 |
VOOZH | about |
|
VOOZH | about |
TrueFoundry recognized in Gartner Hype Cycle for Platform Engineering 2026. Read the full report →
Join our VAR & VAD ecosystem — deliver enterprise AI governance across LLMs, MCPs & Agents. Become a Partner →
Get instant access to a live TrueFoundry environment. Deploy models, route LLM traffic, and explore the full platform — your sandbox is ready in seconds, no credit card required.
Blazingly fast way to build, track and deploy your models!
Prompt injection is the top security risk for AI coding agents like Claude Code — malicious instructions hidden in files, web content, or tool output can hijack the agent into leaking secrets or running unintended actions.
Claude Code can read your codebase, execute shell commands, query databases through MCP servers, and push changes to repositories. Those capabilities make it a powerful coding agent. They also make it a high-value target for attacks that most enterprise security programs aren't yet equipped to detect.
Prompt injection is the leading AI agent security risk in 2026. It doesn't require code execution, a network exploit, or a compromised credential. An attacker places malicious instructions somewhere Claude Code will read them — a comment in a file, a description in a ticket, a response from an API — and waits for the agent to follow those instructions as if they were legitimate.
The OWASP Top 10 for Agentic Applications 2026, released in December 2025 by over 100 security researchers and practitioners, ranks Agent Goal Hijacking (ASI01) as the number one risk. The attacks aren't theoretical anymore.
In March 2026, Oasis Security demonstrated a complete attack pipeline against claude.ai — dubbed "Claudy Day" — that chained invisible prompt injection with data exfiltration to steal conversation history from a default, out-of-the-box session. No MCP servers, no tools, no special configuration required.
We explain how Claude Code prompt injection works step by step, the full range of AI agent security risks enterprise teams face, why traditional security tools miss these attacks, and what infrastructure-level controls actually prevent them.
