 |
VOOZH | about |
|
VOOZH | about |
Data Analysis involves collecting, transforming and organizing data to generate insights, support decision making and solve business problems.
NumPy is a Python library used for fast and efficient numerical computations. It provides multidimensional arrays and built in functions that simplify data analysis, mathematical operations and large scale data processing.
NumPy arrays store elements of the same data type and support multiple dimensions. The number of dimensions is called rank and the size of each dimension is called shape.
Output:
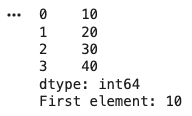
Arrays can be created using lists, tuples or built in functions like zeros, ones, arange and empty.
Output:
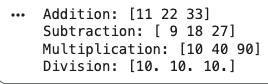
NumPy allows efficient element wise operations on arrays, making numerical computations faster and more optimized compared to traditional Python methods.
Output:
Indexing is used to access individual elements in an array using their position. It works similarly to Python lists but is more useful for multi dimensional data.
Output:
Slicing allows accessing a range of elements from an array. It is useful for working with subsets of data.
Output:
Broadcasting allows operations between arrays of different shapes without explicitly resizing them, improving efficiency and reducing code complexity.
Output:
Pandas is a Python library used for handling structured (relational or labeled) data. Built on top of NumPy, it provides flexible data structures and tools for data manipulation, analysis and time series operations.
A Series is a one dimensional labeled array capable of holding any data type (integers, strings, floats, etc.). Each element has an associated index.
Output:
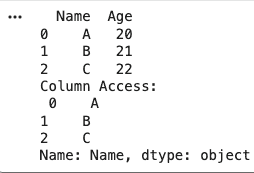
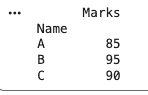
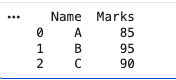
A DataFrame is a two dimensional labeled data structure with rows and columns, similar to a table or spreadsheet.
Output:
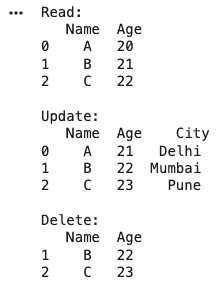
Pandas allows easy Create, Read, Update and Delete operations on data stored in CSV files, making it practical for real-world datasets. It is known as CRUD Oprations.
Output:
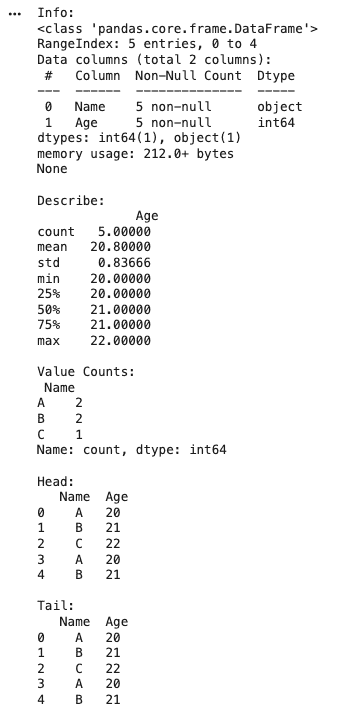
Pandas provides quick methods to understand the structure, summary and content of a dataset. These functions help in exploring data before analysis.
Output:
Pandas provides multiple operations to efficiently select, organize and transform data for analysis.
Indexing and Selection
Indexing and Selection are used to access specific rows, columns or subsets of data.
Output:
Grouping and Aggregation
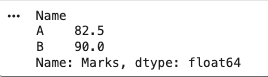
Grouping and Aggregation Groups data based on a column and applies aggregate functions like mean, sum, etc.
Output:
Merging and Joining
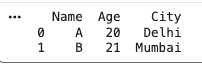
Merging and Joining combines multiple DataFrames based on common columns.
Output:
Sort
Sorts data based on column values.
Output:
Filter
Filter selects data based on conditions.
Output:
set_index
Sets a column as the index of the DataFrame.
Output:
reset_index
Resets the index back to default numeric indexing.
Output:
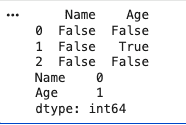
Working with missing data is a key step in EDA to ensure data quality and accurate analysis. It involves identifying missing values and applying appropriate techniques to handle them without affecting results.
Checking Missing Data
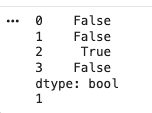
Used to detect null values present in the dataset.
Output:
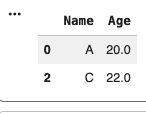
Dropping Missing Values
There are different methods to handle missing data based on requirements, here we just drop the missing values.
Output:
Duplicate values can lead to incorrect analysis and biased results. Identifying and removing duplicates is an important step in data cleaning during EDA.
Checking Duplicate Values
Used to detect duplicate rows in the dataset.
Output:
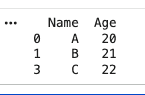
Handling Duplicate Values
Remove duplicate rows to clean the dataset.
Output:
Outliers are extreme values that differ significantly from other data points. Detecting and handling them is important to improve data quality and model performance during EDA.
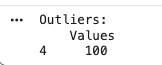
IQR (Interquartile Range) Method
Outliers are values below Q1 - 1.5 IQR or above Q3 + 1.5 IQR.
Output:
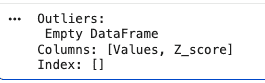
Z-Score Method
Outliers are values with Z-score greater than 3 or less than -3.
Output:
Handling Outliers
Outliers can be handled by removing or capping depending on the use case.
Output:
Matplotlib is a widely used Python library for creating visualizations and graphs. It helps in understanding patterns, trends, and relationships in data through visual representation during EDA.
Pyplot
Pyplot is a Matplotlib module that provides a simple interface to create and customize plots. It helps in generating figures, adding labels, and displaying visualizations.
