 |
VOOZH | about |
|
VOOZH | about |
TrueFoundry recognized in Gartner Hype Cycle for Platform Engineering 2026. Read the full report →
Join our VAR & VAD ecosystem — deliver enterprise AI governance across LLMs, MCPs & Agents. Become a Partner →
Get instant access to a live TrueFoundry environment. Deploy models, route LLM traffic, and explore the full platform — your sandbox is ready in seconds, no credit card required.
Blazingly fast way to build, track and deploy your models!
Rate limiting protects LLM infrastructure from runaway cost, abuse, and noisy-neighbor overload — but token-based traffic needs limits that count tokens and spend, not just requests.
Large Language Models (LLMs) offer powerful capabilities, but they also introduce high infrastructure costs, unpredictable usage patterns, and potential for misuse. As enterprises integrate LLMs into customer-facing tools, internal copilots, and API platforms, the need for controlled and reliable access becomes critical. This is where rate limiting plays a key role.
In the context of LLM inference, traditional request-per-second (RPS) rate limiting is not enough. LLMs are resource-intensive, token-based, and highly variable in computational load. A single prompt to a 70B parameter model can consume thousands of tokens and significantly impact GPU latency. Without proper controls, shared infrastructure can quickly become unstable or cost-prohibitive.
This article explains how rate limiting works in an AI Gateway, why it is essential for scalable AI infrastructure, and how TrueFoundry enables it by default to ensure fair usage, cost efficiency, and production-grade performance across multi-tenant deployments.
Rate limits that understand tokens, not just requests.
TrueFoundry's AI Gateway enforces token- and cost-aware rate limiting per user, team, or model — with full observability built in.
Book a 30-min DemoExplore AI Gateway
Rate limiting is a mechanism used to control how many requests a client can send to a system within a specific time window and it is a core capability of modern AI gateways managing LLM traffic. It ensures fairness, prevents overload, and maintains availability, especially in multi-user environments. Traditional APIs often apply simple limits like 100 requests per minute per user, which works well for standard REST services.
However, LLMs operate very differently. Each request can place a dramatically different load on the infrastructure based on the input size, model type, and expected output. For instance, a 20-token prompt to a 7B model might complete quickly, while a 2000-token request to a 65B model could block GPUs for several seconds. Even two identical requests to different models can vary by 5x or more in compute cost.
This makes request-based limits insufficient. Modern LLM gateways must adopt token-aware rate limiting, which accounts for the actual number of tokens processed and the compute burden per call.
Key factors considered in token-aware rate limiting include:
Compared to fixed request limits, token-aware limits:
In generative AI workflows, rate limiting becomes even more critical. A single user can trigger large-scale backend processing through long-form prompts, document ingestion, or multi-step agents. Without controls, this can lead to GPU congestion, high latency, or unexpected costs.
Real-world usage is often unpredictable, driven by front-end apps, test loops, or automation. Rate limiting ensures these interactions remain stable and efficient, even when infrastructure is shared across users or tenants.
For any production-grade deployment, the best LLM gateway must provide intelligent rate limiting as a foundational requirement for scalability, reliability, and cost control.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
Rate limiting is more than a backend safeguard. For platforms serving LLMs — especially those offering public or multi-tenant APIs — it acts as a strategic layer for stability, governance, and business alignment. Whether it's OpenAI, Anthropic, or platforms built with TrueFoundry, rate limits serve several critical purposes.
Protect Infrastructure from Abuse
Generative AI inference is resource-intensive. A sudden burst of long prompts or concurrent requests can overwhelm GPU queues, increase latency, or even bring services down. Rate limits ensure traffic is processed in a controlled and prioritized manner, preventing resource exhaustion.
Enforce Fairness Across Users or Tenants
In multi-user systems, one client’s usage should not degrade performance for others. Rate limits help enforce isolation across users, teams, or API keys. This guarantees consistent service levels regardless of how many users are active at once.
