Get instant access to a live TrueFoundry environment. Deploy models, route LLM traffic, and explore the full platform — your sandbox is ready in seconds, no credit card required.
In modern generative AI systems, the AI Gateway functions as the critical proxy layer between applications and language model (LLM) providers. It plays a central role in managing reliability, observability, access control, and cost-efficiency for every request flowing into production.
Because the gateway lies in the critical path of production traffic, it must be designed with the following core principles in mind:
Key Architectural Priorities:
High Availability: The gateway must not become a single point of failure. Even in the face of dependency issues (like database or queue outages), it should continue serving traffic gracefully.
Low Latency: Since it sits inline with every inference request, the gateway must add minimal overhead to ensure a snappy user experience.
High Throughput and Scalability: The system should scale linearly with load and be able to handle thousands of concurrent requests with efficient resource usage.
No External Dependencies in the Hot Path: Any network-bound or disk-bound operations should be offloaded to asynchronous systems to prevent performance bottlenecks.
In-Memory Decision Making: Critical checks like rate limiting, load balancing, authentication, and authorization should all be performed in-memory for maximum speed and reliability.
Separation of Control Plane and Proxy Plane: Configuration changes and system management should be decoupled from live traffic routing, enabling global deployments with regional fault isolation.
TrueFoundry's AI Gateway Architecture
TrueFoundry’s AI Gateway embodies all of the above design principles, purpose-built for low latency, high reliability, and seamless scalability
Key Characteristics of the AI Gateway Architecture
Built on Hono Framework: The gateway leverages Hono, a minimalistic, ultra-fast framework optimized for edge environments. This ensures minimal runtime overhead and extremely fast request handling.
Zero External Calls on Request Path: Once a request hits the gateway, it does not trigger any external calls (unless semantic caching is enabled). All operational logic is handled internally, reducing risk and boosting reliability.
In-Memory Enforcement: All authentication, authorization, rate-limiting, and load-balancing decisions are made using in-memory configurations, ensuring sub-millisecond response times.
Asynchronous Logging: Logs and request metrics are pushed to a message queue asynchronously, ensuring that data observability does not block or slow down the request path.
Fail-Safe Behavior: Even if the external logging queue is down, the gateway will not fail any requests. This guarantees uptime and resilience under partial system failures.
