 |
VOOZH | about |
|
VOOZH | about |
TrueFoundry recognized in Gartner Hype Cycle for Platform Engineering 2026. Read the full report →
Join our VAR & VAD ecosystem — deliver enterprise AI governance across LLMs, MCPs & Agents. Become a Partner →
Get instant access to a live TrueFoundry environment. Deploy models, route LLM traffic, and explore the full platform — your sandbox is ready in seconds, no credit card required.
Blazingly fast way to build, track and deploy your models!
A walkthrough of the auth architecture inside the TrueFoundry MCP Gateway — three planes, two OAuth flows, one credential vault — told through the lens of a customer rolling it out in production.
A Monday morning at Northwind. At 8:47 a.m. on a Monday, the on-call engineer at Northwind Logistics — a fictional but unfortunately plausible 50-engineer supply chain platform — gets a Slack ping. Their internal AI assistant, Cargo Copilot, is returning 401s for every Jira and GitHub tool call. The root cause is a developer's laptop, lost at the airport over the weekend. IT has revoked the laptop's SSO session. But the laptop also held OAuth tokens for GitHub, Slack, Jira, and an internal analytics service, each copied into the developer's editor settings and dotfiles. Security cannot say with confidence which scopes were exposed, on which other machines those tokens were also mirrored (because developers help each other), or how to revoke them all without breaking everyone's morning.
Northwind's incident is not exotic. It is what credential management looks like at most companies six months into enthusiastic MCP adoption. The rest of this post is the architectural story of how Northwind — and other TrueFoundry customers — stop reproducing this incident.
Northwind has roughly fifty engineers actively using MCP-capable IDEs against eight servers — GitHub, Slack, Google Workspace, Jira, an internal analytics service, an internal Logistics API, Zendesk, and a proprietary route-planning service. That is four hundred active connections by the obvious arithmetic, and in practice substantially more credential placements once you count keychain entries, editor settings, shell environment files, CI variables, and the copies people make when onboarding a teammate.
The blast radius of a leaked workstation is not one token. It is one token multiplied by the scopes attached to that provider, the lifetime of the token (often 90 days or longer for personal access tokens), the number of machines that mirrored it, and the absence of central revocation. If a Slack OAuth token allows channel history reads and a co-located GitHub token allows repository reads, a single exfiltration becomes a cross-system incident before the security team has a chance to respond. Local MCP credentials are also operationally invisible: no unified audit trail, no enforced rotation, no policy check before a tool is executed, no fast way to answer who can call what.
The gateway pattern closes the gap. Developers authenticate once to the gateway, and the gateway handles downstream authentication according to each server's configured model — which is exactly the design described in the TrueFoundry MCP Gateway overview and the Authentication and Security docs. The benefit is not just consolidation. It is that auth becomes a property of the infrastructure rather than a property of every laptop in the company.
