Text Embeddings using Cohere allow you to convert text into numerical vectors that capture meaning, context and semantic relationships between words or sentences. These embeddings are essential for various Natural Language Processing (NLP) tasks such as search, classification, clustering and recommendation systems.
Cohere provides high-quality embeddings through its API.
It helps measure text similarity and semantic relevance efficiently.
It’s useful for information retrieval, chatbots and content recommendation.
The embeddings can be easily integrated into Python or other platforms via simple API calls.
Generating Text Embeddings
Let's see how text embedding can be done using Cohere:
Step 1: Install packages
We will install the required packages for our model.
Step 2: API Key
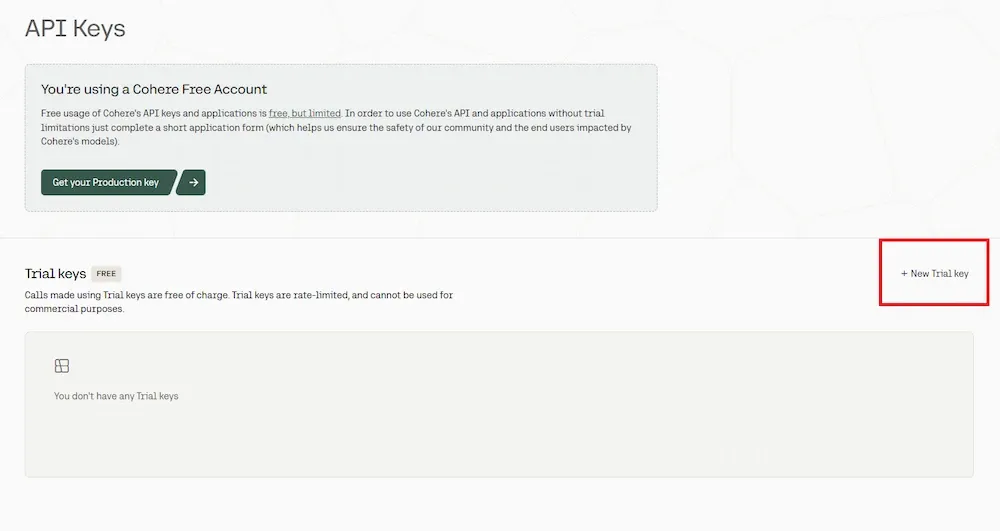
We will be using the Cohere API key, so lets extract it first,
1. Go to the official website.
2. Choose to Signup/ Sign in.
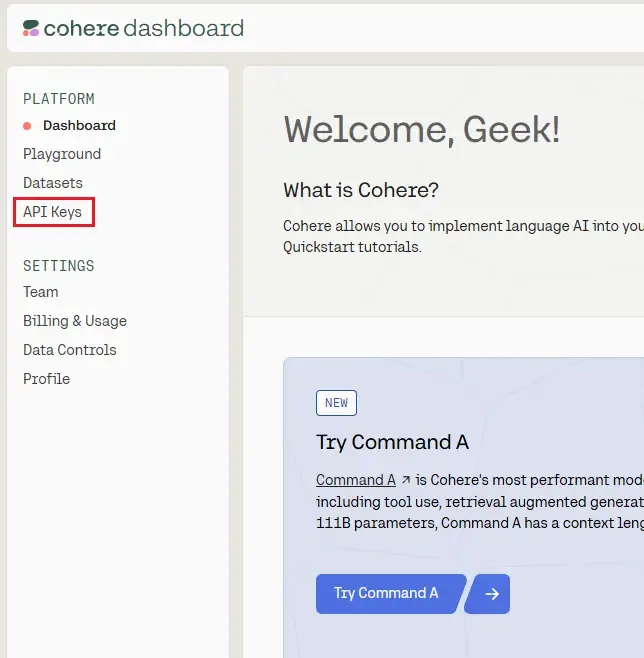
3. On the Cohere Dashboard, find and select API Key section.

{kind=link}
{kind=link}
{kind=link}
{kind=link}