Apache Spark is an open-source distributed computing framework built for large-scale data processing and analytics. It processes massive datasets across clusters of machines with high speed and reliability.
It is designed for large-scale distributed data processing.
Handles massive datasets (terabytes to petabytes).
Uses in-memory computation for high performance.
Provides fault tolerance and horizontal scalability.
Core Architecture
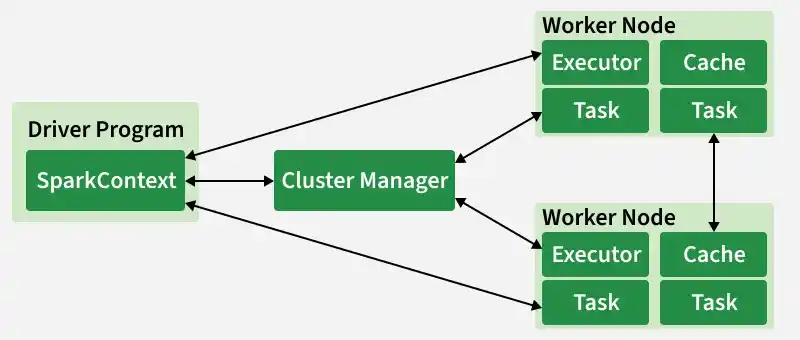
Spark uses a master-worker (driver-executor) model, with modern enhancements like Spark Connect.
Driver Program — The "brain": Runs the main() function, creates SparkSession/SparkContext, translates code into a logical plan, optimizes it (via Catalyst), creates a physical plan, and coordinates execution.
Cluster Manager — Allocates resources (YARN, Kubernetes, Mesos, standalone, or cloud-native like Databricks/EMR).
Executors — Worker processes on cluster nodes. Each runs tasks, stores data in memory/disk, and reports back to the driver.
SparkSession — Unified entry point (replaces older SparkContext + SQLContext).
Spark Connect (major in 4.x) — Decouples client from cluster: Thin client (Python/Scala/Go/R) talks to server-side Spark via gRPC. Enables remote development, better security, and consistency between local and cluster execution.
Key abstractions:
Resilient Distributed Datasets (RDDs) — Low-level, immutable, partitioned collections with lineage for fault recovery (still foundational but less used directly now).
DataFrames / Datasets — Higher-level, structured (with schema), optimized via Catalyst optimizer and Tungsten execution engine (columnar, codegen).
Directed Acyclic Graph (DAG) — Execution plan: Spark builds a DAG of stages (shuffle boundaries separate them).
Spark Streaming / Structured Streaming — Real-time (micro-batch or continuous/real-time mode in 4.x for ms latency).
MLlib — Scalable machine learning.
GraphX — Graph computation
Working of Apche Spark
1. Application Submission & Driver Initialization
A Spark application begins when the user submits code written in PySpark, Scala, Java, or SQL. This code creates a SparkSession, which internally initializes the SparkContext.
The Driver Program is the central coordinator of the application and runs the user’s main function. It is responsible for:
Creating the SparkContext
Converting user code into execution plans
Coordinating execution across the cluster
Collecting or persisting final results
The Driver contains critical internal components:
DAG Scheduler
Task Scheduler
Backend Scheduler
Block Manager
Together, the Driver and SparkContext oversee the entire job execution lifecycle.
2. Logical Plan Creation (Lazy Evaluation)
Spark follows a lazy evaluation model. When transformations such as filter, map, or groupBy are defined, Spark does not execute them immediately.
Instead:
User code is converted into an unresolved logical plan.
Spark records what needs to be done, not how to do it yet.
Execution only begins when an action (e.g., show(), count(), write()) is called.
3. Query Optimization Using Catalyst Optimizer
Once an action is triggered, Spark hands the logical plan to the Catalyst Optimizer, which performs multiple optimization steps:
Analysis – Resolves column names, data types, and references.

{kind=link}
{kind=link}