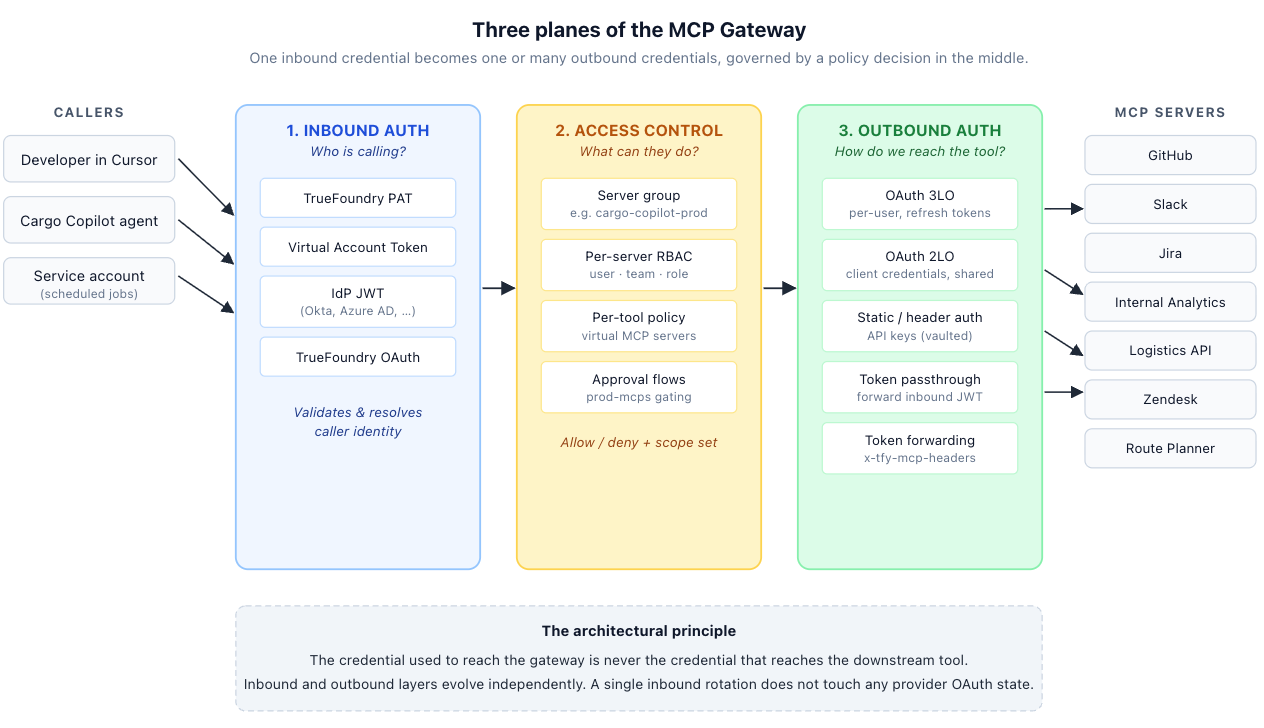
The first design decision is to separate three planes that local developer setups routinely conflate. The TrueFoundry Authentication and Security docs describe this as a three-part system: inbound authentication, access control, and outbound authentication. The docs are explicit that the inbound and outbound layers are independent, which is the architectural win.
The design principle is simple: the credential used to reach the gateway is never the credential that reaches the downstream tool. Inbound rotation does not touch any provider OAuth state. A GitHub MCP server can use per-user OAuth while the internal analytics service uses Client Credentials — in the same agent, in the same request flow. The gateway is both the policy enforcement point and the credential broker.
In enterprise shorthand, 2LO and 3LO refer to two grant types from RFC 6749 (OAuth 2.0), mapped onto how end users participate.
Two-legged OAuth (2LO) uses the Client Credentials grant. The gateway holds a client_id and client_secret, posts grant_type=client_credentials to the provider's token endpoint, receives a short-lived access_token, and uses that token on every request to the MCP server. No browser, no user consent. It is the right choice for server-to-server integrations: internal analytics APIs, backend microservices, internal data services.
Three-legged OAuth (3LO) uses the Authorization Code grant. Each end user is redirected to the provider (GitHub, Slack, Google) to authorize access to their specific resources. The gateway stores a per-user refresh_token, maintains an encrypted mapping of user_id → {access_token, expires_at, refresh_token, scopes, provider_metadata}, and rotates the access token automatically.
| Flow | OAuth grant | Who authorizes | Best MCP fit |
|---|---|---|---|
| 2LO | Client Credentials | The gateway, as a confidential client | Internal analytics APIs, backend microservices, shared internal data services |
| 3LO | Authorization Code | Each end user, via browser consent | Slack, GitHub, Google Workspace, Atlassian, CRM tools with per-user data |
How Northwind chose
Northwind's eight MCP servers split roughly down the middle. GitHub, Slack, Jira, Google Workspace, and Zendesk are all per-user tools — the value of "run this as Alice" outweighs the operational overhead of a per-user token. Those go on 3LO. The internal analytics service, the Logistics API, and the route-planning service all expose company-wide data; no per-user OAuth makes sense, and a single shared Client Credentials grant is both simpler and easier to audit. Those go on 2LO.
Note on this configuration view
TrueFoundry registers MCP servers through the UI (Settings → MCP Servers → Add MCP Server) rather than through a customer-managed YAML file, though configuration can also be applied declaratively via tfy apply. The YAML below shows the per-server configuration model — the same fields you fill in the UI — using TrueFoundry's verified schema (provider-account/mcp-server-group with nested integrations).
