 |
VOOZH | about |
|
VOOZH | about |
Pandas filter() function allows us to subset rows or columns in a DataFrame based on their labels. This method is useful when we need to select data based on label matching, whether it's by exact labels, partial string matches or regular expression patterns. It works with labels rather than the content of the DataFrame which makes it a quick and efficient way to focus on specific parts of our data.
Lets see a basic example:
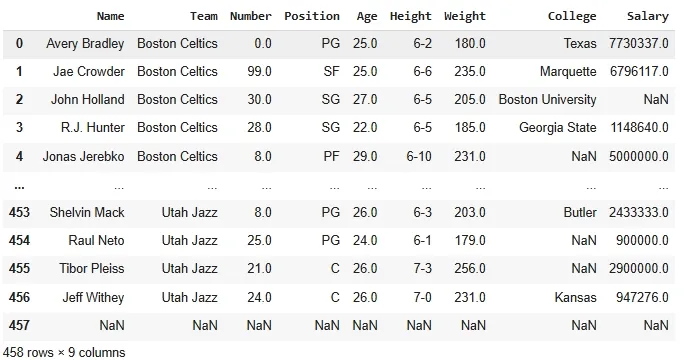
Here we are using NBA dataset which you can download it from here.
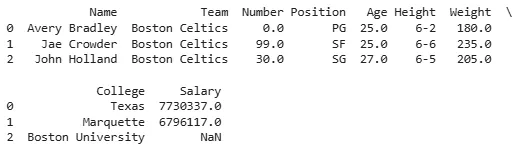
We will first load the NBA dataset to see how to use filter() function.
Output:
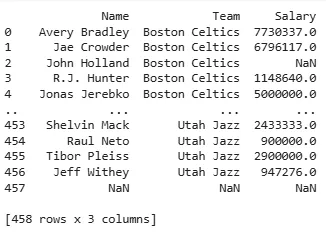
Now we use filter() to select the "Name", "Team" and "Salary" columns by specifying the column labels in the items parameter.
Output:
DataFrame.filter(items=None, like=None, regex=None, axis=None)
Parameters:
Return: Return type is the same type as the input i.e a DataFrame or Series depending on the context.
We can filter columns based on a substring in the column labels using the like parameter.
Output:
This filters columns whose names contain the letter 'a'. The like parameter helps us to match columns based on a substring in their label names.
Regular expressions allow for more complex column selection based on patterns in column labels.
Output:
Here, the regular expression [sS] matches any column name that contains the letter 'S' or 's' which allows us to filter columns based on pattern matching.
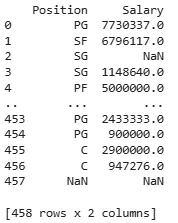
We can filter rows based on their index labels using the axis=0 parameter.
Output:
This example filters the rows by their index labels. We are selecting the rows with index labels 0, 1 and 2 by specifying them in the items parameter with axis=0.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}