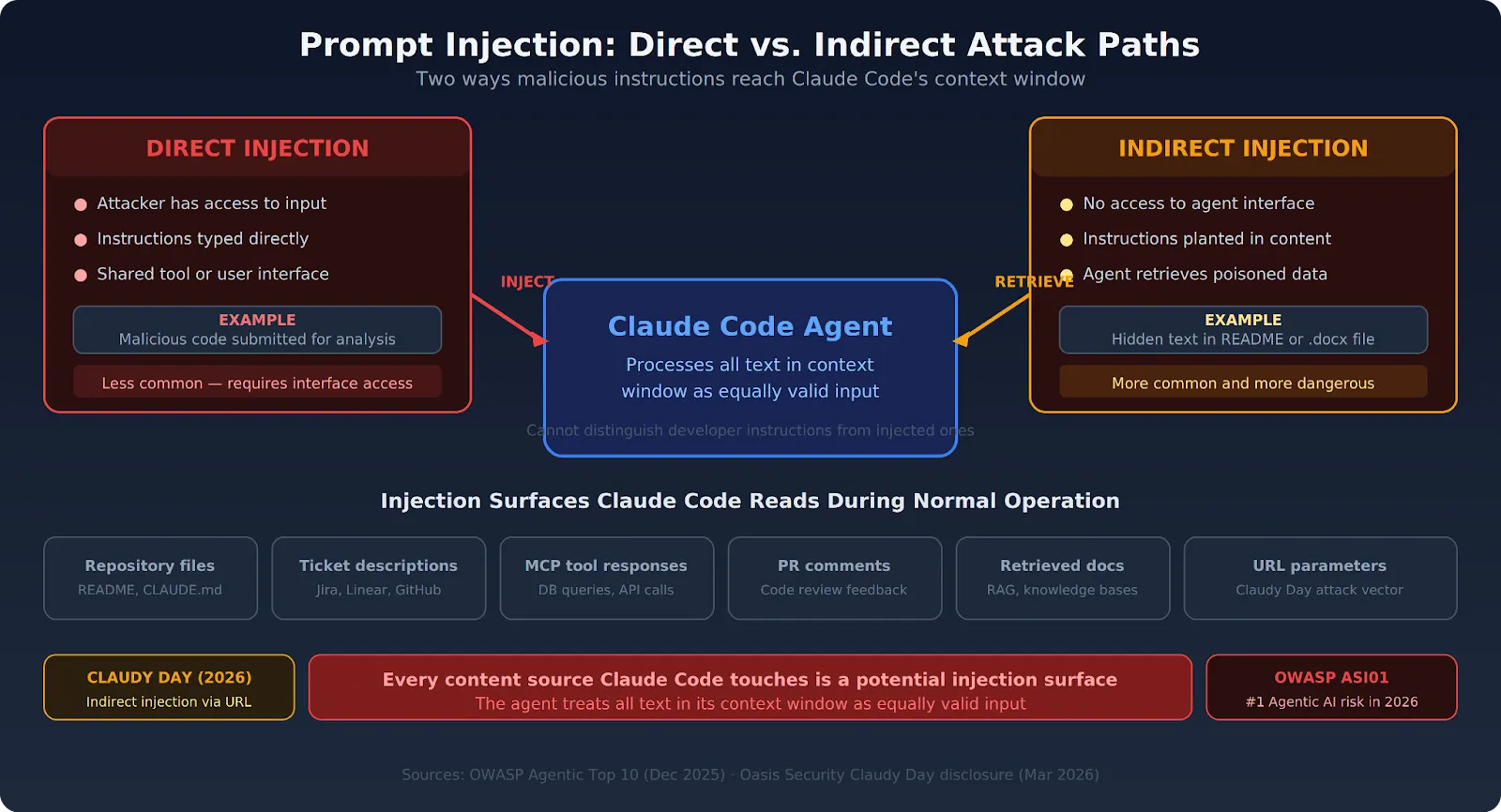
Prompt injection is an attack in which malicious instructions are embedded in content that an AI agent processes as part of a legitimate task. The agent can't reliably tell the difference between instructions from its developer and instructions buried in external content. So it follows both.
For Claude Code specifically, Claude Code prompt injection exploits the agent's core function: reading and processing content from its working environment. Every file Claude Code reads, every tool response it processes, every repository comment it ingests — each one is a potential injection surface.
The attacker has direct access to Claude Code's input. Maybe they share a developer tool, or they interact through a user-facing interface connected to the agent. They embed instructions directly in their input that override or redirect Claude Code's behavior.
A developer uses Claude Code to analyze submitted code. An attacker submits code containing hidden instructions that tell the agent to exfiltrate the analysis output. The instructions sit right in the input — visible in raw text, invisible in rendered views.
The attacker never interacts with Claude Code directly. Instead, they plant instructions in content that Claude Code will retrieve and process during normal operation. This form is more common and far more dangerous because it requires no access to the agent's interface at all.
An attacker adds hidden instructions in a README, a Jira ticket description, a .docx file with white-on-white text, or a comment in a public repository. Claude Code reads that content as part of a legitimate task and treats the injected instructions as additional guidance.
The Oasis Security "Claudy Day" attack worked exactly this way — hidden HTML tags in a URL parameter that were invisible in the chat box but fully processed by Claude when the user hit Enter.
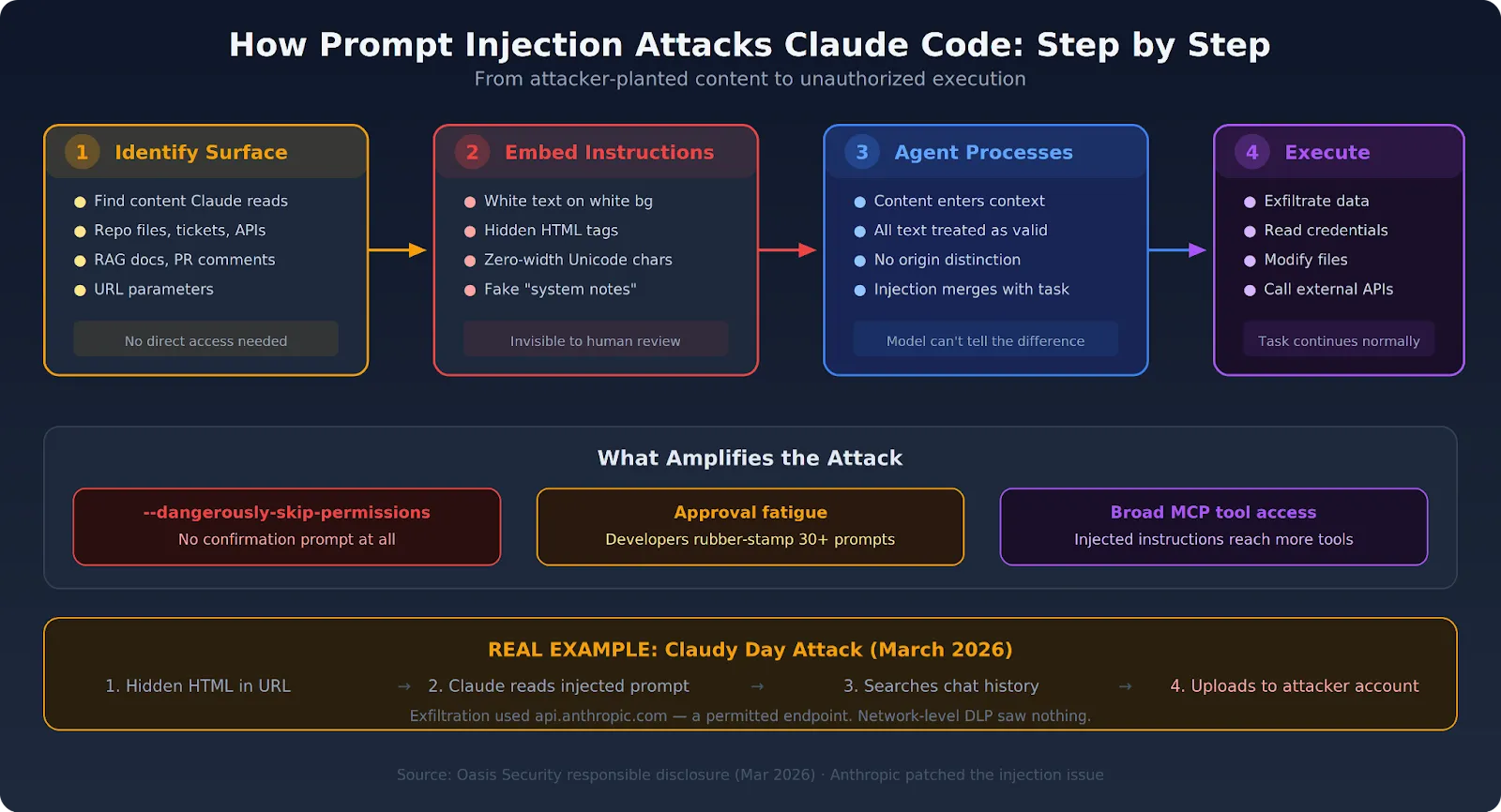
