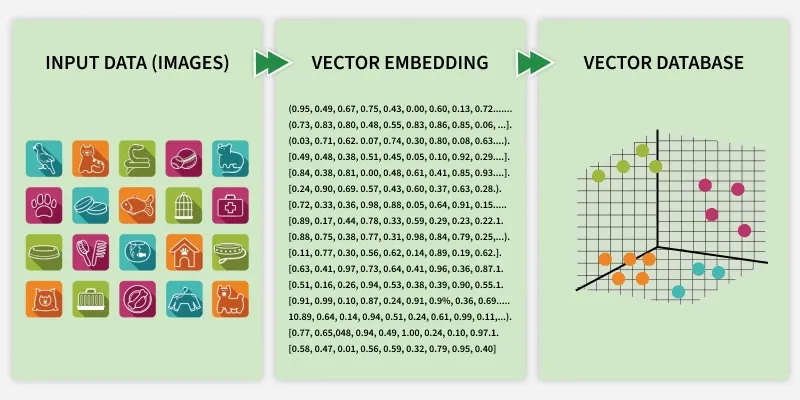
Milvus is an open-source vector database designed for managing and searching large-scale embedding data efficiently. It is widely used in AI, machine learning and semantic search applications where similarity search and retrieval play a key role.
Scalability: Supports a distributed architecture capable of handling billions of vectors.
Multiple Index Types: Integrates advanced similarity search algorithms like IVF, HNSW and ANNOY.
Hybrid Search: Combines vector search with scalar filters (metadata).
Multi-Modality: Works with embeddings from text, audio, video and images.
Multiple Language Support: It provides APIs for Python, Java and REST, making it easy to use in production systems.
Architecture
Milvus’s architecture is modular and distributed. It consists of several components:
Proxy: Manages requests from clients and handles authentication.
Coordinator: Controls query, data and index nodes ensuring consistency.
Data Node: Handles insert and delete operations.
Index Node: Builds and manages vector indexes.
Query Node: Executes search and retrieval operations.
Storage Layer: Uses object storage like MinIO or AWS S3 for persistent data.
Implementation of Milvus
Step 1: Install Dependencies
We will install the required dependencies,
Step 2: Connect to Milvus
We will connect to Milvus Lite:
Uses Milvus Lite which stores data in a local file (milvus.db) in Colab.
No need to specify host or port, the database runs embedded in our notebook.
Output:
Connected to Milvus Lite
Step 3: Create Collection
Defines a collection like a table with an auto-generated primary key (id) and a vector field (embedding). The vector field dimension (dim=128) must match our embedding size.
Output:
Collection created successfully
Step 4: Insert Sample Data
Creates synthetic vector data for demonstration. Each row is a 128-dimensional vector, typical for embeddings (e.g., sentence or image embeddings).
Output:
Inserted 100 vectors
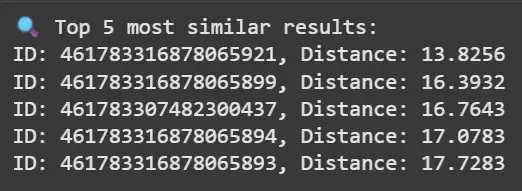
Step 5: Create an Index for Faster Search
Here:
Indexes accelerate vector search by clustering data.

{kind=link}
{kind=link}
{kind=link}