advancement in Transformers includes a self-attention mechanism, which can be estimated in parallel for each token of the input sequence, eliminating the sequential dependency in recurrent neural networks (like LSTM). This parallelism enables Transformers to leverage the full potential of contemporary SIMD hardware accelerators like GPUs and TPUs, hence facilitating the training of NLP models on datasets of unprecedented size. Pre-training transformers on a large-scale dataset have led to significant improvement in low data regime downstream tasks and tasks with sufficient data and thus has been a major force behind the widespread use of transformers in contemporary NLP.
The self-attention mechanism solves constraints related to the sequential nature of RNNs by enabling each token in the input sequence to attend independently to every other token in the sequence. However, the full self-attention have high computational and memory requirement that is quadratic in the sequence length. Moreover, it was observed that while the corpus size can be huge, the sequence length, which provides the context is minimal. Using currently available hardware and model sizes, input sequences of length 512 tokens can be handled simultaneously. This limits its direct applicability to tasks that require a larger context, like question-answering (QA), document classification, etc.
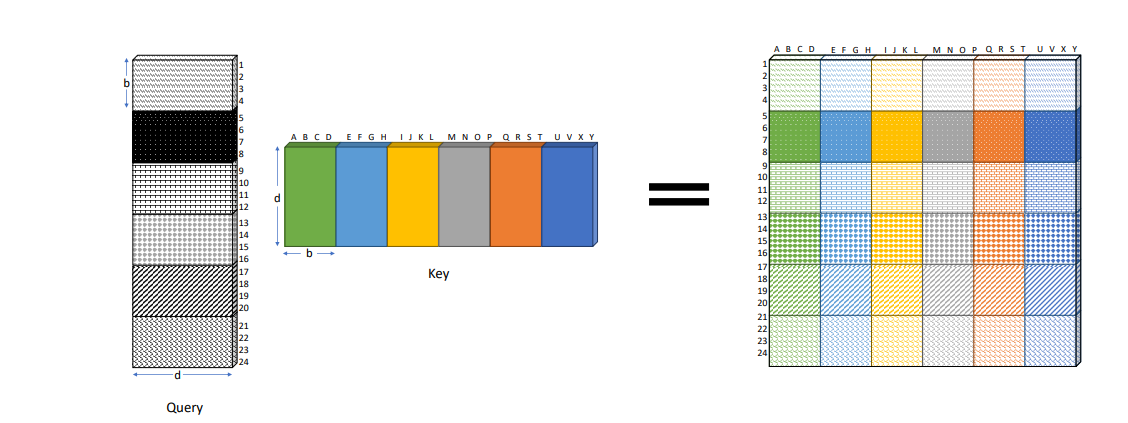
Figure 1: Diagram illustrating Full all-pair attention, which is obtained by direct matrix multiplication between the query
and key matrix.
As we briefly discussed in the prior sections, transformer-based models like BERT have a core limitation: the quadratic dependency (mainly in terms of memory) on the sequence length due to their full attention mechanism. Consequently, quadratic dependency on the sequence length limits the context size of the model.
These limitations lead us to two questions: 1) Can we obtain the empirical advantages of a fully quadratic self-attention scheme with fewer inner products? 2) Do the sparse attention mechanisms sustain the expressivity and adaptability of the original network?
BigBird addresses the aforementioned problems by using a sparse attention mechanism that scales linearly. As a result, contexts can be drastically scaled up from 512 tokens (present in most BERT models) to 4,096 in BigBird. This is especially helpful in many tasks where long dependencies need to be preserved eg. text summarization.
The authors drew inspiration from graph sparsification methods and studied where the proof for the expressiveness of Transformers fails when full attention is relaxed to form the proposed attention pattern. This knowledge helped in developing BIGBIRD.
BigBird is a sparse-attention-based transformer that extends transformer-based models like BERT to 8 times longer sequences so that empirical advantages of a fully quadratic self-attention scheme are retained with fewer computations.
The building blocks of the sparse-attention mechanism used in BIGBIRD are as follows:
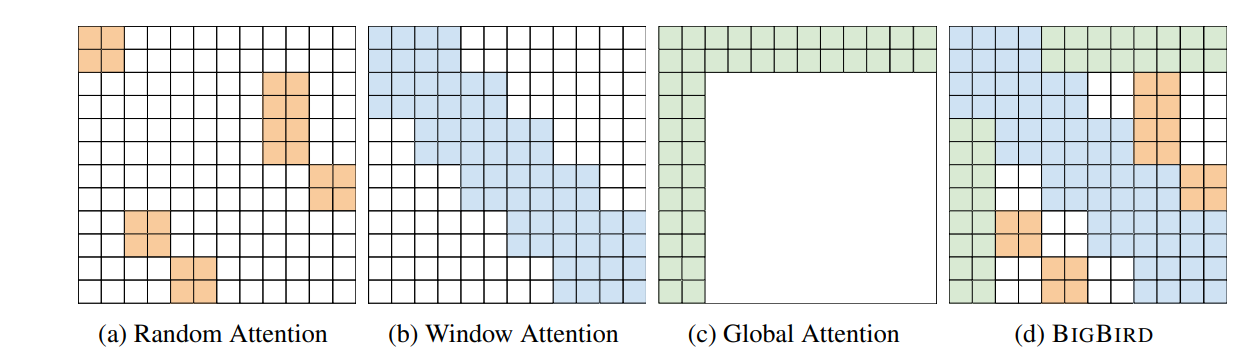
Figure 2: Diagram illustrating different types of attention mechanisms. The last one is BigBird’s sparse attention mechanism.