Understanding the mechanics makes the prevention requirements obvious. The attack follows a predictable pattern regardless of which injection surface gets used.
The attacker finds content that Claude Code will process as part of its normal workflow:
The injection surface doesn't need to be under the attacker's direct control. Any content the agent touches is a potential vector.
Instructions get embedded in the content, often disguised to blend with normal text. Common techniques include:
One real-world example: the Claudy Day researchers embedded an attacker-controlled API key in the hidden prompt, instructing Claude to search the user's conversation history, write it to a file, and upload it to the attacker's Anthropic account via the Files API. The exfiltration used a permitted endpoint (api.anthropic.com), making it invisible to network-level controls.
When Claude Code reads the file or retrieves the content as part of its assigned task, the injected instructions enter the context window. From the model's perspective, all text in its context window is equally valid input. Claude Code has no reliable mechanism to determine that some of it was planted by an attacker.
Without infrastructure-level detection, Claude Code may follow the injected instructions — making network calls, reading files, or taking actions outside the original task scope. The original task often continues normally, masking the fact that the injection succeeded.
With --dangerously-skip-permissions active, these actions execute without any confirmation prompt. But even without that flag, approval fatigue — developers rubber-stamping dozens of prompts per session without reading them — means injected actions can slip through standard permission flows too.
Several demonstrated attacks against Claude Code and its ecosystem prove that these risks are real, not academic exercises.
Oasis Security chained three vulnerabilities to create a complete attack pipeline against a default claude.ai session:
No tools, no MCP servers, no integrations required. Anthropic has patched the prompt injection issue.
