 |
VOOZH | about |
|
VOOZH | about |
Hadoop is an open-source framework overseen by the Apache Software Foundation (ASF). Written in Java, it is specifically designed to store and process massive datasets across clusters of commodity hardware.
The Big Data Challenge: Managing Big Data presents two primary hurdles:
Traditional approaches, such as Relational Database Management Systems (RDBMS), are largely insufficient for this task due to the high heterogeneity and volume of Big Data. Hadoop bridges this gap by offering advanced storage and processing capabilities.
Core Components:
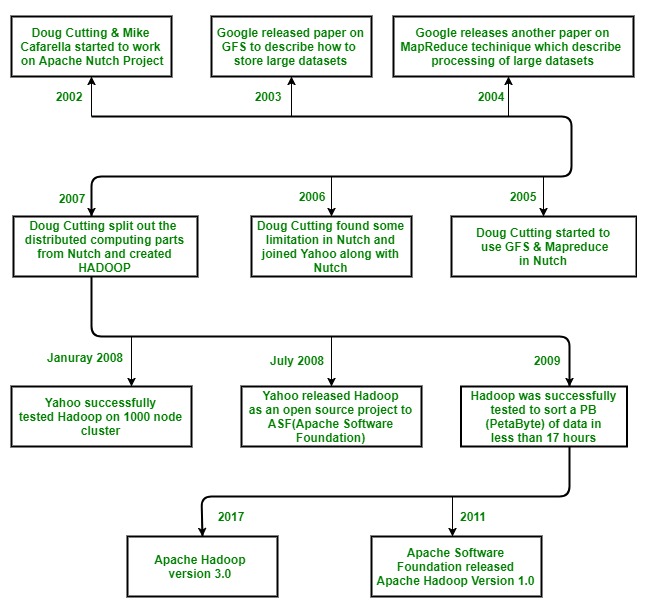
The development of Hadoop was a multi-year journey driven by the need for cost-effective, massively scalable web search technologies.
The journey began with Doug Cutting and Mike Cafarella working on the Apache Nutch project, an ambitious attempt to build a search engine capable of indexing 1 billion web pages.
They quickly realized the traditional architecture was financially unviable, requiring an estimated $500,000 in hardware and $30,000 in monthly running costs. Furthermore, by 2005, Nutch was bottlenecked, limited to clusters of only 20-to-40 nodes. They needed a breakthrough in distributed storage and processing.
What's in a Name? > Doug Cutting named the newly formed project "Hadoop" after his son’s yellow toy elephant. He chose it because it was a unique, easy-to-pronounce word without any prior technical associations.
{kind=link}
{kind=link}
{kind=link}