 |
VOOZH | about |
|
VOOZH | about |
TrueFoundry recognized in Gartner Hype Cycle for Platform Engineering 2026. Read the full report →
Join our VAR & VAD ecosystem — deliver enterprise AI governance across LLMs, MCPs & Agents. Become a Partner →
Get instant access to a live TrueFoundry environment. Deploy models, route LLM traffic, and explore the full platform — your sandbox is ready in seconds, no credit card required.
Blazingly fast way to build, track and deploy your models!
No single model wins every task. GPT-4o handles complex reasoning well, while smaller language models often handle classification, routing, and extraction at lower cost. Routing every request to the most expensive model creates unnecessary spend and weakens resource allocation across production AI teams.
Multi-Model orchestration operationalizes this distinction. Instead of pinning every workload to a single provider, it routes requests across different models based on task type, cost, latency, and quality requirements. For production teams, this is no longer a narrow optimization. It is becoming the operating layer for enterprise AI.
Enterprises now run AI applications across OpenAI, Anthropic, Google, Azure, AWS Bedrock, and self-hosted models. Multi-LLM orchestration has moved from a helpful routing pattern to a core infrastructure requirement. This guide explains how it works, what it does not solve on its own, and how TrueFoundry adds governance via an enterprise gateway layer.
Multi-Model orchestration is the practice of connecting an application, single AI agent, or workflow to multiple AI models. The orchestration layer then routes each request to the model that best fits the specific task, cost target, latency requirement, or quality threshold.
The term covers both static and dynamic routing. Static routing assigns different tasks to predefined models. Summaries can go to a cost-efficient model, code completions can go to a coding model, and deep research can go to a stronger reasoning model.
Dynamic routing evaluates user input at runtime. The orchestration engine can inspect complexity, provider health, latency, cost, and available routing policies before dispatch. Most real-world systems use both approaches to balance speed, quality, resilience, and cost.
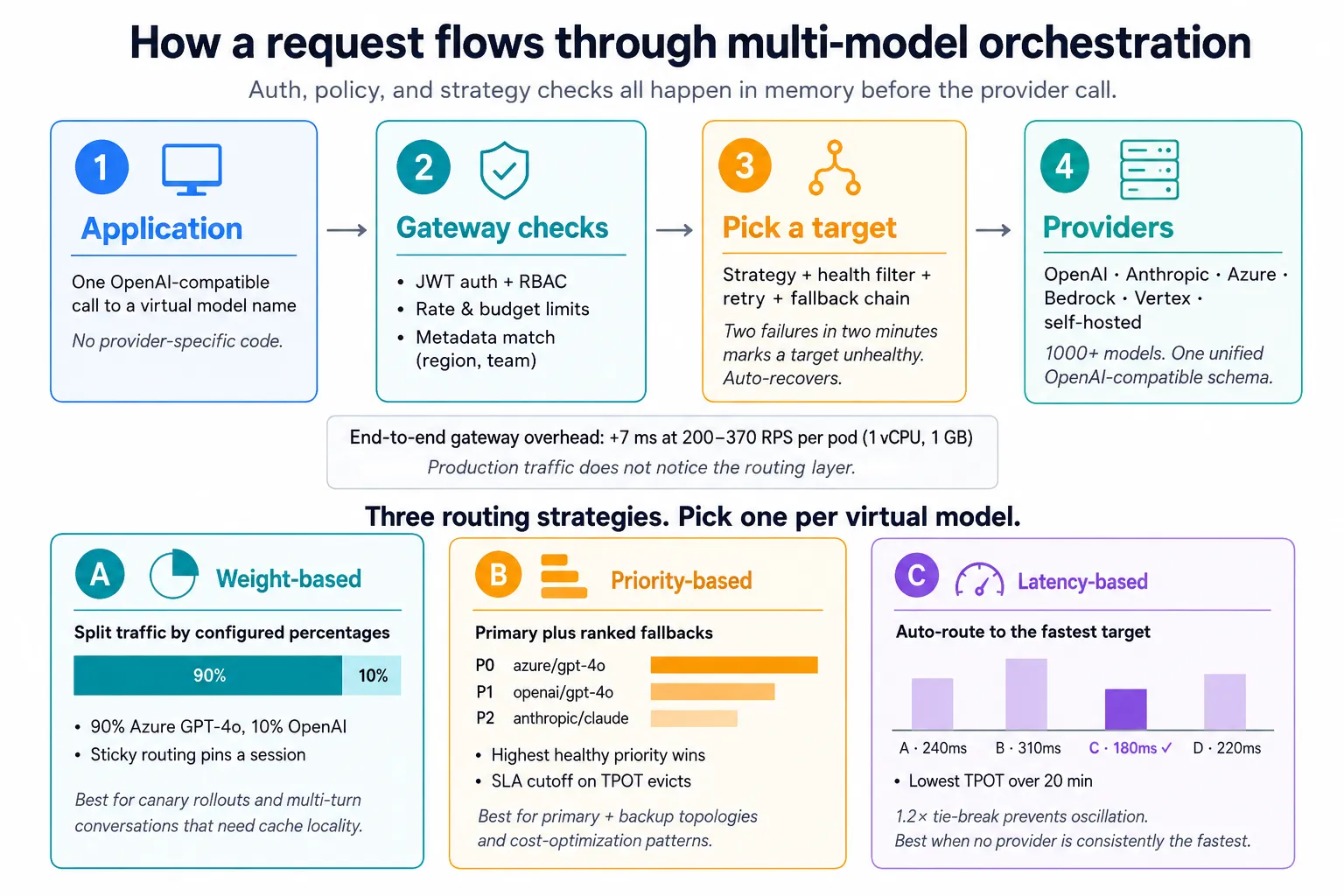
In both cases, the central orchestrator sits between the application and the underlying models. It abstracts provider-specific APIs, handles routing, normalizes responses, and manages failover. Your application has a single entry point, while the gateway manages model selection and provider behavior.
Multi-Model orchestration has become essential because AI workloads now differ sharply by cost, risk, complexity, and latency. A chatbot answering simple customer inquiries does not need the same model as an agent handling regulated decisions or complex code generation.