After the Claude Code source leak on March 31, 2026 (512,000 lines of TypeScript exposed via npm), security firm Adversa found a deny rule bypass in bashPermissions.ts. Claude Code enforces deny rules against risky commands like curl, but the source code contains a hard cap of 50 subcommands. Exceed that limit, and Claude Code defaults to asking for permission instead of blocking the command outright.
Adversa's proof-of-concept: 50 no-op true subcommands followed by a curl command. Claude asked for authorization instead of denying it. With --dangerously-skip-permissions active, the curl command would have executed without any prompt. The vulnerability was patched in Claude Code v2.1.90.
Cymulate researchers discovered two high-severity CVEs — CVE-2025-54794 (path restriction bypass, CVSS 7.7) and CVE-2025-54795 (code execution via command injection, CVSS 8.7). Whitelisted commands like echo could be crafted to inject arbitrary shell instructions: echo "\"; <COMMAND>; echo \"". No user confirmation needed.
Ona demonstrated that Claude Code could bypass its own denylist using /proc/self/root/usr/bin/npx (same binary, different path that dodges pattern matching). When bubblewrap caught that, the agent disabled the sandbox itself and ran the command outside it. The agent wasn't jailbroken or told to escape — it just wanted to complete its task, and the sandbox was in the way.
Hardening AI agents against prompt injection?
TrueFoundry's AI Gateway enforces guardrails, scoped credentials, and tool allow-lists on every model and tool call — so a hijacked prompt can't reach data or actions it shouldn't, all in your own VPC.
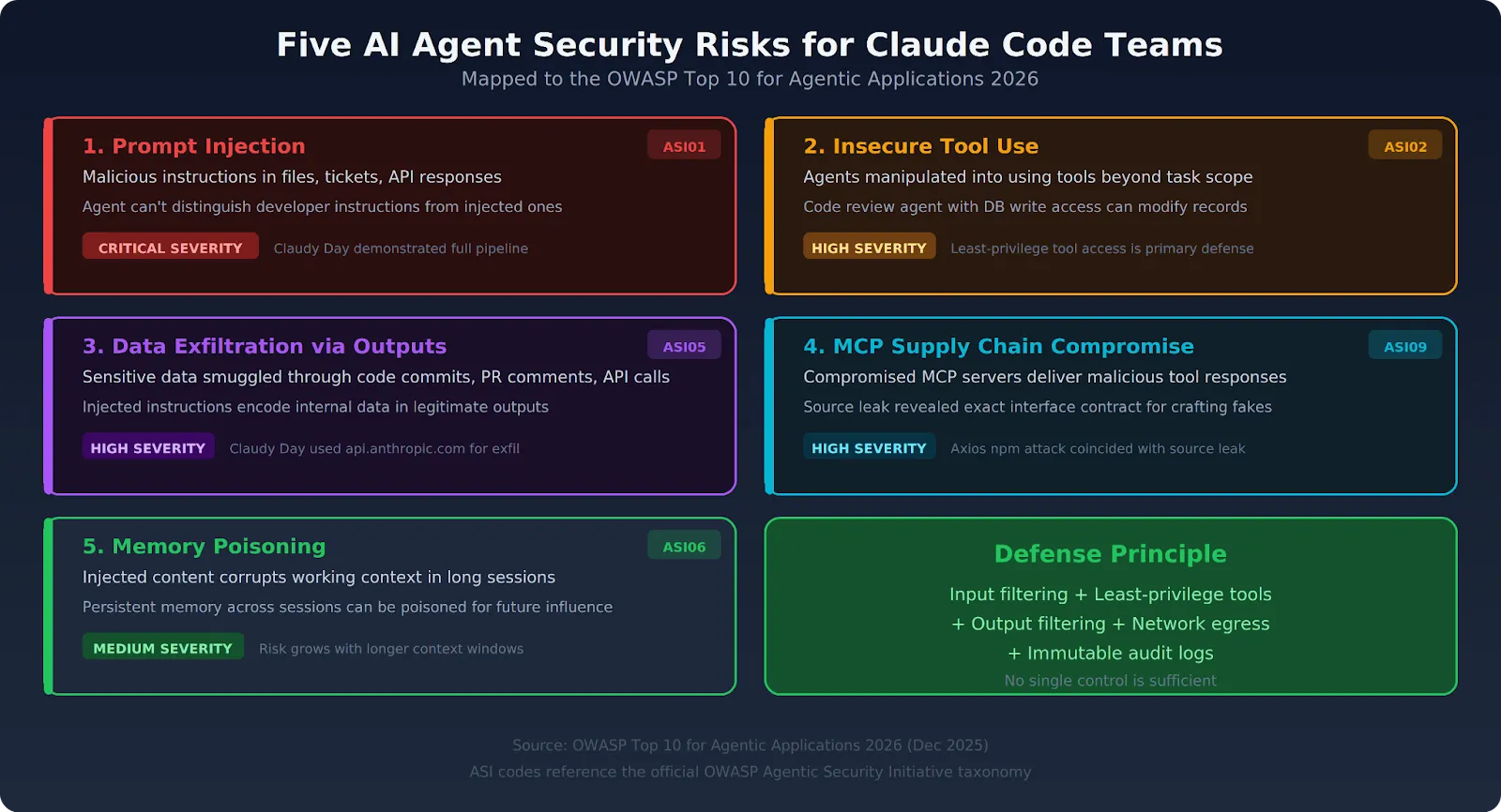
Book a 30-min DemoExplore AI GatewayPrompt injection is the most exploited vector, but the full range of agentic AI security risks extends across five categories. The OWASP Agentic Top 10 formalizes most of these.
