 |
VOOZH | about |
|
VOOZH | about |
Understanding data distribution is essential in data analysis. Skewness helps identify whether data is symmetric or skewed, while kurtosis shows how heavy or light the tails are. In Python these measures can be computed quickly using built-in libraries.
Skewness is a statistical measure used to describe the shape of a data distribution. It helps identify whether the distribution is symmetric or asymmetric, focusing on how data is spread around the central value rather than relying only on frequency distribution.
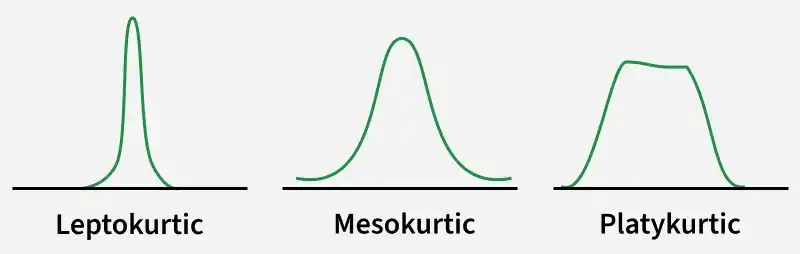
Kurtosis is a statistical measure that describes how strongly a distribution is affected by extreme values (outliers). It mainly reflects the heaviness of the tails compared to a normal distribution. While kurtosis is linked with the peak shape, it does not directly measure whether the distribution is sharp or flat at the center.
Here we import the necessary libraries for numerical computation, statistical analysis and visualization.
We use the built-in diamonds dataset from Seaborn and extract the price feature for analysis.
SciPy provides an inbuilt skew() function to compute skewness directly.
Syntax:
scipy.stats.skew(array, axis=0, bias=True)
Parameters:
Return Type: Skewness value of the data set, along the axis.
Output:
Skewness using SciPy: 1.6183502776053016
A positive skewness value indicates that the distribution is right-skewed, meaning a longer tail on the right side.
Pearson’s Second Coefficient of Skewness measures skewness using the relationship between the mean, median and standard deviation. If the mean is greater than the median, the skewness value becomes positive, indicating a right-skewed distribution, while a negative value indicates left skewness.
Output:
Pearson's Second Skewness: 1.1518908587086387
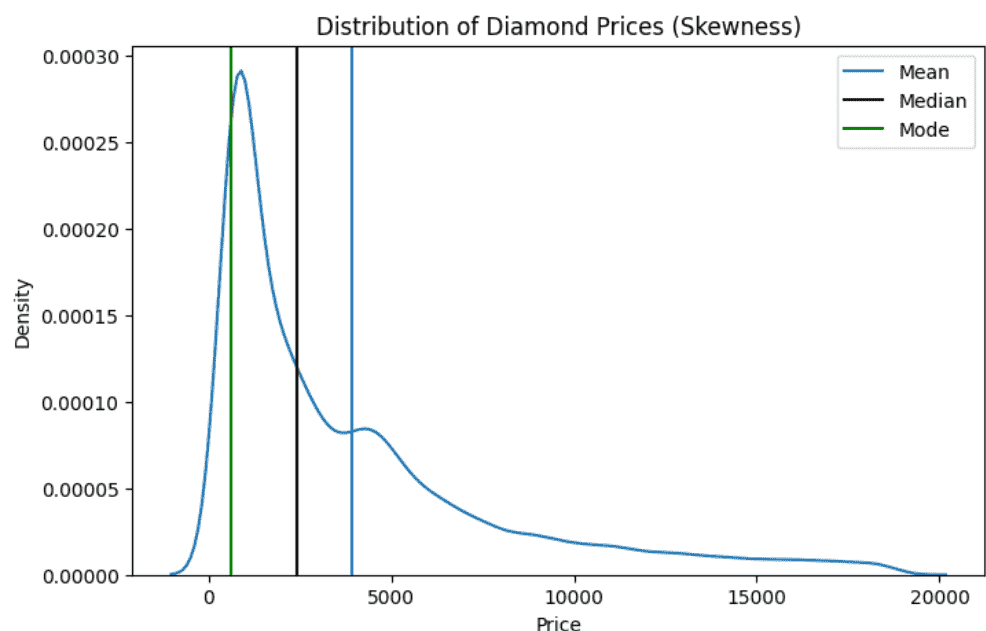
This step visualizes the distribution of diamond prices using a KDE plot and highlights the mean, median and mode with vertical lines to understand the skewness visually.