Frontier models optimize for reasoning quality and breadth. Smaller language models optimize for speed and cost on well-defined tasks. Pinning every workload to one tier leaves real value unrealized on both ends.
Routing all traffic to flagship large language models by default means overpaying on a large share of requests. A smaller model can answer many routine prompts with the same accuracy and faster response times. The inverse creates a different problem, because standardizing on a cheaper model can cause genuinely hard prompts to return shallow or incorrect responses.
If you have ever watched a spend graph climb with no clear driver, the cause is often simple. One default model, one routing rule, and no way to send easier work somewhere cheaper. Multi-Model orchestration is the structural fix because it matches each specific task to the right model.
LLM API providers experience outages, rate limits, and performance degradation that affect production applications directly. TrueFoundry’s own gateway documentation cites the OpenAI and Anthropic status pages from February through May 2025, showing repeated incidents over a four-month stretch.
That is not an edge case. It is the operating environment for production generative AI systems.
Multi-Model orchestration with automatic failover routes production workloads to an available provider when the primary endpoint is degraded. The application stays available without requiring human intervention or urgent changes from the on-call engineer. The pattern is the same as any critical dependency: redundancy, health checks, and automatic fallback.
Regulated enterprises cannot send every request to every model. Some workloads involve sensitive data, sensitive information, customer records, or regional data restrictions. In these cases, routing decisions must consider policy rules, not only cost or latency.
A governed control layer can route requests based on metadata, geography, team, environment, or data class. This matters when external data, private datasets, or restricted workflows need to remain inside approved boundaries.
In TrueFoundry’s case, you can attach metadata_match rules to a target so it only receives traffic when request metadata (or the gateway’s own tfy_gateway_region tag) matches a configured value, with a catch-all target for any region that isn’t explicitly mapped.
Multi-Model orchestration typically relies on four core components: a unified API layer, routing logic, failover chains, and response normalization. Together, they help teams use multiple providers without hardcoding every integration inside application code.
