 |
VOOZH | about |
|
VOOZH | about |
TrueFoundry recognized in Gartner Hype Cycle for Platform Engineering 2026. Read the full report →
Join our VAR & VAD ecosystem — deliver enterprise AI governance across LLMs, MCPs & Agents. Become a Partner →
Get instant access to a live TrueFoundry environment. Deploy models, route LLM traffic, and explore the full platform — your sandbox is ready in seconds, no credit card required.
Blazingly fast way to build, track and deploy your models!
As teams move LLM applications and AI agents into production, cost quickly becomes one of the hardest problems to reason about. Unlike traditional cloud workloads, AI costs are driven by usage patterns that are dynamic, non-deterministic, and often hidden behind multiple layers of abstraction.
A single user request can trigger multiple model calls, retries, tool invocations, and agent loops. Small changes in prompts, routing logic, or agent behavior can significantly increase token usage and cost, often without obvious signals until billing reports arrive.
This is why AI cost observability is critical in production systems. It goes beyond tracking token counts or provider invoices. AI cost observability focuses on attributing cost to the real units of AI systems, such as requests, prompts, agents, tools, and users, while enabling teams to detect and control cost issues early.
In this blog, we’ll explain what AI cost observability means in practice, why AI costs are difficult to track, and how teams use gateway-based architectures to monitor and control LLM spend in production.
AI cost observability is the ability to measure, attribute, and analyze the cost of AI workloads across models, agents, and workflows in real time.
In production systems, this typically includes:
In practice, this extends beyond simple billing dashboards into structured LLM cost tracking solution, where token usage, retries, routing decisions, and agent behavior are tied directly to real application workflows.
Unlike traditional infrastructure cost monitoring, AI cost observability must operate at the application and inference layer. Cloud billing tools can tell teams how much they spent overall, but they do not explain why costs increased or which part of the system caused it.
Effective AI cost observability gives teams the context needed to answer questions like:
By making cost visible at this level, teams can treat AI spend as an operational metric rather than a surprise expense.
AI costs are difficult to track not because pricing is opaque, but because cost is an emergent property of system behavior. In production environments, LLM usage is shaped by routing logic, retries, agents, and tool calls, all of which interact in non-obvious ways.
Several factors make AI cost observability challenging for teams.
Most LLM providers charge based on tokens, but token usage is highly sensitive to runtime behavior. Small changes in prompts, context size, or output constraints can increase token counts significantly. Because these changes often happen at the application or prompt layer, they are difficult to detect using provider-level billing alone.
Production systems rarely rely on a single model. Teams route requests across multiple models and providers to balance cost, latency, and quality. Without a centralized view, cost data becomes fragmented across providers, making it hard to compare or optimize spend holistically.
Failures are expensive in AI systems. Retries and fallback logic can silently multiply costs, especially when requests cascade across models. Without observability at the request level, teams often miss these hidden cost multipliers until they appear in aggregate bills.
Agent-based systems amplify cost complexity. A single agent run may involve multiple model calls, planning steps, and tool invocations. If an agent enters a loop or overuses tools, costs can escalate rapidly. Tracking this behavior requires visibility into how agents execute step by step.
Cloud cost tools and provider dashboards report usage at an account or project level. They do not attribute cost to prompts, agents, users, or workflows. This makes it difficult for platform teams to enforce budgets or for application teams to optimize their own usage.
In practice, these challenges mean that AI cost issues are often detected late and addressed reactively. This is why teams running production AI workloads need cost observability built into the AI Gateway and execution path, where all requests pass through.
To control AI spend in production, teams need more than a total monthly bill. They need to understand where cost is coming from and why. Cost observability builds on LLM observability by tying token usage and spend to prompts, agents, and workflows. Effective AI cost observability breaks spend down across dimensions that map to how AI systems are actually built and operated.
The most useful cost dimensions include the following.
This is the foundation. Tracking cost per request helps teams understand how expensive individual user interactions are and how that cost changes over time. Spikes here often indicate prompt growth, retries, or routing changes.