# Northwind's backend-group MCP Server Group: two MCP servers, one per OAuth flow.# Schema matches TrueFoundry's provider-account / integrations pattern (tfy apply).name:backend-grouptype:provider-account/mcp-server-groupcollaborators:-subject:team:platform-engineeringrole_id:mcp-server-manager-subject:team:site-reliabilityrole_id:mcp-server-manager-subject:virtualaccount:cargo-copilot-runtimerole_id:mcp-server-managerintegrations:# ---- 3LO (Authorization Code): per-user OAuth on GitHub -----name:githubtype:integration/mcp-server/remotedescription:GitHubMCPserverusingper-userOAuthAuthorizationCodeflow.url:https://github-mcp.example.com/mcptransport:streamable-httpauthorized_subjects:-team:platform-engineering-team:site-reliability-virtualaccount:cargo-copilot-runtimeauth_data:type:oauth2grant_type:authorization_codeauthorization_url:https://github.com/login/oauth/authorizetoken_url:https://github.com/login/oauth/access_tokenclient_id:tfy-secret://northwind:github-oauth:client_idclient_secret:tfy-secret://northwind:github-oauth:client_secretscopes:-repo-read:orgjwt_source:access_tokencode_challenge_methods_supported:-S256# ---- 2LO (Client Credentials): shared service identity -----name:internal-analyticstype:integration/mcp-server/remotedescription:InternalanalyticsMCPserverusingOAuth2ClientCredentials.url:https://analytics-mcp.internal.example.com/mcptransport:streamable-httpauthorized_subjects:-team:platform-engineering-team:site-reliabilityauth_data:type:oauth2grant_type:client_credentialstoken_url:https://northwind.okta.com/oauth2/default/v1/tokenclient_id:tfy-secret://northwind:analytics-oauth:client_idclient_secret:tfy-secret://northwind:analytics-oauth:client_secretscopes:-analytics:readjwt_source:access_tokenThe command of applying the above yaml is:
tfy apply -f backend-group.yaml --dry-run --show-diffThree things to notice. First, tfy-secret:// is the canonical FQN reference scheme TrueFoundry uses for secrets stored in a TrueFoundry secret group, with the colon-separated format tfy-secret://<tenant>:<secret-group>:<secret-key> documented in the Environment Variables and Secrets guide. The value lives in your secret manager (AWS SSM, GCP Secret Manager, HashiCorp Vault, Azure Key Vault); TrueFoundry resolves the FQN at runtime, so the file above is safe in a Git repo. Second, authorized_subjects is the per-server RBAC list — a mix of teams and virtual accounts — which is what makes it possible for the same MCP server to serve human developers (whose PATs resolve to team membership) and scheduled service-account jobs (whose Virtual Account Tokens map to virtualaccount: subjects) without configuration drift. Third, the 3LO entry sets code_challenge_methods_supported: [S256] — PKCE is recommended for every Authorization Code client today and mandatory in the newer 2025-11-25 MCP specification.
On the client side, the agent never enumerates auth modes. It dials one gateway URL, presents one inbound credential, and the gateway injects the right outbound credential per server:
from fastmcp import Client
from fastmcp.client.transports import StreamableHttpTransport
# Real URL pattern from the TrueFoundry docs.transport = StreamableHttpTransport(
url="https://llm-gateway.truefoundry.com/mcp-server/backend-group/github/server",
headers={"Authorization": f"Bearer {user_token}"},
)
asyncwith Client(transport) as client:
result = await client.call_tool(
"search_issues",
{"query": "repo:northwind/logistics-core is:open label:critical"},
)OAuth correctness is not only about getting tokens. It is about operating them safely under concurrent load. The naive design refreshes when the provider returns 401, or when now ≥ expires_at. That design works in demos and fails the first Monday it meets reality.
Replay the Northwind incident with naive refresh: at 8:47 a.m. Monday, fifty engineers come online, every worker independently discovers the same expired GitHub token, fifty parallel POST /token calls hit GitHub from the same gateway, and GitHub rate-limits the lot. Cargo Copilot returns 401s to everyone until the queue drains.
