 |
VOOZH | about |
|
VOOZH | about |
TrueFoundry recognized in Gartner Hype Cycle for Platform Engineering 2026. Read the full report →
Join our VAR & VAD ecosystem — deliver enterprise AI governance across LLMs, MCPs & Agents. Become a Partner →
Get instant access to a live TrueFoundry environment. Deploy models, route LLM traffic, and explore the full platform — your sandbox is ready in seconds, no credit card required.
Blazingly fast way to build, track and deploy your models!
Single-agent systems call models and tools. Multi-agent systems add something new: agents calling agents. That east-west traffic — an orchestrator delegating to sub-agents, agents handing work to each other over the still-young Agent2Agent protocol — is where cost runs away, blast radius widens, and "which agent did what" becomes unanswerable. The protocols standardize how agents discover one another and exchange work, and they provide security hooks — but they don’t prescribe your enterprise identity model, policy graph, budget model, or observability and control plane. This post is that governance layer, and why it belongs at the gateway.
Key Takeaways
Tomás, a platform engineer, walked in to a cost alert and a mystery. Overnight, the company's new multi-agent research workflow had spent more than its entire previous month. An orchestrator agent delegated subtasks to a set of sub-agents; one sub-agent, hitting a transient error, retried by re-invoking the orchestrator, which delegated again — a loop that ran for hours. By morning the agents had called each other tens of thousands of times. Tomás wanted to know which agent started it and where the cycle formed, and found he couldn't: every agent authenticated with the same shared service key, the calls between agents weren't recorded as a graph, and there was no per-agent rate limit that would have tripped. The system had governance for calls to the model provider. It had almost none for calls between its own agents.
This is the gap multi-agent systems open. The moment agents start delegating to one another, you have a new internal network — one with no identity, no policy, and no trace by default. The agent frameworks help you build the workflow; they don't govern it. This post is how to give that internal network the same identity, limits, and observability you'd never run a microservice mesh without.
For most of the gateway story so far, traffic has been north-south: an application calls a model, maybe through a tool. Multi-agent systems add east-west traffic — agents invoking other agents. An orchestrator delegates to specialists; a specialist consults another; results flow back up. The still-young Agent2Agent (A2A) protocol gives this a standard shape, with agents publishing capability descriptions (agent cards) that others discover, and exchanging tasks and messages over a common interface, much as MCP standardized how agents reach tools.
The analogy worth holding onto is the move from a monolith to microservices. The instant your agents talk to each other, you have a distributed system with the failure modes of one: cascading retries, cycles, fan-out amplification, and the loss of a single clear call stack. And like microservices, the answer isn't to wish the calls away but to put them behind a layer that gives every caller an identity, every call a policy, and every flow a trace. That layer, for agents, is the agent gateway.
Tomás's root problem was identity. When every agent authenticates with one shared service key, the system literally cannot tell its agents apart — which means it can't authorize them differently, can't attribute cost to them separately, and can't reconstruct which one acted.
The fix is to give each agent its own identity, issued and verified at the gateway, and to propagate it on every call the agent makes — to a model, to a tool, and to another agent. That identity is what every later control hangs off: authorization decisions, rate limits, cost attribution, and trace attribution all key on "which agent."