In multi-model systems, different models have very different cost profiles. Teams need visibility into how much spend is going to each model and provider, and how routing decisions affect overall cost. This is essential for making informed tradeoffs between quality, latency, and spend.
Prompts directly influence token usage. Tracking cost by prompt and prompt version allows teams to see which prompts are expensive and whether recent changes increased or reduced spend. This becomes especially important when prompts are shared across multiple applications or agents.
In agent-based systems, cost attribution must go beyond individual model calls. Teams need to understand how much a full agent run or workflow costs end to end, including planning steps, tool calls, and retries. This helps surface inefficient agent behavior early.
For internal platforms and enterprise deployments, attributing cost to users or teams enables accountability and budgeting. This dimension is often required to enforce usage limits or to showback costs internally.
Observing these dimensions together allows teams to move from reactive cost analysis to proactive cost control.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
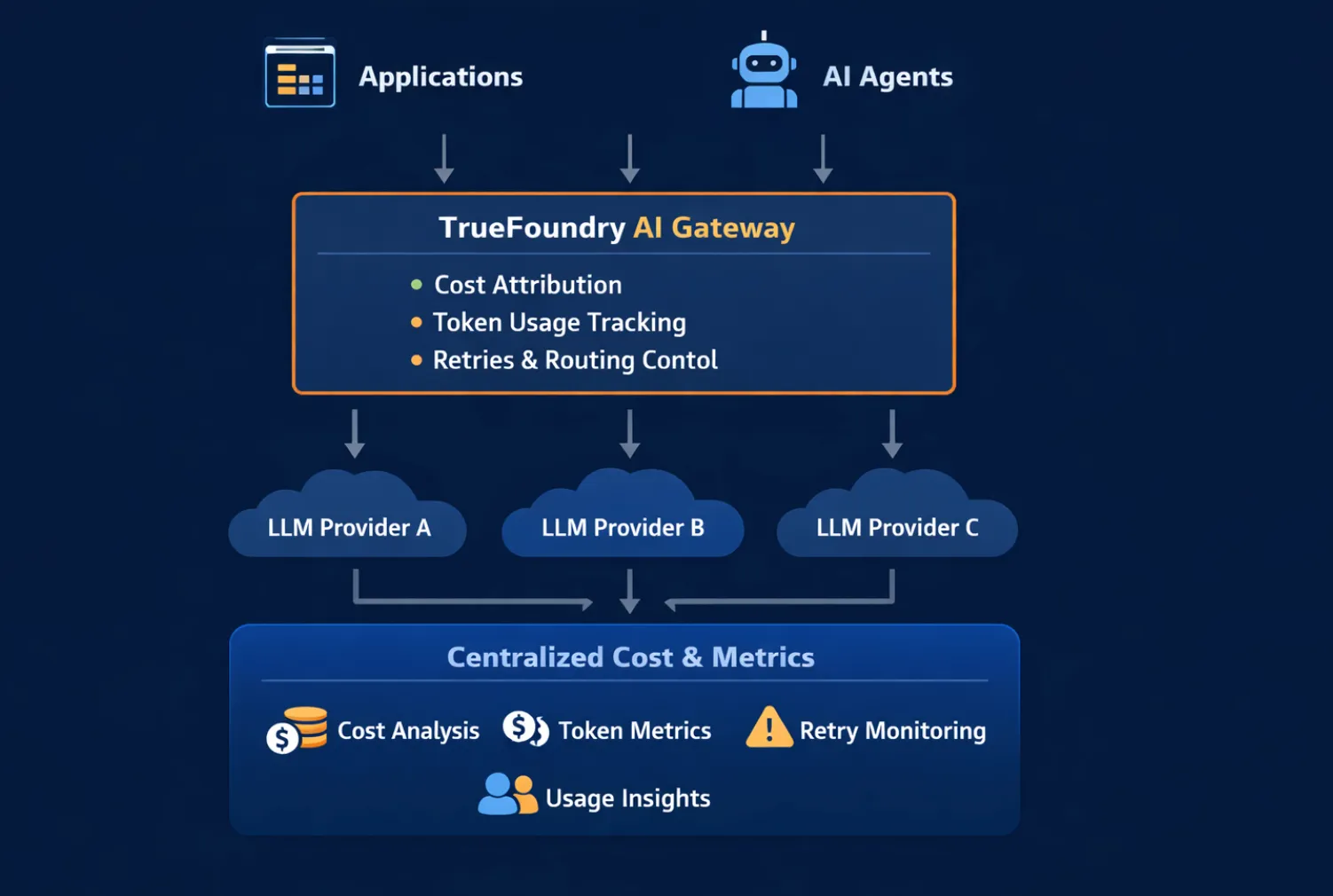
AI cost observability works best when implemented at a central interception point, where all requests, routing decisions, and retries are visible. This is why AI Gateways play a critical role.