Let’s take a look at each type of attention mechanism in more detail.
1. Random Attention: Figure 2a illustrates the random attention mechanism, where r=1 with block size 2. In this, every query block randomly attends to random key (r) blocks, meaning in Figure 2a, each query block of size 2 attends to a key block of size 2 (randomly).
2. Window local attention: While creating the block, it is ensured that the number of query blocks
and the number of key blocks are the same. This aids in defining the block window
attention. Each query block with index j attends to the key block with index j − (w − 1)/2 to
j + (w − 1)/2, including key block j. Figure 2b shows sliding window attention with w = 3 and block size 2, meaning each query block j attends to key block j − 1, j, j + 1. This ensures that every query attends to at least one block of keys of size b on each side and a maximum of two blocks.
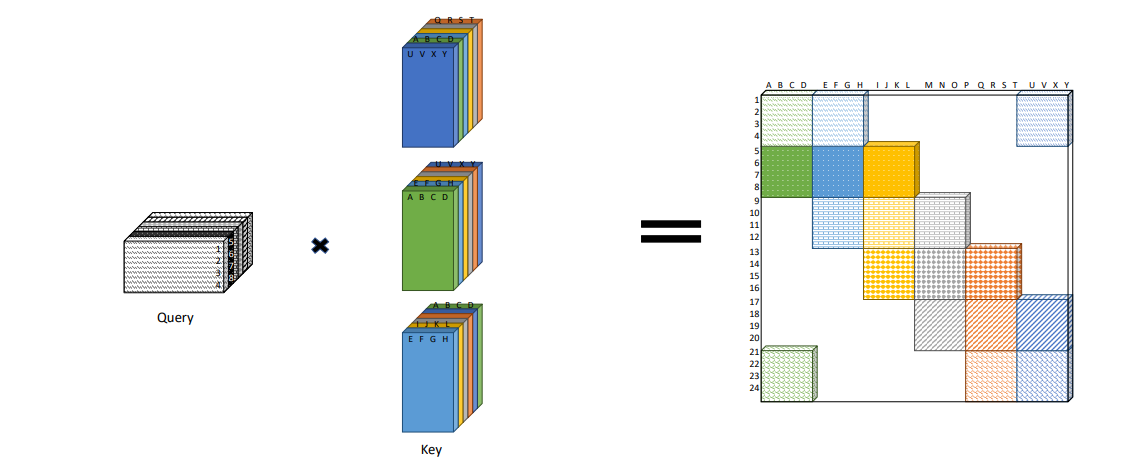
Figure 3 further illustrates the idea behind the window attention mechanism in detail for different parameters.
Figure 3: Diagram illustrating how window local attention is obtained (in general) by “blocking” the query and key matrix, copying the key matrix, and rolling the resulting key tensor.
3. Global attention: Global attention is computed in terms of blocks. Figure 2c illustrates the global attention mechanism with g = 1 and block size 2. For BIGBIRD-ITC, this suggests that
one query and key block attend to everyone.
Figure 2d illustrates the resulting overall attention mechanism used in BigBird. To sump up, we can say that the final attention mechanism for BigBird has the following three properties:
– queries attend
to random keys (r)
– each query attends to w/2 tokens to the right of its location and w/2 to the left of
its location
– contains global tokens (g) that can be from already existing tokens or extra added tokens
Unfortunately, when it comes to the computation of this attention score by simply multiplying arbitrary pairs of key and query vectors, it usually requires the use of the gather operation, which turns out to be inefficient. Upon examination of the global attention and window attention, it was found that these attention scores can be calculated without using a gather operation.