The pattern that holds up in production has two ingredients: refresh proactively at 80% of TTL, and serialize the refresh per (user, server) with a distributed lock.
defget_token(user_id, server_id): token = cache.get(user_id, server_id)
if now() < token.issued_at + 0.8 * token.expires_in:
return token
# Crossed the 80% threshold. Serialize refresh so 50 workers# do not all hit the provider token endpoint at once.with distributed_lock(user_id, server_id):
token = cache.get(user_id, server_id) # re-read under lockif now() < token.issued_at + 0.8 * token.expires_in:
return token # someone else already refreshed new = provider.refresh(token.refresh_token)
vault.put_atomic(user_id, server_id, new) # access + refresh together cache.set(user_id, server_id, new)
return newRefreshing at 80% of TTL leaves margin for clock skew, retries, slow provider token endpoints, and requests already in flight. The per-(user, server) lock prevents a thundering herd against the provider. The double-checked read inside the lock is not cosmetic: it lets the first request perform the refresh while the rest reuse the freshly written token.
Two subtleties matter at scale. First, for Client Credentials integrations the cache key is (server_id, provider_account); for Authorization Code integrations the key must include user_id. Second, providers that rotate refresh tokens on every refresh — Google and Microsoft do, depending on configuration — require the write to be atomic. If the new access_token is committed before the new refresh_token, a crash leaves the user stranded with an invalidated old refresh token and a forced re-authentication.
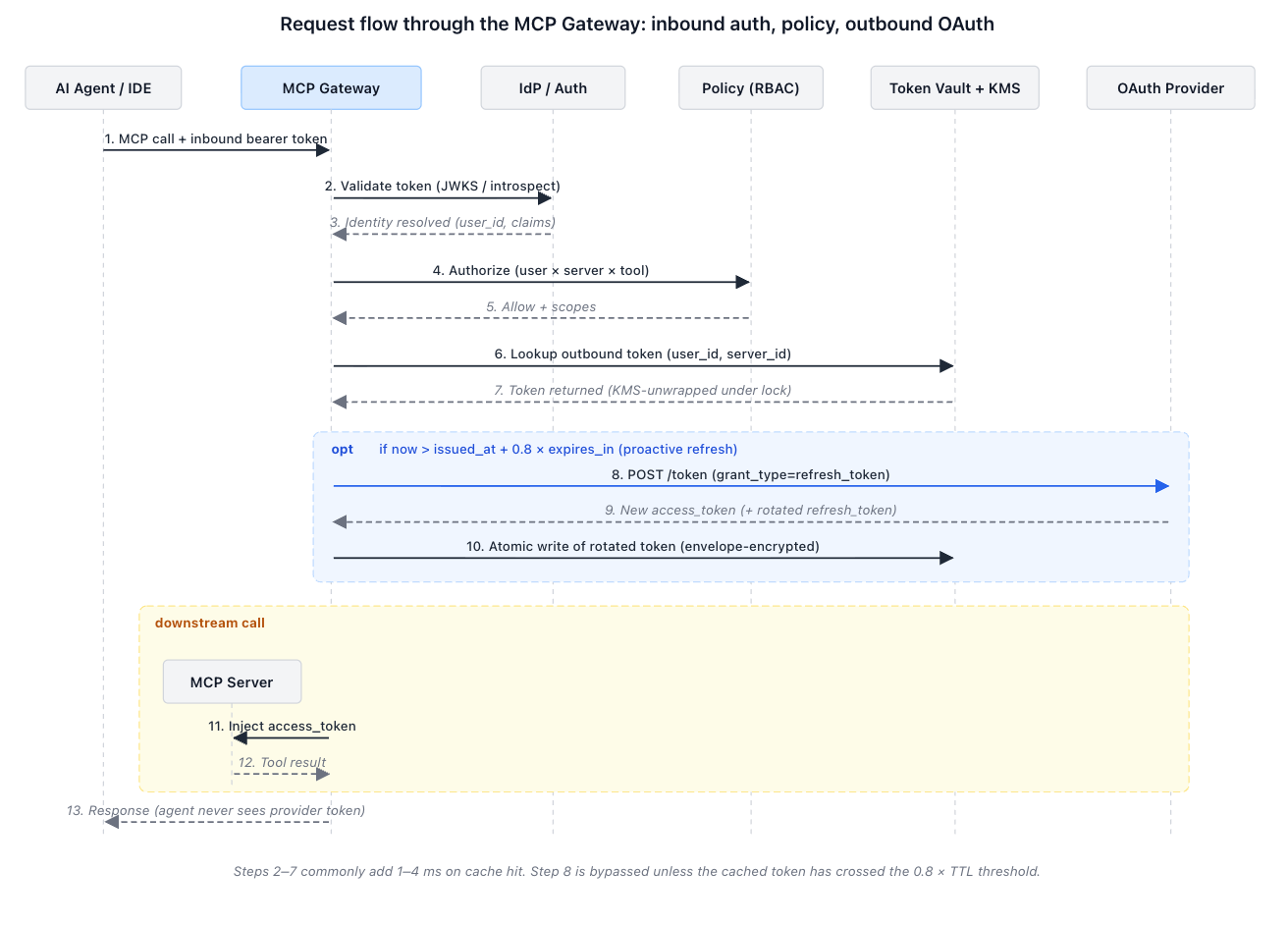
With the planes separated and the refresh path defined, an end-to-end MCP request through the gateway has a precise shape. Trace one Cargo Copilot call — "summarize the open critical-severity issues in repo northwind/logistics-core" — from agent to GitHub and back:
Three properties of this flow are worth pointing out. The agent never receives the GitHub access token; only the gateway holds it. The MCP server never sees Northwind's inbound TrueFoundry credential unless Token Passthrough is explicitly configured (more on that in §7). And the Northwind security team gets a single governed request path with identity, authorization, and audit recorded in one place — the same property that would have let them answer the Monday-morning question, "which scopes were on that laptop?", in under a minute.