An AI Gateway sits between applications or agents and model providers. Because every request flows through it, the gateway can:
Without a gateway, cost data is fragmented across SDKs, services, and provider dashboards. With a gateway, cost becomes a first-class signal that can be analyzed and acted upon before spend escalates.
In TrueFoundry, the AI Gateway provides this centralized control point, making it possible to observe and manage AI costs across models, agents, and workflows in a unified way.
Agent-based systems amplify both the power and the cost of AI workloads. Unlike single-request applications, agents execute multi-step workflows that can involve planning, reasoning, retries, and tool usage. This makes cost behavior harder to predict and more important to monitor closely.
A single agent run may include:
Without proper observability, these interactions can silently multiply costs. Agent loops, poorly constrained prompts, or excessive tool usage often go unnoticed until aggregate spend increases significantly.
AI cost observability for agents requires visibility at the agent execution level, not just at the model call level. Teams need to understand:
This is where a gateway-based architecture becomes especially valuable. By capturing agent requests at the gateway, teams can attribute cost across the full lifecycle of an agent run, rather than treating each model call in isolation.
In TrueFoundry, agent deployments integrate with the AI Gateway, enabling teams to observe cost across agent steps and workflows. This allows platform and application teams to detect inefficient agent behavior early and apply constraints before costs spiral.
In TrueFoundry, AI cost observability is implemented directly at the AI Gateway and agent execution layer, where all model requests, routing decisions, and retries are visible. This provides a unified and consistent view of cost across models, prompts, agents, and workflows.
Because every request flows through the gateway, TrueFoundry can:
This centralized approach turns cost from a passive metric into an operational signal. Teams can set alerts on abnormal spend, enforce budgets at the routing layer, and make cost-aware decisions when choosing models or fallback strategies.
For teams running production AI workloads, this ensures that cost remains predictable, explainable, and controllable, even as systems grow in complexity with more agents, models, and workflows.
AI cost becomes difficult to manage as soon as LLM applications move into production. Costs are no longer driven by a single model call, but by a combination of prompts, routing decisions, retries, agents, and tool usage. Without proper visibility, teams often discover cost issues only after spend has already increased.
AI cost observability addresses this by making cost a first-class signal. By attributing spend across requests, models, prompts, agents, and workflows, teams can understand not just how much they are spending, but why. This level of insight is essential for operating AI systems reliably at scale.
Gateway-based architectures play a central role in enabling this visibility. By capturing requests at a single control point, teams can observe, analyze, and control AI spend consistently across providers and execution paths. In TrueFoundry, this approach allows platform and application teams to detect inefficiencies early, enforce budgets, and balance cost with performance as AI workloads grow.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.
Product
Company
Resources
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
.svg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
.webp){kind=link}
.webp){kind=link}
.webp){kind=link}
.webp){kind=link}
.webp){kind=link}
.webp){kind=link}
{kind=link}
.webp){kind=link}
{kind=link}
.webp){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}