Every provider uses different request formats, parameter names, error codes, and response structures. The AI orchestration framework normalizes these differences behind one API. This gives applications a consistent interface across hosted, open-source, and self-hosted models.
TrueFoundry’s LLM Gateway exposes an OpenAI-compatible schema across more than 1,000 models. This lets teams add or swap providers without changing every downstream service. It also simplifies prompt engineering, testing, and rollout management across teams.
This unified API layer also improves ease of use for developers and platform teams. It simplifies prompt engineering, integration testing, and rollout management across various applications. Instead of building separate provider-specific logic across services, teams use one consistent entry point for model access.
This is where multi-model orchestration earns its name. TrueFoundry’s virtual models support three routing strategies, and you pick one per virtual model:
In TrueFoundry, the config for a typical primary-plus-fallback virtual model looks like this:
routing_config:
type: priority-based-routing
load_balance_targets:
- target: azure/gpt-4o
priority: 0retry_config:
attempts: 3delay: 200on_status_codes: ["429", "500", "503"]
fallback_status_codes: ["429", "500", "502", "503"]
- target: openai/gpt-4o
priority: 1retry_config:
attempts: 2delay: 100 - target: anthropic/claude-sonnet
priority: 2fallback_candidate: falseIn that configuration, requests go to azure/gpt-4o first. Per its retry_config block, the gateway retries up to 3 times with a 200 ms delay on rate-limit errors before falling over to openai/gpt-4o. The Anthropic target only runs when it’s the highest-priority healthy target, never as a fallback for the other two.
All of this is in memory.
No external calls in the request path.
These routing patterns support various applications, including customer service, customer support, conflict resolution, coding assistants, compliance workflows, and internal enterprise copilots.
Failover chains define a priority-ordered list of providers for each routing rule. When the primary returns a fallback status code (TrueFoundry’s defaults: 401, 403, 404, 429, 500, 502, 503), the gateway tries the next eligible target instead of bubbling the error up to the application.
This pattern is especially useful for complex workflows and autonomous agents. When an agent relies on multiple model calls, a single provider failure can break the workflow. Automatic failover protects the experience without needing human intervention.
There’s also retry logic on the same target before any fallback kicks in. The gateway’s defaults are 2 retries with a 100 ms delay on 429, 500, 502, 503. Each target can override those defaults inside its own retry_config block. In the YAML above, azure/gpt-4o overrides those defaults to 3 retries at 200 ms, while openai/gpt-4o explicitly sets them to 2 retries at 100 ms (matching the defaults). anthropic/claude-sonnet has no retry_config block, so it inherits the defaults. And the gateway tracks failures continuously. If a target trips 2 or more failures inside a 2-minute rolling window, it’s marked unhealthy and skipped until errors age out, with automatic recovery. No human intervention, and no manual config edits when an outage clears.
Different models return responses in different shapes, with different metadata, finish reasons, and token-count formats. The orchestration layer normalizes all of that. Your code reads the same response structure whether the request went to OpenAI, Anthropic, or a self-hosted Llama.
For debugging, TrueFoundry returns the actual target that served the request in the x-tfy-resolved-model response header, so you can trace which model produced any given output even when the virtual model name covers ten possible targets. That visibility matters when you’re investigating a quality regression and need to know whether your sticky-routing config kept the user on the same provider or fell over halfway through a session.
Multi-Model orchestration creates value when teams connect routing decisions with business outcomes. The goal is not to use more models. The goal is to apply the right model to each request while improving cost, quality, availability, compliance, and governance.
| Business Need | How Multi-Model Orchestration Helps |
|---|---|
| Lower cost | Routes simple tasks to smaller models |
| Better reliability | Fails over when providers degrade |
| Faster response | Routes latency-sensitive work to faster models |
| Stronger quality | Uses stronger models for complex tasks |
| Better compliance | Routes sensitive workloads to approved targets |
| Faster experimentation | Tests models without application rewrites |
For example, a support workflow can route routine customer inquiries to a smaller model. It can send complex billing disputes or technical support cases to a stronger model. This improves cost control without weakening answer quality.
In another use case, an enterprise research assistant can use one model for natural language understanding, another for data retrieval, and another for natural language generation. The orchestration logic decides which model or agent contributes to the final answer.