Align Usage with Pricing Plans
Many Gen AI platforms monetize based on tokens or usage tiers. Rate limits help enforce those boundaries. For example:
Prevent Cost Surprises and Overruns
LLM usage can scale quietly and quickly. Without proper limits, token consumption and GPU utilization can balloon. Rate limiting helps platforms prevent unexpected infrastructure costs and maintain budget control.
Improve Reliability and User Experience
When usage is controlled, system queues remain stable. This leads to lower latency, higher success rates, and a more consistent user experience, especially important in production environments with SLAs.
In LLM-based systems, not all requests have the same impact. A short prompt to a small model may use minimal resources, while a long query to a large model can consume significant GPU time. Because of this variability, modern platforms apply rate limits across multiple dimensions instead of relying only on request count.
Here are the most common dimensions used for effective rate limiting:
Using these dimensions gives platform teams the flexibility to align resource usage with infrastructure constraints, user needs, and service-level expectations.
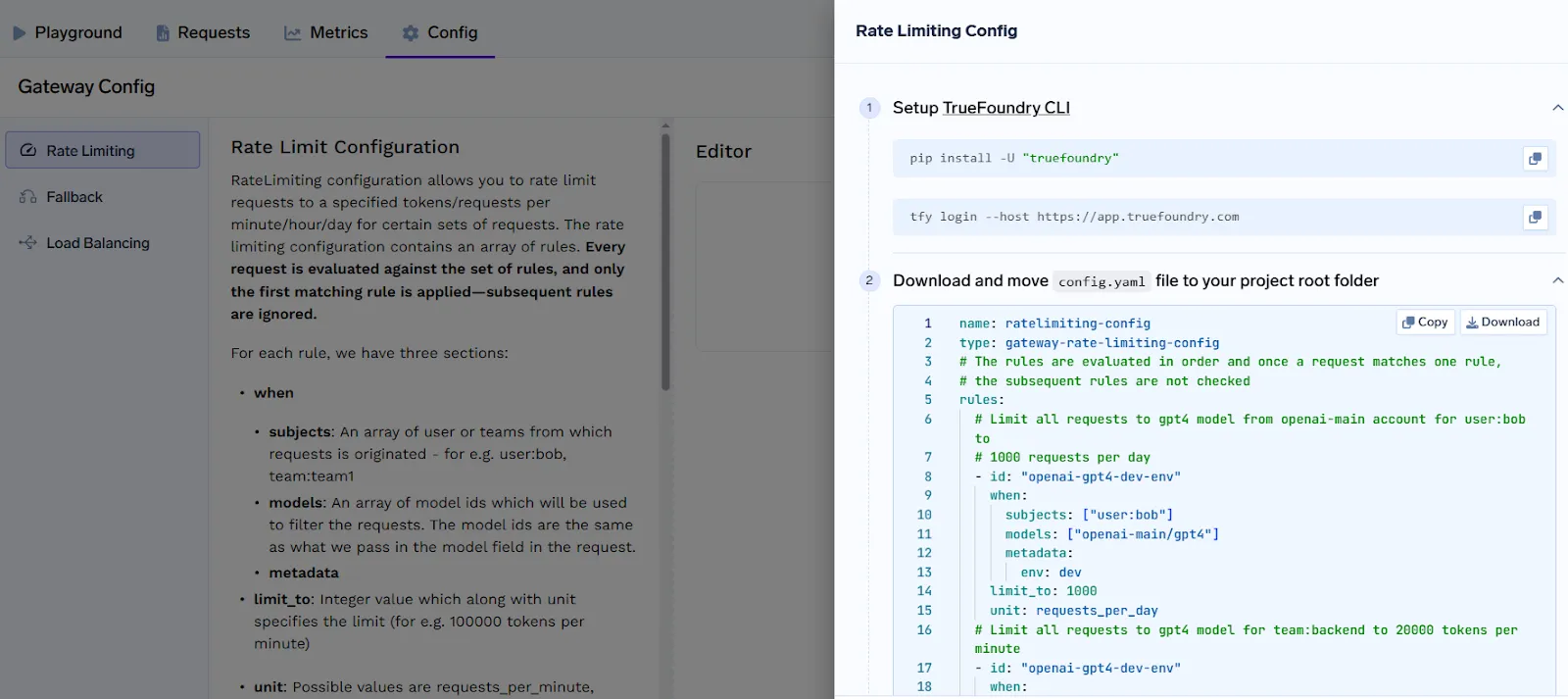
TrueFoundry provides a robust and flexible rate-limiting system that allows platform teams to control access to LLM endpoints based on requests or token usage. This ensures fair allocation of compute, prevents abuse, and aligns usage with organizational policies or billing plans.