The MCP authorization specification reinforces one part of this picture: bearer access tokens must be sent in the Authorization request header and never in a URI query string. That norm matters precisely because it keeps tokens out of access logs, browser history, and proxy traces.
A production gateway should not treat OAuth refresh tokens like ordinary application rows. Client secrets and refresh tokens are long-lived keys to the kingdom — leaking a Slack refresh token is, for most purposes, equivalent to leaking the Slack workspace.
The standard pattern is envelope encryption. The gateway generates a random data encryption key (DEK) for each token record, encrypts the OAuth secret with that DEK, encrypts the DEK with a master key in KMS or a secret manager, and stores the encrypted DEK alongside the ciphertext. On read, the gateway asks the vault to decrypt only the DEK, then decrypts the token in a narrowly scoped code path that avoids logging or serializing plaintext.
In stricter deployments, token exchange itself can be pushed into a sidecar or a vault transit operation, so application code never receives raw client_secret material at all. Even with vanilla envelope encryption the blast radius changes substantially: a database dump alone is insufficient (the DEKs are not stored decrypted), and a memory dump of a general request worker is much less likely to contain broad credential material (only the keys recently requested are decrypted, and only for the duration of the request).
Northwind's deployment uses AWS KMS as the master key store and the TrueFoundry secrets store for the encrypted material. The gateway never reads a provider client_secret directly; it reads a TrueFoundry secret FQN, fetches the ciphertext, and asks KMS to unwrap. The deployment-specific work that remains — KMS key rotation policy, audit retention, operational runbooks — is the responsibility of every enterprise running the gateway, and worth a dedicated review.
Two patterns sound similar and have very different security implications. They are worth distinguishing carefully because misusing either one undoes most of the gateway's value.
