Branched RAG is an extension of Retrieval-Augmented Generation (RAG) where the system explores multiple retrieval or reasoning paths instead of a single linear process. By considering different sources or perspectives before generating a response, it helps produce more accurate, structured and context-aware answers compared to traditional RAG which typically follows only one retrieval path.
Enables parallel retrieval and reasoning paths
Improves performance on multi‑facet or ambiguous queries
Useful for complex QA, analysis and decision‑support systems
Aggregating results from several branches helps generate balanced and well-informed outputs.
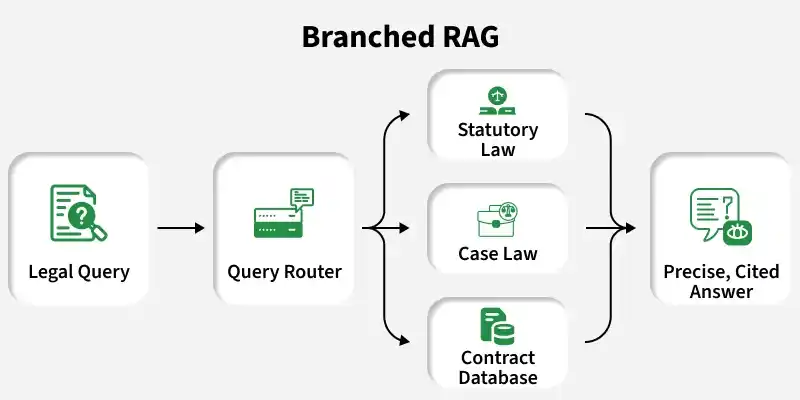
Branched RAG is an advanced technique where a user query is divided into multiple paths or branches instead of following a single retrieval flow. In this approach:
A single query is split into multiple reasoning or retrieval branches.
Each branch retrieves different but relevant information from various sources.
The model processes these branches independently to explore multiple perspectives.
The outputs from all branches are then combined to produce a more accurate and well-informed final response.
Components of Branched RAG
The main components of Branched RAG are:
External Knowledge Source: Stores domain specific or general information such as documents, databases, APIs or knowledge bases used for retrieval.
Branch Generator: Breaks the user query into multiple reasoning paths or sub-queries to explore different perspectives.
Embedding Model: Converts text into numerical vector representations that capture semantic meaning.
Vector Database: Stores embeddings and enables fast similarity search for retrieving relevant information.
Branch Retrievers: Each branch independently retrieves relevant documents based on its specific context or interpretation.
Branch Processing Module: Processes and analyses retrieved information separately for each branch.
Aggregation Layer: Combines outputs from multiple branches to create a unified understanding.
LLM (Generator): Generates the final response using combined information from all branches.
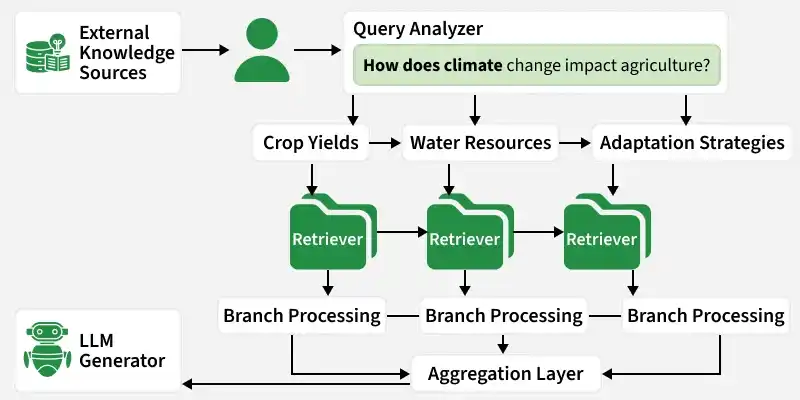
The system receives a user query and analyses its intent, scope and keywords to determine whether the query contains multiple aspects, sub-questions or reasoning paths.
2. How the Query Is Split (Branch Creation)
After understanding the query, it is divided into multiple logical branches:
1. The query is decomposed into independent sub-queries based on intent, entities or reasoning requirements
2. Each branch targets a specific sub-topic or interpretation
3. Branching can be based on:
Different concepts in the query
Multiple entities or timeframes
Alternative reasoning paths like facts, comparisons, causes, examples, etc
This allows the system to explore multiple directions instead of following a single retrieval path.
3. Parallel Retrieval
Each branch retrieves relevant information independently from external sources such as:
Vector databases
Knowledge graphs
Documents or APIs
This happens in parallel, reducing latency and increasing information.
4. Independent Processing
The retrieved information from each branch is processed separately:
Each branch performs focused reasoning
Noise is reduced by keeping contexts isolated
The model can apply deeper analysis specific to that sub-topic
5. How Outputs Are Aggregated (Aggregation and Fusion)
Once all branches finish processing, their outputs are combined using aggregation logic:
Relevant results are ranked or scored based on relevance
Redundant or conflicting information is filtered
Key insights from each branch are merged into a single coherent context
This step ensures completeness without duplication.
6. Final Response Generation
The LLM generates the final answer using the aggregated context:
Combines insights from all branches
Maintains logical flow and consistency
Produces a context-aware and well-rounded response
Splits query into multiple branches for retrieval.
Query Processing
Processes query as one unit.
Breaks query into sub-parts and analyses separately.
Information Coverage
Limited to one retrieval context.
Broader coverage from multiple sources.
Complexity
Simple and easy to implement.
More complex due to branching logic.
Performance on Complex Tasks
Best for straightforward queries.
Better for multi-step or complex problems.
Use Cases
Basic chatbots, document search.
Research assistants, advanced reasoning tasks.
What Problems does Branched RAG Solve?
Single Perspective Limitation: Traditional RAG follows one retrieval path, which may miss alternative viewpoints. Branched RAG explores multiple reasoning paths to capture broader context.
Incomplete Information Retrieval: A single retrieval step may overlook important data. Multiple branches increase the chances of finding relevant information.
Complex Query Handling: Multi-topic or multi-step questions benefit from branching, where different aspects of a query are handled separately.
Improved Reasoning Quality: Parallel processing of branches allows deeper analysis and more structured responses.
Reduced Bias and Errors: Combining results from multiple branches helps reduce reliance on a single source, improving reliability.
Better Context Awareness: Multiple retrieval paths help maintain richer context, especially for complicated or analytical tasks.
Challenges
Despite its advantages, Branched RAG introduces several challenges:
System Complexity: Managing multiple branches and combining results increases architectural complexity.
Higher Computational Cost: Running parallel retrieval and reasoning processes may require more resources.
Latency Issues: Additional processing steps can increase response time compared to traditional RAG.
Aggregation Difficulty: Effectively merging outputs from different branches requires careful design.
Applications
Some practical applications of Branched RAG :
Advanced Question Answering Systems: Enables AI assistants to analyse multiple perspectives before generating answers.
Research and Knowledge Exploration: Useful for analysing large amounts of information from different sources simultaneously.
Decision Support Systems: Evaluates multiple reasoning paths to help generate balanced conclusions.
Enterprise Knowledge Management: Retrieves information across multiple departments or datasets for comprehensive responses.
Content Generation and Analysis: Produces richer and more structured outputs by combining insights from different branches.

{kind=link}
{kind=link}
{kind=link}