At the core of TrueFoundry’s rate-limiting mechanism is a rule-based configuration system that allows teams to define precise policies across users, teams, virtual accounts, models, and request metadata.
Which rate-limiting strategy fits your workload?
Answer 3 quick questions to get a recommendation.
Rule-Based Configuration
Rate limiting in TrueFoundry is defined through a list of rules, each specifying:
Rules are evaluated in order, so more specific rules should be placed above broader ones to ensure correct matching.
Supported Limit Types
TrueFoundry supports both request-based and token-based limits across various time intervals:
This allows enforcement of policies that reflect actual compute usage, especially important when serving variable-length prompts to models of different sizes.
Common Use Cases
The flexibility of the configuration system supports a wide range of use cases:
Sample Configuration
name: ratelimiting-config
type: gateway-rate-limiting-config
rules:
- id: "specific-rule"
when:
subjects: ["user:bob@email.com"]
models: ["openai-main/gpt4"]
limit_to: 1000
unit: requests_per_day
This example limits a specific user’s GPT-4 usage to 1,000 requests per day. TrueFoundry’s rate-limiting system is designed to be both powerful and easy to manage. With token-aware controls, granular targeting, and clear YAML-based policies, teams can confidently scale LLM usage while maintaining control over infrastructure and cost.
How to Apply the Configuration
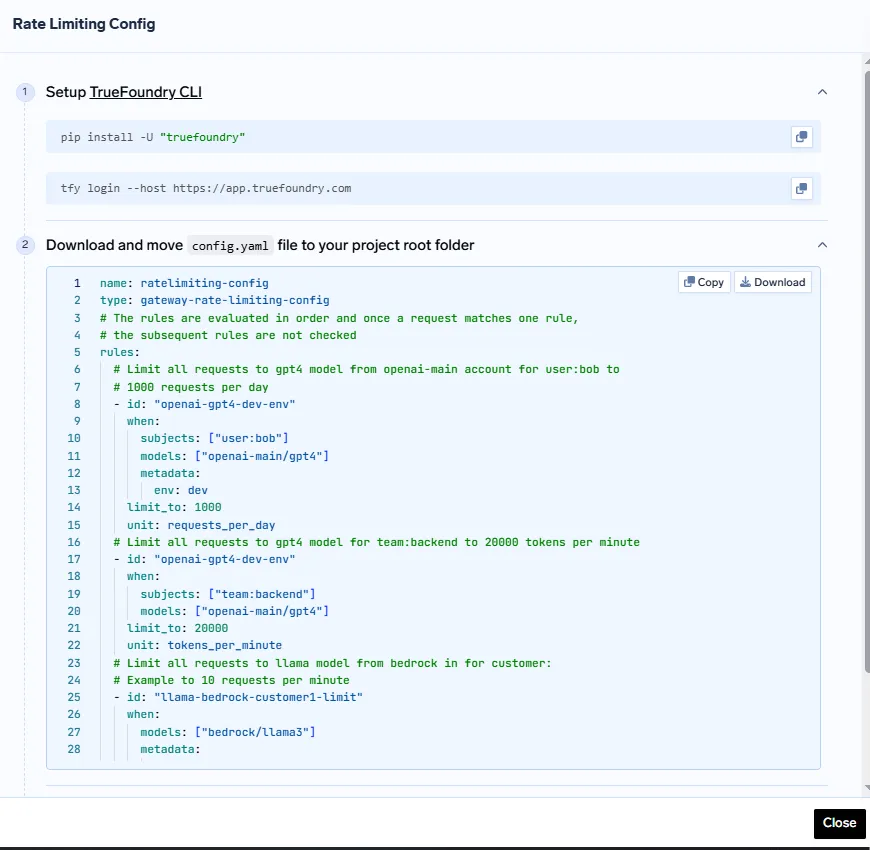
1. Install the TrueFoundry CLI:
pip install -U "truefoundry"