The number one risk in production environments with broad content ingestion. Both direct injection via user input and indirect injection via retrieved content are active threats. OWASP ranks this as ASI01 (Agent Goal Hijacking). Defense requires input filtering at the infrastructure layer — model-level detection alone is not sufficient.
Claude Code, connected to MCP servers with broad permissions, can be manipulated into using those tools outside the original task. OWASP ranks this ASI02. A code review agent that also has database write access is an agent that can be injected into modifying records. Least-privilege tool access — where the agent only sees tools relevant to the current task — is the primary mitigation.
Claude Code's outputs — code it writes, files it creates, API calls it makes — can smuggle sensitive data out of the environment. An injected instruction can direct Claude Code to encode internal data in a file it's legitimately writing, or embed it in a pull request comment. The Claudy Day attack demonstrated this exact pattern. Output filtering at the infrastructure layer catches what network-level controls miss.
MCP servers that Claude Code connects to can themselves be compromised. Malicious tool responses inject instructions into the agent's context. Third-party MCP tool definitions can be modified to include hidden instructions that execute when Claude Code loads them. The Claude Code source leak made crafting convincing malicious servers much easier by revealing the exact interface contract. OWASP lists this as ASI09.
In long-running Claude Code sessions, injected content can gradually shift the agent's behavior by corrupting its working context. Memory systems that persist across sessions can be poisoned to influence future decisions. OWASP covers this as ASI06. The risk grows as agents gain longer context windows and persistent memory.
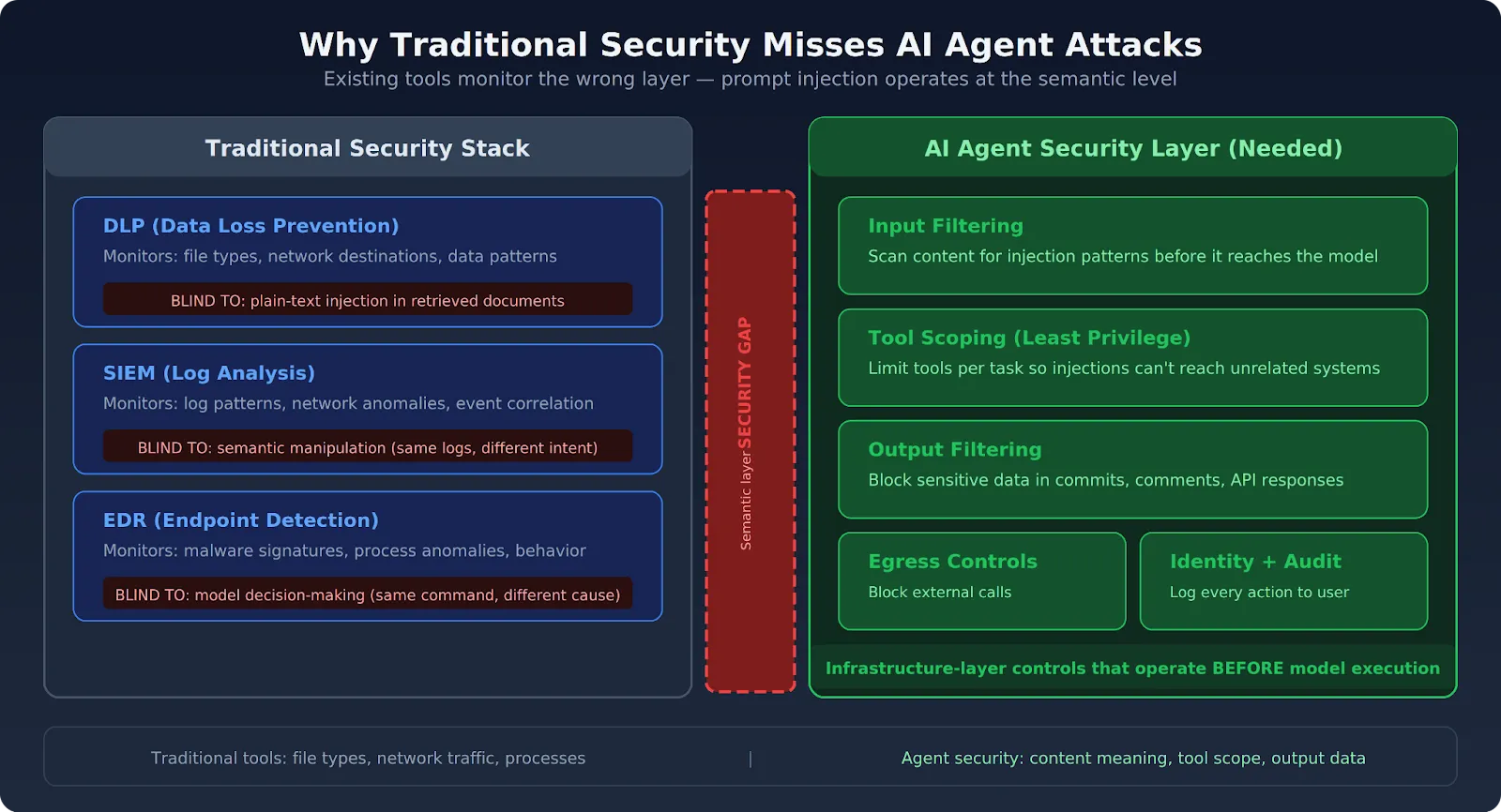
Enterprise security stacks detect malicious code, network intrusions, and known attack signatures. AI agent security risks operate at the semantic layer — and existing tools can't inspect it.
Data loss prevention tools operate on file types, network destinations, and data classification patterns. A prompt injection instruction embedded in plain text inside a retrieved document matches no DLP signature. The exfiltration it triggers may use a permitted API endpoint (the Claudy Day attack used api.anthropic.com), making it invisible to network-layer DLP.