This architecture gives enterprises a competitive advantage because model choice becomes operational. Teams can adjust routing rules, test providers, reduce costs, and improve response quality without rebuilding every AI application.
Routing alone isn’t governance.
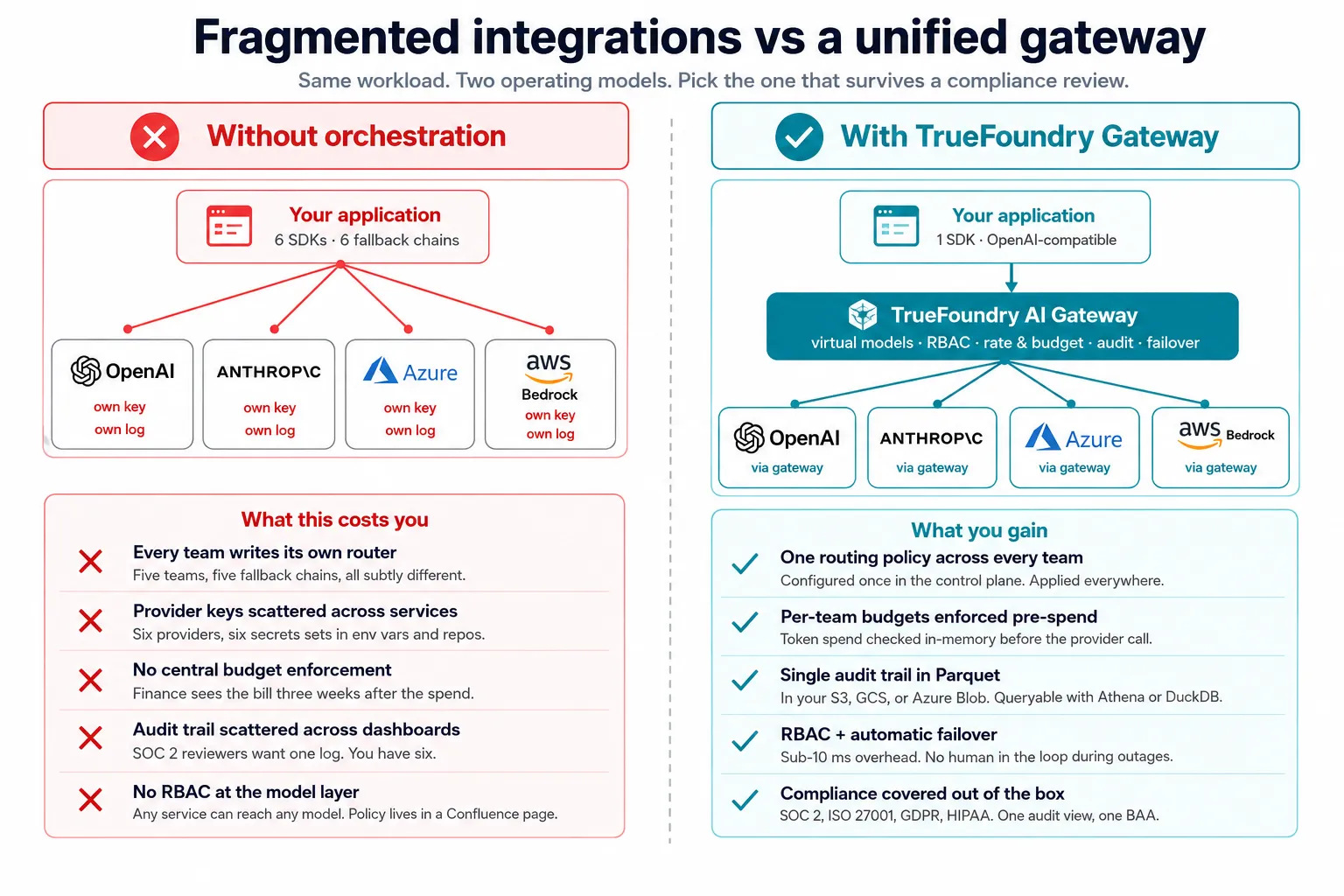
Plenty of teams build their own router, get the load-balancing math right, and still wake up to four problems they didn’t plan for.