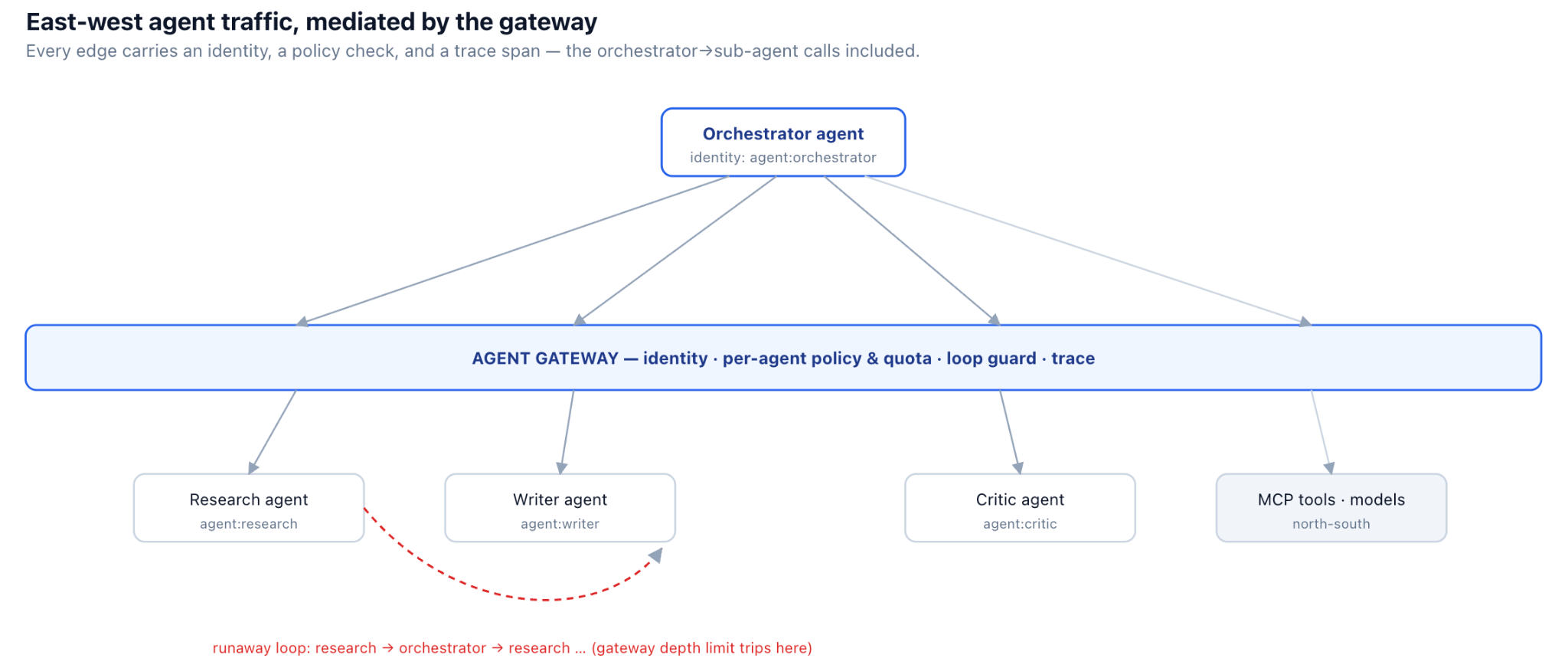
Each agent carries its own identity on every hop (illustrative)
# The gateway issues and verifies a per-agent identity, not a shared key.ctx = AgentContext(
agent_id="agent:research", # this agent's own identity on_behalf_of="user:tomas", # the human principal, preserved end-to-end run_id="run_4f9c", # correlates every hop of one workflow depth=2, # how deep in the delegation chain we are)
# Propagated when this agent delegates to another agent or calls a tool:gateway.invoke(target="agent:writer", context=ctx, payload=task)Centralizing identity at TrueFoundry's Agent Gateway — which manages authentication, identity, and service-account management for agents at the gateway layer — means the identity is established once and trusted everywhere downstream, rather than each agent framework inventing its own scheme. Preserving the human principal (on whose behalf the workflow runs) alongside the agent identity is what keeps end-user authorization and audit intact even three delegations deep.
Identity enables authorization, and the questions are concrete in a multi-agent system. May the research agent invoke the writer agent, or only the orchestrator? May a sub-agent call external tools directly, or only through its parent? Which agents may spend against which budget? Expressing these as policy-as-code — the same Cedar or OPA approach from the governance and routing posts — turns the agent graph's allowed edges into something explicit and reviewable rather than implicit in code.
Per-agent authorization for east-west calls (illustrative policy)
# Default-deny: an agent may only invoke agents it is explicitly allowed to.
allow if principal.agent_id == "agent:orchestrator"
and action == "invoke"
and resource.agent_id in ["agent:research", "agent:writer", "agent:critic"]
# Sub-agents may NOT invoke the orchestrator — this edge is what created the loop.
deny if principal.agent_id in ["agent:research", "agent:writer"]
and resource.agent_id == "agent:orchestrator"
# Only the research agent may reach external search tools.
allow if principal.agent_id == "agent:research"
and resource.kind == "mcp_tool"
and resource.name == "web_search"Notice the second rule: a policy that forbids sub-agents from re-invoking the orchestrator would have cut Tomás's loop at the first hop, independent of any rate limit. Authorization isn't only a security control here; constraining the shape of the agent graph is also how you prevent whole classes of runaway behavior. The gateway becomes the enforcement point when it's the one place every east-west call is routed through.