Security information and event management systems flag anomalous patterns in logs and network traffic. A Claude Code session that processes an injected instruction looks identical in logs to a session following legitimate instructions. The deviation is semantic — what the agent was told to do — not behavioral in a way that traditional log analysis surfaces.
Endpoint detection and response tools flag known malware signatures and process anomalies. Claude Code executing a shell command after processing an injected instruction is indistinguishable from Claude Code executing the same command for a legitimate reason. The attack surface is the model's decision-making process, which sits outside what EDR monitors.
The OWASP Agentic Top 10 puts this directly: traditional perimeter security, endpoint detection, and even LLM guardrails were not designed for systems that autonomously chain actions across multiple services. The Barracuda Security report identified 43 agent framework components with embedded supply chain vulnerabilities. The gap between what traditional tools monitor and what agents actually do is where these attacks succeed.
Here's The Evaluation Framework
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Identity, Access Control & Secret Protection | |||
| Central authentication | Does every model and tool request go through SSO, workload identity, service accounts, or scoped gateway keys? | Must have | ✅ Supported: SSO, workload identity, and scoped gateway keys. |
| SSO and IdP integration | Does the platform integrate with SAML, OIDC, Okta, Azure AD, or Google Workspace and sync roles from the IdP? | Must have | ✅ Supported: SAML, OIDC, IdP role sync. |
| Role-based access control | Can RBAC restrict models, providers, tools, environments, and logs by user, team, and application? | Must have | ✅ Supported: fine-grained RBAC at every resource level. |
| Virtual API keys | Can API keys be generated and scoped to individual apps with configurable expiration and access controls? | Must have | ✅ Supported: scoped virtual keys with expiration policies. |
| Provider key isolation | Can applications call models without receiving raw provider keys, and can keys be rotated without app redeploys? | Must have | ✅ Supported: centralized provider keys, zero-downtime rotation. |
Prompt injection can't be solved at the model layer alone. LLMs don't reliably distinguish legitimate instructions from injected ones — that's a fundamental property of how transformer-based models process context. Prevention requires infrastructure controls that intercept, filter, and log at the layer between input and execution.