tfy login --host https://app.truefoundry.com
2. Place your config.yaml in your project directory.
3. Apply the configuration using:
tfy apply -f config.yaml
This declarative approach ensures rate limits are version-controlled, reproducible, and aligned with GitOps best practices.
Real-Time Feedback on Rate Limits
TrueFoundry’s rate-limiting system is designed to provide immediate, transparent feedback to clients when limits are breached or nearing exhaustion. This helps developers understand usage boundaries and handle throttling gracefully in their applications.
When a request exceeds the defined rate limit:
This feedback mechanism supports better client behavior, enables automated retry logic, and ensures that usage remains within quota boundaries without guesswork.
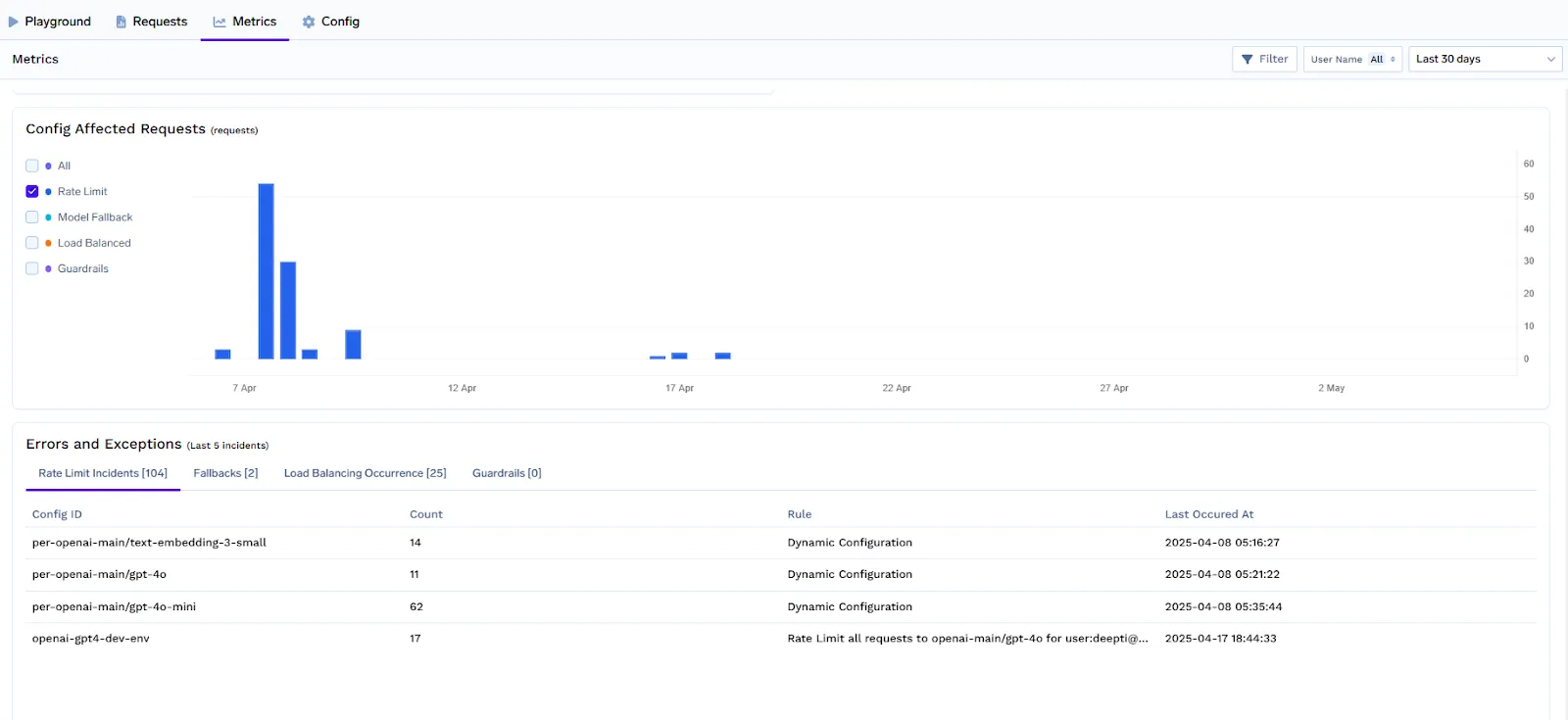
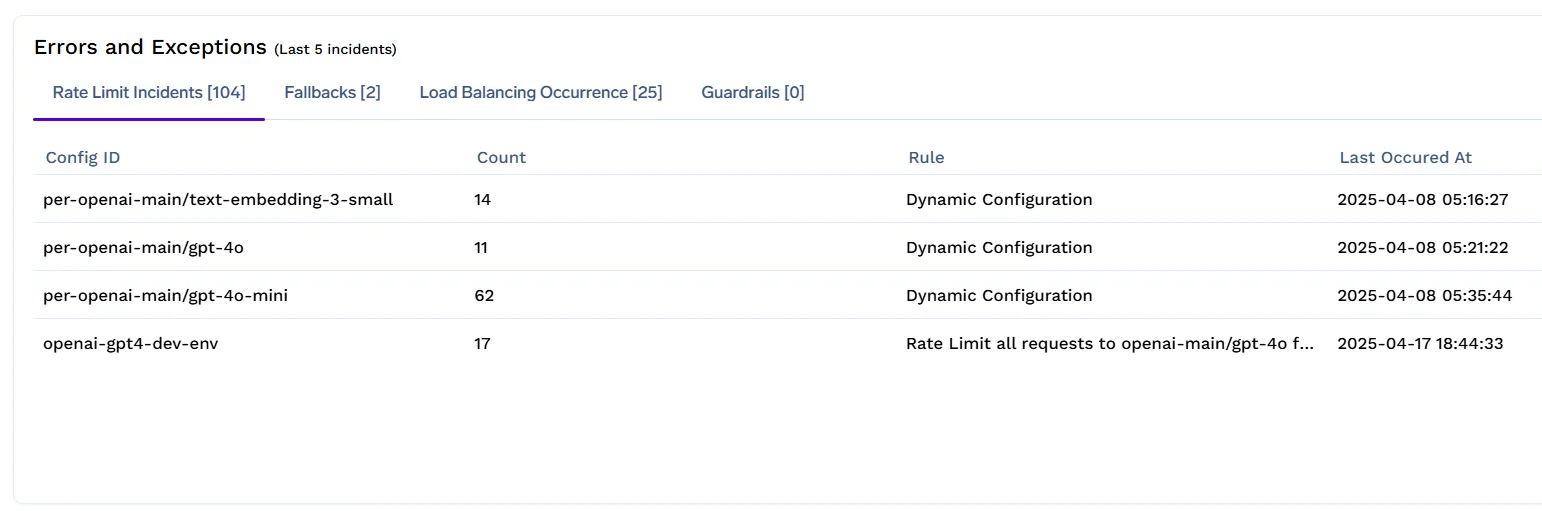
Dashboards & Alerts
TrueFoundry provides built-in observability to help platform teams monitor and optimize rate limit policies in real-time.