Per-application routing means every team writes its own version of the same logic. Five teams, five subtly different fallback chains, five sets of provider keys floating around in environment variables. That inconsistency compounds at organizational scale and turns “we have multi-model orchestration” into “each team has multi-model orchestration.”
No routing framework enforces per-team budget limits before requests execute. Token spend accumulates across every routed provider. By the time finance asks why the OpenAI bill tripled, the budget conversation has already happened, three weeks late.
Multi-provider routing creates a multi-provider audit problem. Logs in OpenAI’s dashboard, logs in Anthropic’s console, logs in Azure’s portal. None of them stitch together into the unified, user-attributed audit trail that SOC 2 and HIPAA reviews actually want to see.
Availability is not the same as access control. Failover means any healthy provider can serve a request. Without RBAC at the gateway, any healthy provider may also become reachable to engineers or AI agents that should not access it. If a marketing prompt must never reach a model approved only for clinical workflows, the policy needs to live at the gateway, not in a Confluence page.
This is where context engineering and state management also become operational concerns. A system may retrieve relevant information from data sources, knowledge base systems, vector databases, and external data sources. Without a governed control layer, the entire system can expose information or route requests incorrectly.
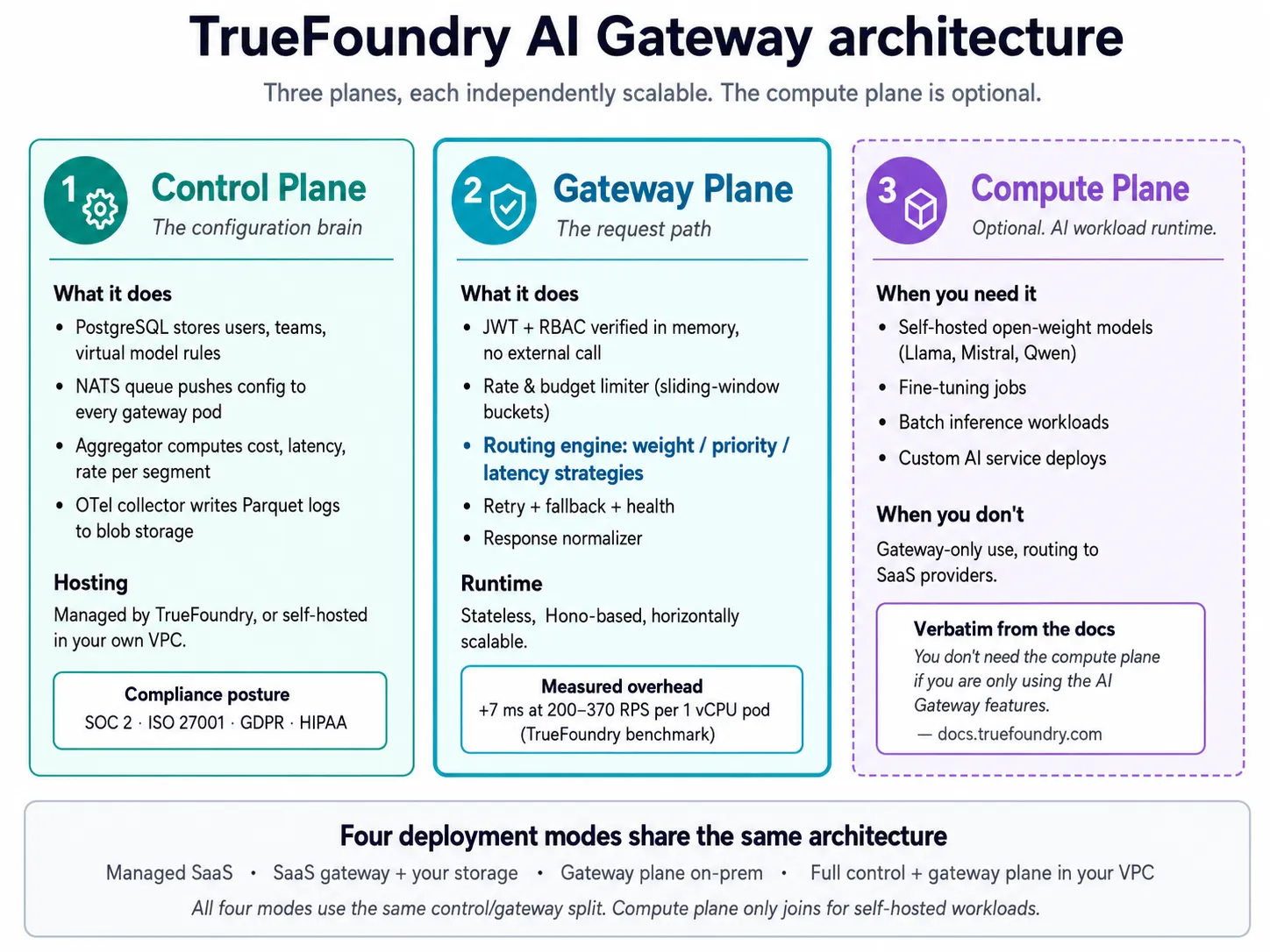
TrueFoundry’s LLM Gateway provides multi-model orchestration as a control-plane-managed routing layer that can run as managed SaaS, hybrid, or fully inside your own VPC. Four properties matter for production deployments.
The AI Gateway adds broader governance, rate limiting, budgets, guardrails, and observability across production AI workloads. The MCP Gateway governs tool access, authentication, and MCP server visibility for model-powered applications. The Agent Gateway controls autonomous agents, specialist agents, and complex workflows in which a single AI agent can make multiple model or tool calls.
Book a demo to see how TrueFoundry governs multi-model routing, agents, MCP tools, and audit trails inside your VPC.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.
Multi-model orchestration is the architectural pattern of connecting an application to multiple AI models and dynamically routing each request to the model best suited for it, based on factors like task type, latency, cost, or provider availability. The orchestration layer abstracts the underlying providers behind a single API, handles failover when a model is unavailable, and normalizes responses so applications don’t need provider-specific code. In production, it’s how teams keep AI features running through provider outages and keep costs predictable as usage grows.