Output:
Since the mean lies to the right of the median and mode, the distribution is positively skewed, confirming the numerical skewness results.
We import the kurtosis function from SciPy, which provides an inbuilt method to calculate kurtosis.
This step computes kurtosis using Fisher’s definition, where a normal distribution has a kurtosis value of 0.
Syntax:
scipy.stats.kurtosis(array, axis=0, fisher=True, bias=True)
Parameters:
Return Type: Kurtosis value of the normal distribution for the data set.
Output:
Kurtosis using SciPy: 2.177382669056634
A positive kurtosis value indicates a leptokurtic distribution, meaning heavy tails and a higher presence of extreme values.
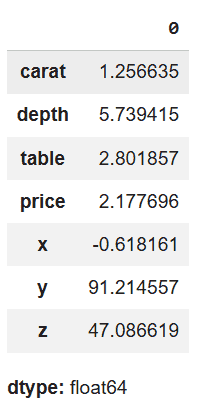
This step calculates kurtosis for all numeric columns to compare tail behavior across features.
Output:
Features with higher kurtosis values have heavier tails, indicating more outliers compared to features with lower kurtosis.
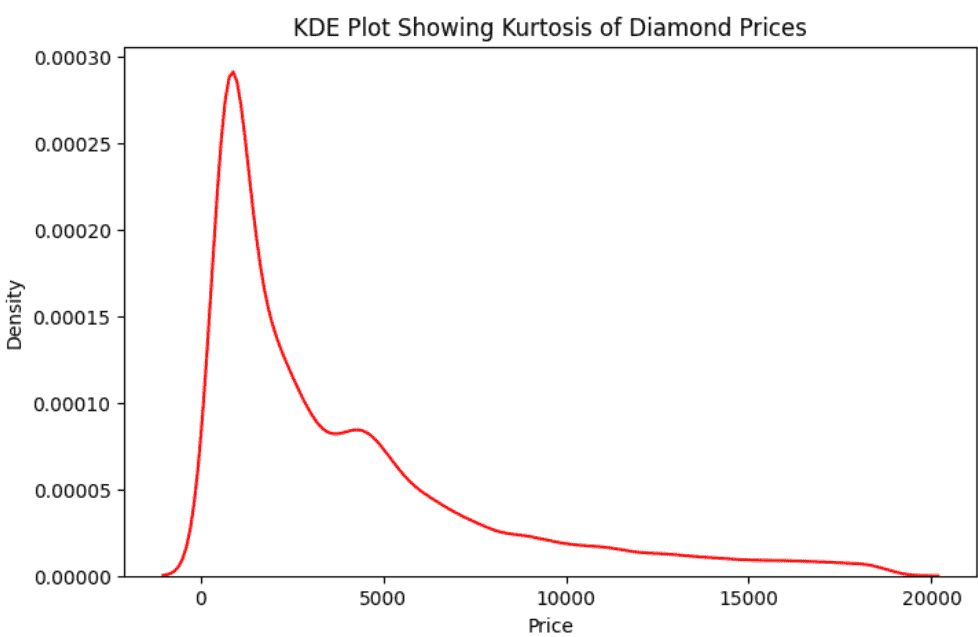
A KDE plot is used to observe the peak and tail behavior of the distribution.
Output:
The sharp peak and heavy tails in the plot indicate high kurtosis, supporting the numerical kurtosis values.
You can download full code from here
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}