It helps to be precise about what the protocols decide and what they leave to you. Discovery and transport are standardized; the identity model, policy, budgets, and enforcement point are not:
| Layer | Standardizes | Does not decide |
|---|---|---|
| A2A | Agent discovery via agent cards, task/message exchange, security hooks (declared auth schemes) | Your enterprise identity model, policy graph, budgets, or trace schema |
| MCP | Tool discovery and invocation | Which agent may use which tool, per-tool approvals, tool-call cost and trace policy |
| Agent Gateway | A cross-cutting point to enforce identity, authorization, limits, tracing, and cost | Your business policy — which agents, workflows, and delegations are actually allowed |
Even with good authorization, multi-agent systems fail in ways single calls don't, because the unit of damage is the cascade. A retry that re-delegates can form a cycle; an agent that fans out to many children can amplify one request into thousands; a slow sub-agent can stall a whole workflow. These are the agent-scale version of the thundering-herd and silent-escalation problems familiar from routing and failover at the model layer.
Containment is layered. A delegation-depth limit caps how deep the chain can recurse, breaking cycles structurally. Per-agent rate limits cap how often any one agent can invoke others, so a loop trips a ceiling instead of running all night. Timeouts and stall detection stop an agent waiting forever on a child. And a global per-run budget caps the total spend of one workflow regardless of its shape. TrueFoundry's Agent Gateway documents the relevant primitives — retry policies, fallback paths, timeouts and safeguards against infinite loops or stalled agents, plus token- and cost-based quotas per agent, workflow, or environment. The exact configuration shape below is illustrative; the primitives are what the product page describes.
Blast-radius controls for a multi-agent run (illustrative gateway config)
run_limits:max_delegation_depth:5# breaks cycles structurallymax_total_tokens:500000# whole-run budget, force-stop past thismax_wall_clock_seconds:600per_agent:invoke_rate_limit:60/min# one agent can't call others without boundtimeout_seconds:45# stall detection on a child callon_breach:halt_and_alert# stop the run, page a humanThe shift in mindset is to treat a multi-agent run as a bounded transaction with a budget and a depth, not an open-ended conversation. With those bounds enforced at the gateway, Tomás's overnight loop becomes a tripped limit and an alert at 2am instead of a five-figure invoice at 9am.
Per-request metrics — latency, tokens, errors on each individual call — are necessary but not sufficient for multi-agent systems, because they lose the thing you most need: the shape of the run. When something goes wrong three delegations deep, you need the whole tree — which agent called which, in what order, with what inputs and outputs, and where the cost accrued. That's an end-to-end trace spanning agent steps, model calls, and tool invocations, stitched together by the run identifier that every hop carries.
This builds directly on the tracing from our OpenTelemetry post: the same span model, with the agent as a first-class dimension and the run as the trace that ties spans together. TrueFoundry's Agent Gateway captures these end-to-end execution traces and lets you inspect the per-step logs to diagnose failures — turning "the agents spent too much last night" into "this edge formed a cycle at depth four," which is the difference between a mystery and a fix.
Cost in a multi-agent system is meaningless without identity. "The workflow cost X" doesn't tell you whether the spend is the orchestrator's planning calls, one sub-agent's expensive model choice, or a loop. Attributing tokens and cost to the specific agent, workflow, and run — keyed on the identity from section 2 — is what makes the spend legible and the runaway diagnosable.
This is the cost-attribution post's per-team accounting extended to the agent as the unit. The Agent Gateway attributes token usage and cost to specific agents, workflows, teams, and environments, which does double duty: it answers the finance question (which agent drives spend) and it surfaces the operational anomaly (a single agent's cost spiking is often the first visible sign of a loop, well before the monthly bill). Pair it with the per-run budget from section 4 and cost becomes both observable and bounded.
Multi-agent systems give prompt injection a new way to travel. As covered in our prompt-injection post, an agent that reads untrusted content — a retrieved document, a tool result — can be steered by instructions hidden in it. In a multi-agent system, that compromised agent then talks to other agents, and its output becomes their input. An injection that lands on the research agent can propagate to the writer and critic agents downstream, because to them the research agent is a trusted peer, not an untrusted source.
Treat agent-to-agent messages as untrusted input too
The instinct is to trust internal agents the way you trust internal services. But an agent's output is model-generated and may carry injected instructions it absorbed upstream. The defensive stance is to apply the same input and output guardrails on east-west agent messages as on north-south user input — scan what one agent sends another, not just what enters the system from outside — and to keep the privilege separation that limits what any single compromised agent can reach. A poisoned peer should not be able to escalate through the agents it talks to.