Multi LLM orchestration is the same pattern applied specifically to large language models. An orchestration layer sits between applications and several LLM providers (OpenAI, Anthropic, Google, Bedrock, self-hosted), routes each request to the appropriate model, manages failover and retries, and gives the application a consistent interface no matter which provider serves the response. The term is often used interchangeably with multi-model orchestration when the underlying models are all LLMs rather than a mix of model types.
The purpose is to match every workload to the right model on three axes: capability, cost, and reliability. Frontier models cost more but handle hard tasks better. Smaller models are cheap and fast for routine work. Multi-model orchestration routes intelligently between them, fails over when providers degrade, and gives operations teams one place to enforce cost, rate, and access policies. It’s the difference between running AI as a collection of provider integrations and running AI as a governed platform.
The orchestration layer normalizes them. Each provider has its own response shape, token count format, error codes, and finish reason conventions. The gateway translates everything into a single, consistent format (typically the OpenAI-compatible schema) before returning to the application. Provider-specific handling stays inside the gateway, not in the application code. In TrueFoundry’s case, the resolved target model is also returned in the x-tfy-resolved-model response header so you can trace which provider served any given request.
In a system like TrueFoundry’s gateway, you define a virtual model that points to a list of real targets and choose a routing strategy: weight-based (split traffic by percentages), priority-based (primary plus ranked fallbacks), or latency-based (pick the fastest healthy target automatically). You can layer in retry policies, fallback status codes, SLA cutoffs on time-per-output-token, sticky routing for multi-turn sessions, and metadata-based filters per target. Rules live in the gateway config and apply to every team that uses the virtual model name, with updates propagating in seconds.
Product
Company
Resources
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
.webp){kind=link}
.webp){kind=link}
.webp){kind=link}
.webp){kind=link}
.webp){kind=link}
.webp){kind=link}
{kind=link}
.webp){kind=link}
{kind=link}
.webp){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}