Output:
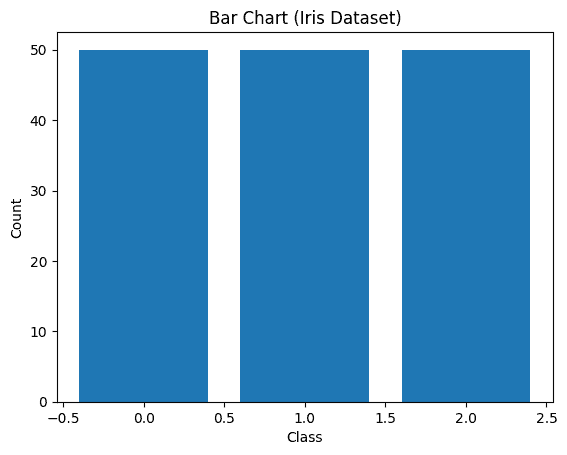
Bar chart
A bar chart is used to compare values across different categories using rectangular bars. The height or length of each bar represents the value of that category.
Output:
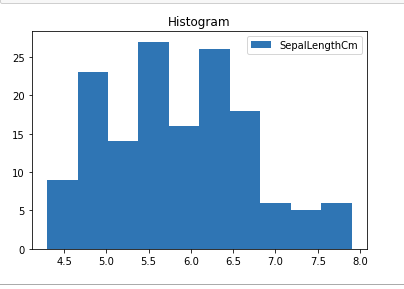
Histograms
A histogram is used to show the distribution of data by grouping values into bins (ranges). The X-axis represents the bins, and the Y-axis shows the frequency of values in each bin.
Output:
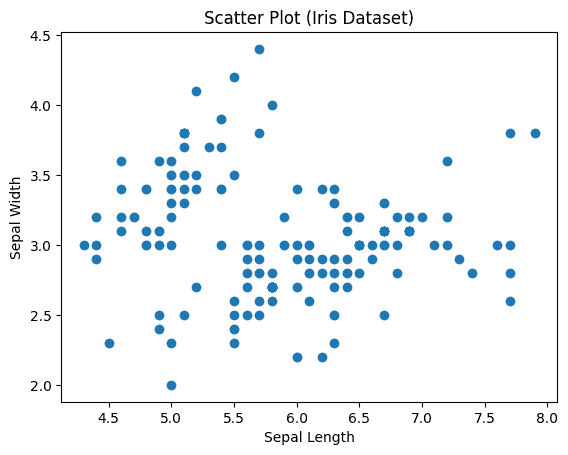
Scatter Plot
Scatter plots are used to observe relationship between variables and uses dots to represent the relationship between them. The scatter() method in the matplotlib library is used to draw a scatter plot.
Output:
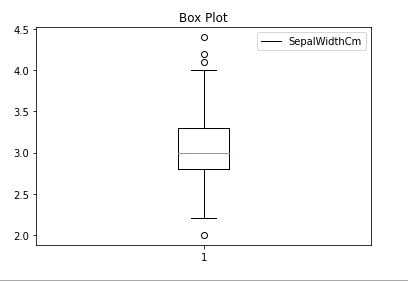
Box Plot
A boxplot (box-and-whisker plot) is used to visualize data distribution and identify outliers using quartiles.The minimum is shown at the far left of the chart, at the end of the left ‘whisker’
Output:
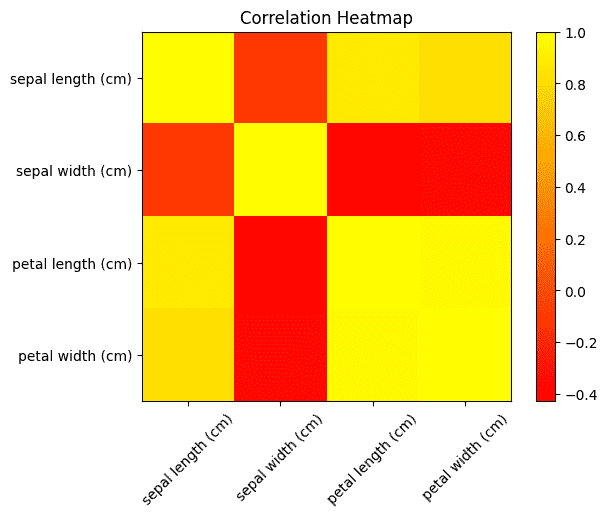
Correlation Heatmaps
A correlation heatmap is a visual tool that shows relationships between variables using colors. It is based on a correlation matrix, where each cell represents how strongly two variables are related.
Output:
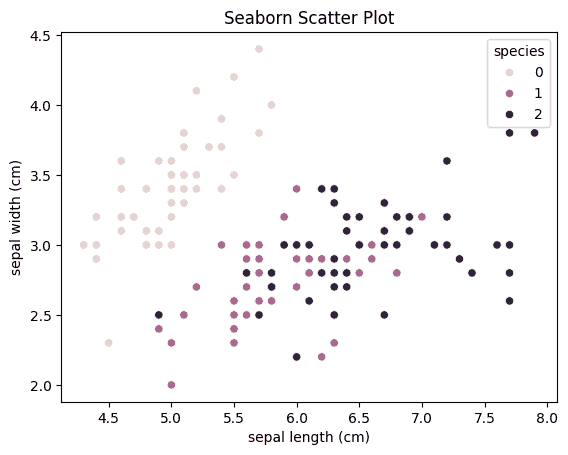
Seaborn is a high level visualization library built on Matplotlib that provides more attractive and informative statistical plots.
Scatter Plot
Output:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
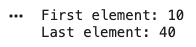{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
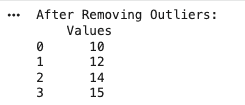{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}