This is why injection defense is an agent-to-agent concern, not just an input-boundary one, and why centralizing it at the gateway matters: when agent-to-agent traffic is routed through the gateway, it sees every east-west message and can apply the guardrails uniformly, rather than trusting each agent to screen its peers.
Every thread here converges on one point: a multi-agent system is a distributed system, and like any distributed system it needs a control plane that gives every caller identity, every call a policy, every flow a trace, and every run a budget. Building that into each agent framework — LangChain here, CrewAI there, a custom orchestrator somewhere else — guarantees inconsistency and gaps, exactly where Tomás's loop slipped through.
The agent gateway is that control plane. TrueFoundry's Agent Gateway runs framework-agnostic agents through a single governed execution layer: per-agent identity and RBAC, token and cost quotas per agent and workflow, retries, timeouts and loop safeguards, end-to-end tracing, and MCP-governed tool access — unifying the model traffic of the AI Gateway, the tool traffic of the MCP Gateway, and the agent-to-agent traffic of multi-agent systems in one place. For a deeper look at the orchestration patterns themselves, TrueFoundry's multi-agent orchestration guide is a useful companion; this post is about governing them once they're running.
Isn't A2A still early? Why govern it now?
A2A is young as an enterprise adoption pattern — even though the protocol now has a formal v1.0 specification — and ecosystem conventions will keep evolving, so treat specifics as provisional. But the governance need doesn't wait for adoption to settle: the moment your agents delegate to each other, by any mechanism, you have east-west traffic with no identity or limits. The controls here — per-agent identity, authorization, blast-radius limits, tracing — apply whether agents talk over A2A, a framework's native delegation, or plain HTTP.
How is this different from the managed agent layer post?
That post argued for separating agent logic from runtime — where agent code runs and how it's deployed. This one is about governing the communication between agents once they're running: identity on each hop, who may invoke whom, containing cascades, and tracing the run. Related layers, different problems — runtime separation is about the agent as a deployable unit; this is about the agent as a network participant.
What single control would have prevented the cold open?
Two, working together. An authorization rule forbidding sub-agents from re-invoking the orchestrator would have cut the loop structurally at the first hop; a delegation-depth limit and per-agent rate limit would have caught any cycle that slipped through the policy. Neither requires understanding the workflow's intent — they bound its shape — which is why they belong at the gateway rather than in each agent's logic.
Do agents really each need their own identity?
For anything you need to authorize, attribute, or audit per agent — yes. A shared key collapses every agent into one principal, which is why Tomás couldn't tell which agent started the loop or what each one cost. Per-agent identity, with the human principal preserved alongside it, is the foundation every other control in this post depends on.
Gateway or framework for multi-agent governance?
The framework builds the workflow; the gateway governs it. Identity, authorization, rate and depth limits, tracing, and cost attribution are cross-cutting concerns that need to be consistent across every agent and framework you run, which is precisely what a single control plane provides and what per-framework implementation can't guarantee.
Tomás's incident wasn't a clever failure; it was an ungoverned internal network doing what ungoverned networks do. Multi-agent systems are powerful because agents can delegate freely — and that same freedom is why they need identity, limits, and a trace on every edge. Put that control plane in front of the agent traffic, and delegation stays a feature instead of becoming a 2am incident.
Northwind and Tomás are illustrative. A clarification worth making explicitly: Agent2Agent (A2A) is an open communication protocol, while TrueFoundry Agent Gateway is TrueFoundry's product and control-plane implementation for governing agent workflows — they are different things, and this post uses A2A as the standard vocabulary for the traffic the gateway governs. TrueFoundry Agent Gateway capabilities are summarized from public product documentation as of June 2026 and will evolve; some features may be in preview. A2A is young as an enterprise adoption pattern and its ecosystem conventions will continue to evolve, so protocol specifics here are described at a high level and should be confirmed against the current specification. Code and policy samples are illustrative of the documented patterns, not copied from a reference implementation.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.
Product
Company
Resources
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
.webp){kind=link}
.webp){kind=link}
.webp){kind=link}
.webp){kind=link}
.webp){kind=link}
.webp){kind=link}
{kind=link}
.webp){kind=link}
{kind=link}
.webp){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}