| Pattern | What happens | When to use | Security implication |
|---|---|---|---|
| Token Passthrough | The gateway forwards the inbound TrueFoundry token or IdP JWT to the MCP server unchanged. | The downstream server trusts the same IdP or TrueFoundry token issuer the gateway just validated. | Server sees caller identity directly. Only safe with strict audience and issuer validation, ideally with RFC 8707 resource indicators. |
| Token Forwarding | The client supplies custom headers via x-tfy-mcp-headers, which the gateway forwards to the MCP server. |
The MCP server has its own auth system the gateway does not manage (legacy or custom auth). | Custom headers override configured outbound auth. Should be restricted, audited, and treated as an exception path. |
Token Passthrough is appropriate for internal MCP servers that validate the same enterprise identity token the gateway already validated inbound. Northwind's Logistics API is one example: the gateway and the API both trust the company's Okta tenant, so passing through the Okta JWT keeps the caller's identity intact end-to-end. The risk is token audience confusion: a token minted for the gateway should not automatically be valid for every MCP server. RFC 8707 (Resource Indicators) exists precisely to bind tokens to an intended resource, and the MCP authorization spec now requires that clients include a resource parameter and that servers validate that presented tokens were issued for them.
Token Forwarding works differently. TrueFoundry's x-tfy-mcp-headers header carries a stringified JSON keyed by the remote MCP server identifier in <group>/<server> format. Here is the format verbatim from the Virtual MCP Server docs:
import json
from fastmcp import Client
from fastmcp.client.transports import StreamableHttpTransport
extra_headers = json.dumps({
# Custom auth for the backend-group/sentry MCP server backing this# virtual server. Overrides whatever outbound auth was configured."backend-group/sentry": {"Authorization": "Bearer your-sentry-token"},
})
transport = StreamableHttpTransport(
url="https://llm-gateway.truefoundry.com/mcp-server/backend-group/restricted-sentry/server",
headers={
"Authorization": f"Bearer {tfy_token}", # inbound auth (gateway)"x-tfy-mcp-headers": extra_headers, # outbound override },
)Treat Token Forwarding as an emergency hatch, not a default. The gateway's value is exactly the token management it skips.
A gateway adds work before the downstream MCP call: inbound auth validation, policy lookup, token lookup, and occasionally a refresh. In a healthy deployment the common path is a cache hit — token metadata is valid, the encrypted token reference is warm in memory.
| Component | Typical cost | Source |
| HS256 JWT verify | ~5–10 µs | Independent JWT verification benchmarks |
| RS256 JWT verify | ~100–200 µs | WorkOS "RS256 vs HS256" analysis; same independent benchmarks |
| In-memory token cache fetch | sub-µs to a few µs | Process-local data structure access |
| External cache (Redis) round-trip | ~1–2 ms | Standard Redis intra-DC latency |
| AWS KMS Decrypt (warm) | <10 ms typical | AWS KMS guidance on decrypt latency once DEKs are cached |
| OAuth provider /token call | ~250–400 ms average | Okta Concurrency Limits docs cite 250–400 ms as their own typical API response window |
Combining the component costs above, the gateway adds roughly:
| Scenario | p50 added latency | p95 added latency | What contributes |
|---|---|---|---|
| Cache hit (valid token in memory) | ~1–2 ms | ~3–4 ms | JWT/PAT verify (µs) + RBAC lookup (µs) + in-memory cache fetch (µs). Tail set by GC pauses and JWT key fetch caching. |
| Cache miss, no refresh (warm vault) | ~5–8 ms | ~15–25 ms | Adds an encrypted-token fetch and a KMS Decrypt call (<10 ms warm per AWS). Becomes a hit on the next request. |
| Cache miss + provider refresh | ~250 ms | ~400–600 ms | Synchronous POST /token to the OAuth provider, which Okta itself cites at 250–400 ms average. Tail is provider geography, TLS reuse, retries, and lock wait time. |
Two takeaways. First, the common path is a cache hit, and at single-digit milliseconds it is invisible against the surrounding LLM call (typically hundreds of milliseconds to seconds) and the downstream MCP server (typically tens to hundreds of milliseconds). Second, the cache-miss-plus-refresh path is rare but expensive enough to matter when it stacks up under load — which is exactly why §4 specifies proactive refresh at 80% of TTL with a per-(user, server) lock. With proactive refresh, real users almost never see the refresh latency on the request path; the gateway has already prefetched a new token.
Every team should still instrument server-timing headers, token endpoint duration, lock wait time, vault decrypt time, and downstream MCP latency separately. The goal is to prove that token management is not the dominant cost in the agent's end-to-end tool call — the envelopes above suggest it almost never is, but you should verify with your own provider mix.
