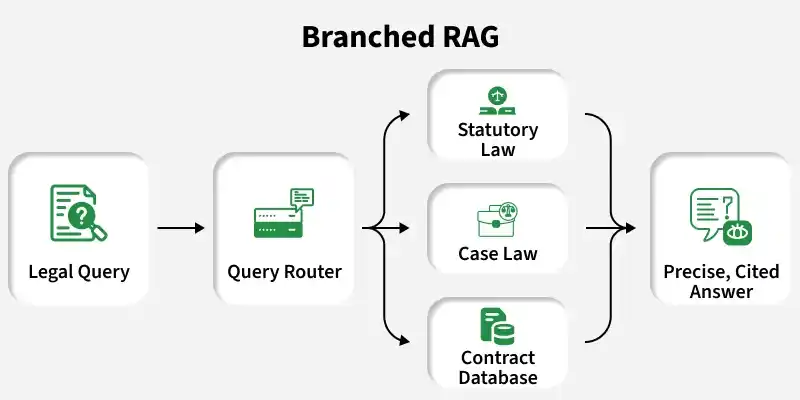
Branched Retrieval‑Augmented Generation (Branched RAG) is a type of RAG system where multiple retrieval paths operate in parallel to handle complex queries. Each branch retrieves and processes information independently and the combined outputs improve answer accuracy and reasoning depth.
Enables parallel retrieval from multiple sources or contexts
Improves response quality for complex or multi‑part queries
Enhances flexibility and scalability in RAG‑based systems
Install the following libraries to set up the environment for implementing Branched RAG using LangGraph:
langchain: Core framework for building applications with large language models.
langgraph: Manage multi step and branched RAG workflows using graph based execution.
langchain google genai: Enables integration of Google’s Generative AI models within LangChain.
faiss cpu: High performance similarity search library for vector embeddings.
sentence transformers: Generates dense vector embeddings for semantic search and retrieval tasks.
Run the command below to install or upgrade all required packages:
Step 2: Import Required Libraries
We start by importing all the building blocks required for documents, embeddings, vector search, LLMs and graph orchestration.
Document : Standard format for storing text
RecursiveCharacterTextSplitter: Breaks text into manageable chunks
HuggingFaceEmbeddings: Converts text into numerical vectors
FAISS: Fast vector similarity search
ChatGoogleGenerativeAI: LLM for reasoning and answer generation
LangGraph: Controls multi step RAG flow using nodes
Step 3: Load Dummy Documents
In this article we use small dummy documents to simulate a real knowledge base.
Each text snippet is wrapped inside a Document object
Document provides a standardized interface i.e text content and optional metadata like source, tags, timestamps, etc.
Using dummy documents enables faster iteration and easier debugging.
Step 4: Split Documents into Chunks
Large text blocks dilute retrieval accuracy so we use chunking that breaks documents into focused, overlapping segments that helps vector search engine to retrieve precise and relevant context instead of broad, noisy passages.
RecursiveCharacterTextSplitter: splits text intelligently while preserving semantic boundaries
chunk_size=100: Limits each chunk to 100 characters for fine grained retrieval
chunk_overlap=20: Maintains continuity between adjacent chunks, preventing context loss
Step 5: Generate Embeddings and Build Vector Store
To enable semantic search, we convert text chunks into numerical vector representations. These vectors allow the system to compare meaning not just keywords making retrieval accurate and context aware.
HuggingFaceEmbeddings: Uses a Sentence Transformers model to encode text into dense vectors.
FAISS Vector Store: Stores embeddings in memory for rapid similarity search
LangGraph works using a shared, immutable state that flows through all nodes in the graph. This state acts as a single source of truth, allowing each node to read from and write to the same structured data. Each field in the state represents a key stage in the RAG lifecycle.
query: The original user question and the entry point of the graph.
branches: Sub queries generated from the original query, enabling parallel retrieval paths.
retrieved_docs: Raw content returned by the retriever across all branches, acts as the evidence pool.
context: Merged and refined knowledge created from retrieved documents and passed to the LLM.
answer: Final grounded response generated by the LLM and the output of the graph
Step 9: Implement Branched RAG Execution Nodes
1. Query Branching Node: Uses the LLM to intelligently decompose the user’s intent into multiple focused sub queries. Each branch captures a different semantic meaning, improving coverage compared to a single broad query.
2. Multi Branch Retrieval Node: Performs vector search independently for each query branch, retrieves the top k relevant chunks and aggregates all results into a unified evidence pool. This parallel retrieval is the core differentiator of Branched RAG.
3. Context Merge Node: Combines and cleans all retrieved content into a single structured context, ensuring the LLM receives clear and relevant information for reasoning.
4. Answer Generation Node: Generates the final response by grounding the LLM in the merged context. This design produces coherent, evidence based answers and significantly reduces hallucinations.
Step 10: Build and Execute the LangGraph Workflow
This step brings all the defined nodes together into a single executable workflow using LangGraph’s graph based model, where nodes specify what operations are performed and edges control when and in what order they run, allowing the user query to flow step by step until the final answer is generated.
__start__: The entry point of the graph where the user query enters the system. An initial empty state is created to begin execution.
branch: The LLM analyzes the query and splits it into multiple sub queries, each targeting a different intent. This creates logical branches for parallel exploration.
retrieve: Each branch performs its own vector search. Relevant document chunks are fetched independently and then collected into a shared result set.
merge: All retrieved content is combined and refined. Redundant information is unified to form a single, clean context.
answer: The LLM uses the merged context along with the original query to generate a grounded final response, significantly reducing hallucinations.
__end__: The final answer is returned and the graph execution completes.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}