Horizontally Scalable: The gateway is CPU-bound and stateless, which makes it easy to scale out. It performs efficiently under high concurrency and low memory usage.
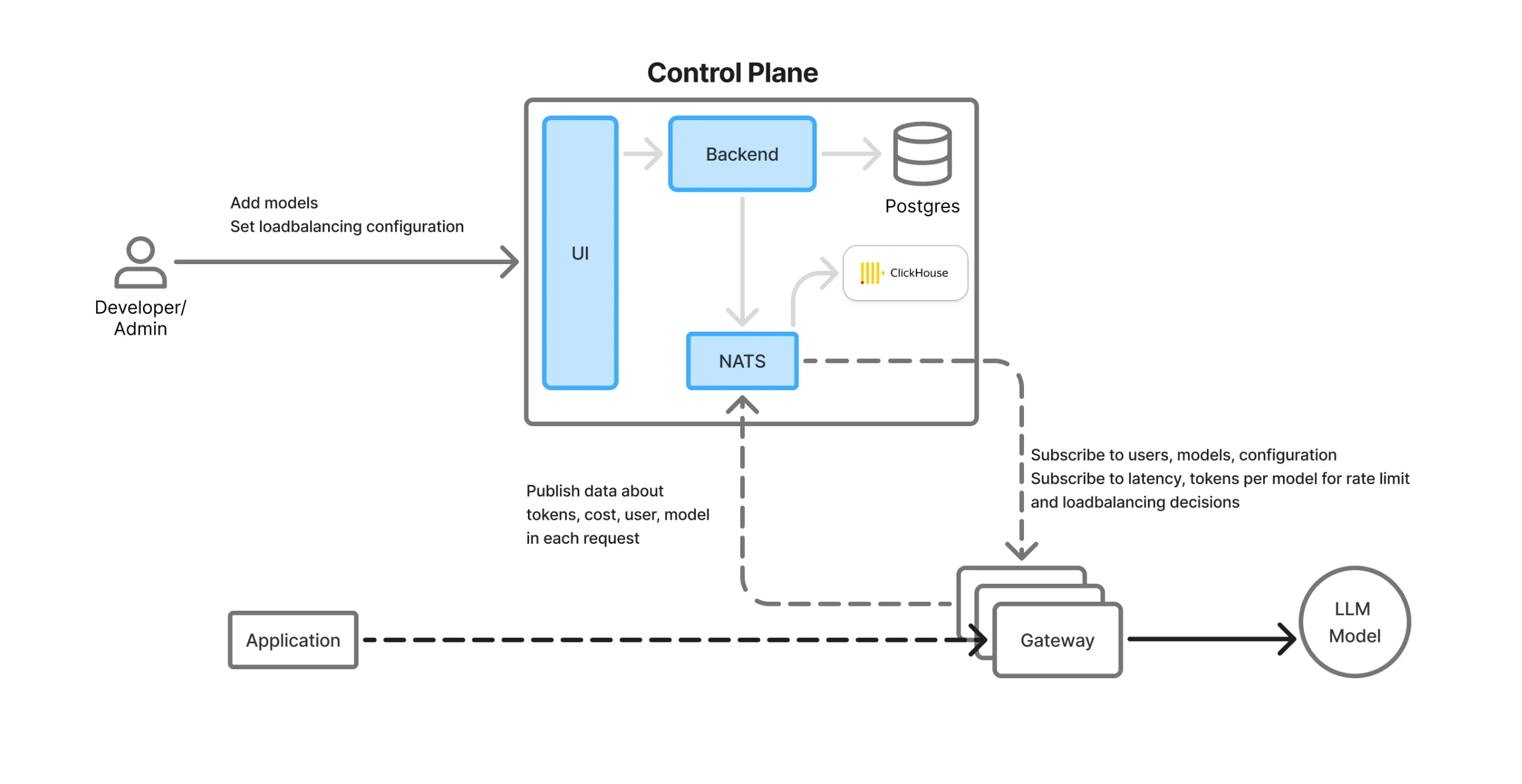
Control Plane & Data Flow
TrueFoundry separates the control plane (management) from the data plane (real-time traffic routing) for scalability and flexibility.
Components Overview of the AI Gateway:
UI: Web interface with an LLM playground, monitoring dashboards, and config panels for models, teams, rate limits, etc.
ClickHouse: High-performance columnar database used for storing logs, metrics, and usage analytics.
NATS Queue: Acts as a real-time sync bus between control plane and distributed gateway pods. All config/state updates are pushed through NATS and instantly available in all regions.
Backend Service: Orchestrates config syncing, database updates, and analytics ingestion.
Gateway Pods: Stateless, in-region, lightweight proxies that handle actual LLM traffic. They consume NATS messages and perform all logic in-memory, with no external dependencies.
Key Metrics for Evaluating Gateway
Criteria
What should you evaluate ?
Priority
TrueFoundry
Latency
Adds <10ms p95 overhead for time-to-first-token?
Must Have
✅ Supported
Data Residency
Keeps logs within your region (EU/US)?
Depends on use case
✅ Supported
Latency-Based Routing
Automatically reroutes based on real-time latency/failures?
Performance Benchmarks for TrueFoundry's AI Gateway
TrueFoundry's Gateway has been thoroughly benchmarked for performance under production-like loads:
250 RPS on 1 CPU/1GB RAM with only 3 ms added latency.
Scales efficiently up to 350 RPS per pod before hitting CPU saturation, beyond which you can add replicas.
Supports tens of thousands of RPS with horizontal scaling across regions.
No additional latency even with multiple rate-limit, auth, and load-balance rules in place.
Why This Matters
If you're running genAI workloads at scale, or planning to integrate multiple LLMs (OpenAI, Claude, open source, etc.), the gateway becomes the foundation of your stack.
TrueFoundry's design ensures:
You can route and scale safely across providers.
Apply fine-grained controls at user/team-level.
Maintain observability and governance across the system while controlling the cost of generative AI.
Do all of this without impacting latency or reliability.
Book a demo now if you want to get started with AI Gateway.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
.webp){kind=link}
.webp){kind=link}
.webp){kind=link}
.webp){kind=link}
.webp){kind=link}
.webp){kind=link}
{kind=link}
.webp){kind=link}
{kind=link}
.webp){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}