The operational fix for the cache-miss case is background refresh. When the gateway sees a token cross the 80% threshold, it refreshes on the request path once, then schedules subsequent refreshes before users notice. For high-volume shared Client Credentials integrations this almost eliminates user-visible refresh latency. For per-user Authorization Code integrations, the system can prioritize active users and frequently used MCP servers.
| Dimension | Before: scattered local credentials | After: centralized MCP gateway |
|---|---|---|
| Auditability | Fragmented logs across IDEs, shells, and provider dashboards. No correlation by user or tool. | One governed ingress path with identity, tool, server, and outcome context. Single query answers "who called what." |
| Revocation speed | Find every copied token on every developer machine. Hours to days, often incomplete. | Revoke gateway access or remove server/tool permissions centrally. Seconds. |
| Rotation | Manual, inconsistent, often delayed past expiry. Tokens routinely live 90+ days. | Central lifecycle with proactive 80% refresh and provider-specific rotation. Atomic access + refresh writes. |
| Blast radius | A leaked workstation may expose every configured MCP server token across every scope. | One inbound token plus policy enforcement; downstream tokens stay vaulted. The leaked token can be revoked centrally. |
| Compliance | Difficult to prove least privilege, prior consent, or who accessed what when. Audits stretch to weeks. | Cleaner evidence for RBAC, approvals, usage, and credential custody. Audit log is the single source of truth. |
No. The MCP authorization specification makes authorization optional, but HTTP-based implementations that support it should conform to the spec. In practice, enterprises with non-trivial tool estates should centralize auth long before they consider it strictly mandatory.
No. Use Authorization Code (3LO) when the agent acts on a human user's resources — Slack, GitHub, Gmail, CRM tools. Use Client Credentials (2LO) when the downstream server authenticates the application or gateway as itself. Mixing both within one Virtual MCP Server is normal and expected.
No. It complements them. Slack, GitHub, Google, and internal APIs still enforce their own scopes and resource permissions. The gateway adds a coarser, faster layer of policy on top — server-level, tool-level, team-level — and a uniform audit trail across all of them.
The TrueFoundry gateway speaks the OAuth 2.0 grants real-world providers support today: Authorization Code (with PKCE), Client Credentials, and refresh tokens. The MCP authorization specification itself targets OAuth 2.1, which is largely OAuth 2.0 plus the security best practices that are already considered mandatory in modern deployments (PKCE everywhere, no implicit grant, no password grant). For practical purposes the two are convergent; we follow OAuth 2.1 guidance where it tightens behavior.
The November 2025 revision adds mandatory PKCE for all clients, formalizes Client ID Metadata Documents (CIMD) as the preferred client registration method, and introduces step-up authorization for incremental scope consent. These tighten security without invalidating the architecture in this post. We are tracking them and rolling support in as it matures across the ecosystem.
The TrueFoundry MCP Gateway is a production implementation of this architecture: a centralized server registry, configurable inbound auth, access control, multiple outbound auth modes, and token lifecycle management. This post describes the design; the Authentication and Security docs are the operational reference. For the implementation patterns covered here, see also the docs on Auth Overrides and Virtual MCP Server.
If you are a platform, security, or AI infrastructure leader running MCP at non-trivial scale, the highest-leverage action is to inventory every MCP server in active use, map each one to the correct inbound, policy, and outbound auth model, and decide where centralization actually wins. Northwind's mapping took two afternoons; the migration itself took a single sprint. We are happy to walk through that exercise with your team.
Read the architecture: TrueFoundry MCP Gateway authentication and security. Or book an enterprise security architecture review with our team.
All citations in this post are linked inline. The references below collect the same URLs for printability and link-rot insurance.
Note: Northwind Logistics is a fictional company used to ground the design in a concrete deployment. The configuration model shown in §3 is illustrative; production MCP servers are registered through the TrueFoundry UI or applied via tfy apply.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.
Product
Company
Resources
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
.webp){kind=link}
.webp){kind=link}
.webp){kind=link}
.webp){kind=link}
.webp){kind=link}
.webp){kind=link}
{kind=link}
.webp){kind=link}
{kind=link}
.webp){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}