L-graphs can generate context-sensitive languages, but programming such languages is more difficult than programming regular languages. Therefore, a hypothesis is proposed to identify the type of L-graphs that generate regular languages.A nest is a neutral path T₁ T₂ T₃ where T₁ and T₃ are cycles and T₂ is a neutral path connecting them. This path is called an iterating nest if all three paths print repetitions of the same string α.
Points defining an iterating nest:
- T₁ prints αᵏ
- T₂ prints αˡ
- T₃ prints αᵐ
- k, l, m ≥ 0
- α is a string of input symbols
- At least one of k, l, or m should be ≥ 1
Hypothesis: If all nests in a context-free L-graph G are iterating nests, then the language L(G) generated by G is a regular language. Based on this hypothesis, such L-graphs can be converted into an equivalent NFA.
- Step-1: Languages of the L-graph and NFA must be the same, thusly, we won’t need a new alphabet . (Comment: we build context free L-graph G’’, which is equal to the start graph G’, with no conflicting nests)
- Step-2: Build Core(1, 1) for the graph G. V’’ := {(v, ) | v V of canon k Core(1, 1), v k} := { arcs | start and final states V’’} For all k Core(1, 1): Step 1’. v := 1st state of canon k. . V’’ Step 2’. arc from state followed this arc into new state defined with following rules: , if the input bracket on this arc ; , if the input bracket is an opening one; , if the input bracket is a closing bracket v := 2nd state of canon k V’’ Step 3’. Repeat Step 2’, while there are still arcs in the canon.
- Step-3: Build Core(1, 2). If the canon has 2 equal arcs in a row: the start state and the final state match; we add the arc from given state into itself, using this arc, to . Add the remaining in arcs v – u to in the form of
- Step-4:(Comment: following is an algorithm of converting context free L-graph G’’ into NFA G’)
- Step-5: Do the following to every iterating complement in G’’: Add a new state v. Create a path that starts in state , equal to . From v into create the path, equal to . Delete cycles and .
- Step-6: G’ = G’’, where arcs are not loaded with brackets.
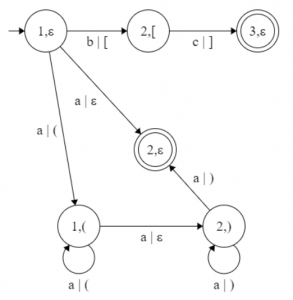
So that every step above is clear I’m showing you the next example. Context free L-graph with iterating complements , which determines the 👁 Image
Start graph G Core(1, 1) = { 1 – a – 2 ; 1 – a, (1 – 1 – a – 2 – a, )1 – 2 ; 1 – b, (2 – 2 – c, )2 – 3 } Core(1, 2) = Core(1, 1) { 1 – a, (1 – 1 – a, (1 – 1 – a – 2 – a, )1 – 2 – a, )1 – 2 } Step 2: Step 1’ – Step 3’ 👁 Image
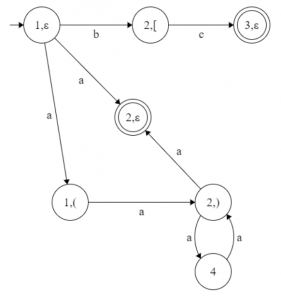
Intermediate graph G’’ 👁 Image
NFA G’
Advantages of hypotheses
- Framework for analysis: Hypotheses about language regularity provide a structured way to analyze and classify languages into classes such as regular and context-free.
- Understanding language behavior: They help researchers understand how languages behave. For example, regular languages have clear properties and can be recognized using finite automata.
- Bridging theory and practice: These hypotheses connect theoretical concepts with practical applications like compiler design, pattern matching, and text processing.
Disadvantages of hypotheses
- Limitations of classification: Not all languages fit clearly into predefined classes like regular or context-free, which makes classification difficult.
- Complex languages: Many real-world applications involve complex languages such as context-free or context-sensitive languages where the regularity assumption may not work.
- Oversimplification: Assuming a language is regular can oversimplify the problem and may ignore important structural properties of the language.

{kind=link}
{kind=link}
{kind=link}
{kind=link}