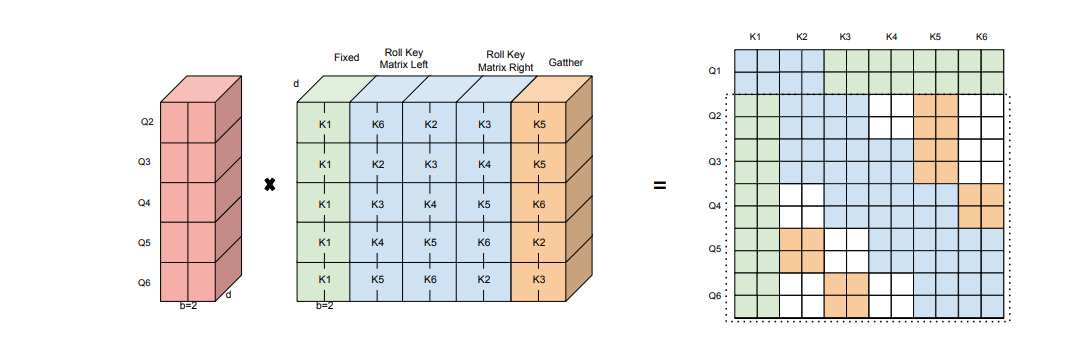
Figure 4: Overview of BigBird attention computation.
BigBird Attention Computation: Structured block sparsity aids in compactly packing the operations of sparse attention, thereby making the method efficient on GPU or TPU. Figure 4 shows the transformed dense query and key tensors on the left. The query tensor is obtained by blocking and reshaping, whereas the final key tensor is obtained by concatenating three transformations: The first green columns (which corresponds to global attention) is fixed. The center blue columns (corresponding to
window local attention) are obtained by aptly rolling. A computationally inefficient gather operation is supposed to be used for the last orange columns (which correspond to random attention).
Dense multiplication between the query and key tensors effectively computes the sparse attention pattern (except for the first-row block, which is calculated using direct multiplication). The resulting matrix on the right (in Figure 4) is identical to that shown in Figure 2d.
Some of the applications of BigBird are as follows:
1. Genomics Processing: Genomics sequence is provided as input to the encoder for tasks like methylation analysis, predicting functional impacts of non-coding variants, etc.
2. Question Answering and Long Document Summarization: BigBird can now handle up to 8 times larger sequence lengths than BERT, making it suitable for NLP tasks like answering and summarizing long documents.
3. Search Engine: Since BigBird can handle long context better than BERT, it can be used in search engines.
The sparse attention mechanisms can’t universally substitute dense attention
mechanisms. Moreover, switching to a sparse attention mechanism does incur a cost.
For this, we will first install and import all the required packages. Following that, we will load the model (“google/bigbird-roberta-base”) and the corresponding tokenizer with the help of BigBirdMaskedLM and AutoTokenizer classes. In addition, we will also load the “squad_v2” dataset, and then we will decode the masked token at the end.
!pip install -q transformers datasets sentencepiece
import torch from transformers import AutoTokenizer, BigBirdForMaskedLM from datasets import load_dataset
model_name = "google/bigbird-roberta-base"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = BigBirdForMaskedLM.from_pretrained(model_name)
squad_ds = load_dataset("squad_v2", split="train")
#Randomly selecting a long article random_long_article = squad_ds[81515]["context"]
#Adding mask token
add_mask_token = random_long_article.replace("maximum", "[MASK]")
inputs = tokenizer(add_mask_token, return_tensors="pt")
with torch.inference_mode(): logits = model(**inputs).logits
# Retrieving index of the [MASK] mask_token_index = (inputs.input_ids == tokenizer.mask_token_id)[0].nonzero(as_tuple=True)[0] predicted_token_id = logits[0, mask_token_index].argmax(axis=-1) tokenizer.decode(predicted_token_id)
>> Output: “maximum”
Link to Colab Notebook: https://bit.ly/3fgOYXN
To sum it up, in this article, we learned the following:
That concludes this article. Thanks for reading. If you have any questions or concerns, please post them in the comments section below. Happy learning!
Link to Research Paper: https://arxiv.org/pdf/2007.14062.pdf
Link to Colab Notebook: https://bit.ly/3fgOYXN
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I'm a Researcher who works primarily on various Acoustic DL, NLP, and RL tasks. Here, my writing predominantly revolves around topics related to Acoustic DL, NLP, and RL, as well as new emerging technologies. In addition to all of this, I also contribute to open-source projects @Hugging Face.
For work-related queries please contact: [email protected]
GPT-4 vs. Llama 3.1 – Which Model is Better?
Llama-3.1-Storm-8B: The 8B LLM Powerhouse Surpa...
A Comprehensive Guide to Building Agentic RAG S...
Top 10 Machine Learning Algorithms in 2026
45 Questions to Test a Data Scientist on Basics...
90+ Python Interview Questions and Answers (202...
8 Easy Ways to Access ChatGPT for Free
Prompt Engineering: Definition, Examples, Tips ...
What is LangChain?
What is Retrieval-Augmented Generation (RAG)?
Edit
Resend OTP
Resend OTP in 45s
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}