 |
VOOZH | about |
|
VOOZH | about |
Linear Algebra is important in Data Science as it helps represent and process data efficiently, especially for high-dimensional datasets. It also helps in understanding relationships between variables. This is useful in the following ways:
Linear relationships among attributes are identified using the concepts of null space and nullity. These concepts help determine whether variables are linearly dependent and whether some attributes can be expressed as combinations of others.
A generalized system of linear equations is represented as:
A x = b
Where:
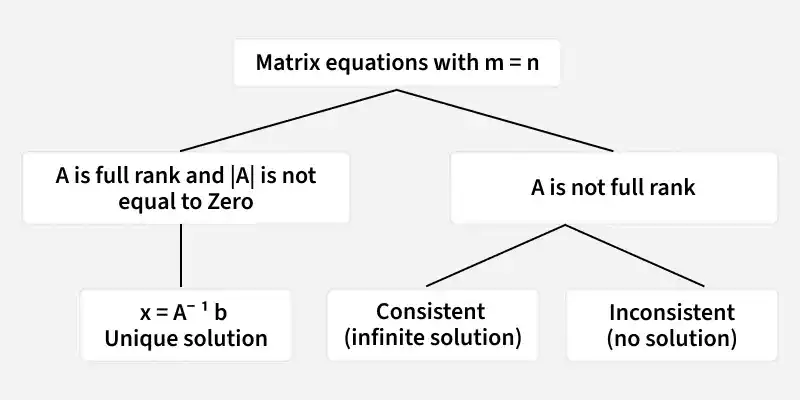
In general there are three cases that need to be understood when analyzing linear systems. These cases depend on the rank of the matrix and describe how rows and columns relate to one another. Each case is considered independently.
The solution for this type of linear equation if A is a full rank matrix having determinant of A is equal to 0 will be:
1. Unique Solution
Consider the given matrix equation
Therefore, the solution for the given example is (x1 , x2) = (1, 2)
2. Infinite Solutions
Consider the given matrix equation
Checking consistency
Row 2 is twice Row 1 so the system has only one linearly independent equation. Since there are two variables but only one independent equation, the system is consistent and has infinitely many solutions.
3. No Solution
Consider the given matrix equation:
Checking consistency
Compare Row 2 with 2 × Row 1:
We cannot find the solution to (x1, x2)
An optimization perspective
Instead of finding an exact solution to the system A x = b, we can find an x that minimizes the difference Ax-b.
Let the error vector be:
We can minimize all the errors collectively by minimizing
So, the optimization problem becomes
Here, we can notice that the optimization problem is a function of x. When we solve this optimization problem, it will give us the solution for x. We can obtain the solution to this optimization problem by differentiating with respect to x and setting the differential to zero.
Now, differentiating f(x) and setting the differential to zero results in
Assuming that all the columns are linearly independent
Note: While this solution x might not satisfy all the equations but it will ensure that the errors in the equations are collectively minimized.
Example
Consider the given matrix equation:
Here m=3, n=2
Using the optimization concept
Therefore, the solution for the given linear equation is
Substituting in the equation shows
So the important point to notice in case 2 is that if we have more equations than variables then we can always use the least square solution which is .
There is one thing to keep in mind is that exists if the columns of A are linearly independent.
Given below is the optimization problem such that, Ax=b
We can define a Lagrangian function
Differentiate the Lagrangian with respect to x and set it to zero, then we will get,
Pre - multiplying by A
assuming that all the rows are linearly independent
Example
Consider the given matrix equation:
Here m=2 and n=3
Using the optimization concept
The solution for the given sample is () = (-0.2, -0.4, 1)
You can easily verify that
The row rank of a matrix is always equal to its column rank, regardless of the matrix size
Consider a matrix A of size m x n
{kind=link}
{kind=link}
{kind=link}