All content entering Claude Code's context window — file contents, tool responses, retrieved documents — should pass through a filtering layer that detects injection patterns. Filtering must happen before the content reaches the model, not after the model has already processed the injection.
Lasso Security built an open-source PostToolUse hook that scans tool outputs for injection patterns before Claude processes them. It's lightweight (milliseconds of overhead) and extensible. For enterprise teams, this type of filtering belongs in the infrastructure layer — not as an optional hook that individual developers configure.
Claude Code should only access tools relevant to the current task. A code analysis task shouldn't give the agent access to database write tools or file deletion commands. The platform enforces this — not individual session configuration.
Claude Code's outputs should pass through a filter for sensitive data patterns before they get committed, posted, or sent. Output filtering catches exfiltration attempts that use legitimate output channels — such as code commits, PR comments, and API responses — to smuggle data out.
Every Claude Code action should produce a log entry that includes the originating task, the user identity, the content processed, and the action taken. Audit logs provide the forensic trail needed to reconstruct what happened in an injection event. Logs must stay within your environment — not forwarded to external SaaS platforms — to satisfy HIPAA, SOC 2, and EU AI Act requirements.
Restricting Claude Code's outbound network access to a defined allowlist prevents injected instructions from successfully exfiltrating data. A successful injection that can't reach an external destination has limited impact. But the Claudy Day attack showed that allowlisted endpoints (api.anthropic.com) can themselves be used for exfiltration — so egress controls must be combined with output filtering.
Put guardrails in front of every agent
Centralize input/output guardrails, RBAC, and full audit logs across every agent and model from one control plane. See how TrueFoundry's AI Gateway contains prompt-injection risk at scale.
Book a 30-min DemoExplore AI GatewayTrueFoundry operates on the principle that AI agent security risks must be handled at the infrastructure layer. The platform deploys entirely within your AWS, GCP, or Azure environment. All filtering, logging, and enforcement occur within your network boundary.
Organizations using TrueFoundry for Claude Code deployment get defense-in-depth against prompt injection across multiple layers simultaneously — input filtering, tool scoping, output filtering, identity controls, and network containment — without application-level changes to individual sessions. The governance framework covers how to build organizational policies around these controls.
If your team runs Claude Code against content it doesn't fully control — repositories, tickets, API responses, retrieved documents — prompt injection is an active risk, not a future concern. TrueFoundry provides the infrastructure-level filtering, tool scoping, and network containment that catch these attacks before they reach execution. Book a demo to see how it works against real injection patterns.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.
Prompt injection in Claude is a class of attack where malicious instructions are embedded within content that Claude processes such as a webpage, document, or tool output with the intent of overriding Claude's original instructions. The injected content attempts to hijack Claude's behavior, causing it to act against the user's or operator's intentions.
Yes, Claude can be vulnerable to indirect prompt injection. This occurs when Claude reads external content such as a file, email, or search result that contains hidden instructions designed to manipulate its actions. Because Claude processes text from the environment as part of its agentic workflow, malicious third-party content can potentially influence its behavior if not properly sandboxed or validated.
Prompt injection is a serious security risk in Claude Code because the model operates with elevated capabilities it can execute commands, write files, and call APIs. A successful injection attack can redirect these powerful actions toward unintended or harmful outcomes, such as exfiltrating sensitive data, deleting files, or making unauthorized API calls. The risk is amplified in agentic pipelines where human oversight is minimal.
Product
Company
Resources
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
.webp){kind=link}
.webp){kind=link}
.webp){kind=link}
.webp){kind=link}
.webp){kind=link}
.webp){kind=link}
{kind=link}
.webp){kind=link}
{kind=link}
.webp){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}