Using the LLM Gateway dashboard, you can track:
These insights help detect abuse, adjust limits proactively, and ensure high-value users receive consistent service.
When LLM APIs fail, whether due to rate limits, internal errors, or temporary outages, fallback mechanisms keep your applications running smoothly. Instead of returning errors to the end user, TrueFoundry can automatically route the request to a backup model or provider, maintaining availability with minimal disruption.
Fallback rules are triggered based on specific conditions such as the model ID, the requesting user or team, and response codes like 429 or 500. When a request meets these conditions, it is routed to one or more alternative models specified in the fallback configuration. These fallback targets can optionally include overrides to parameters like temperature or max tokens, allowing the behavior to be fine-tuned depending on the model provider. Only the first matching rule is applied during evaluation, which ensures predictable, deterministic handling of failures.
A typical fallback rule in TrueFoundry includes the following components:
Sample Fallback Config:
name: model-fallback-config
type: gateway-fallback-config
# The rules are evaluated in order. Once a request matches one rule, the subsequent rules are not checked.
rules:
# Fallback to gpt-4 on Azure or AWS if openai-main/gpt-4 fails with 500 or 503.
# The openai-main target also overrides some request parameters like temperature and max_tokens.
- id: "openai-gpt4-fallback"
when:
models: ["openai-main/gpt4"]
response_status_codes: [500, 503]
fallback_models:
- target: openai-main/gpt-4
override_params:
temperature: 0.9
max_tokens: 800
# Fallback to LLaMA3 on Azure or AWS if bedrock/llama3 fails with 500 or 429 for customer1.
- id: "llama-bedrock-customer1-fallback"
when:
models: ["bedrock/llama3"]
metadata:
customer-id: customer1
response_status_codes: [500, 429]
fallback_models:
- target: aws/llama3
- target: azure/llama3
TrueFoundry’s LLM Gateway natively supports declarative fallback setup as part of its configuration system. This allows teams to define fault-tolerant routing policies and preserve uptime without manual intervention, especially when working with multiple providers. Together, smart rate limiting and automated fallback create the foundation for high-availability Gen AI services.
In any multi-tenant AI platform, rate limiting is crucial for ensuring stability, fairness, and cost governance. It allows teams to define access boundaries not only for individual users but also across teams, virtual accounts, and specific models without the need for custom logic.
TrueFoundry’s Gateway supports declarative rate limiting via YAML configuration, where rules are evaluated in order. The first matching rule is applied, meaning more specific rules should be placed at the top, while more generic rules should be placed lower in the configuration. This structure ensures layered control while maintaining clean, readable configurations.
Each rule can include the following components:
Examples of Multi-Tenant Rate Limiting
Limit Specific User Request: Suppose you want to limit all requests to gpt4 model from the openai-main account for users bob@email.com and jack@email.com to 1000 requests per day:
- id: "user-gpt4-limit"
when:
subjects: ["user:bob@email.com", "user:jack@email.com"]
models: ["openai-main/gpt4"]
limit_to: 1000
unit: requests_per_day
Apply team-wide limits: If you want to restrict the total number of requests for the 'frontend' team to 5000 per day
- id: "team-frontend-limit"
when:
subjects: ["team:frontend"]
limit_to: 5000
unit: requests_per_day
Restrict virtual accounts: If you want to cap the number of requests for the virtual account 'va-james' at 1500 per day
- id: "va-james-limit"
when:
subjects: ["virtualaccount:va-james"]
limit_to: 1500
unit: requests_per_day
Set global caps across all users and models:
- id: "{user}-{model}-daily-limit"
when: {}
limit_to: 1000000
unit: tokens_per_day
This setup allows platform teams to segment usage across business units, enforce per-environment quotas, and protect expensive model endpoints while supporting scalable, reliable AI workloads.
Rate limiting is more than a backend control. It is a critical enabler for reliable, cost-efficient, and fair usage of LLM infrastructure at scale. Whether you are operating a multi-tenant platform, offering tiered access to customers, or running internal AI workloads across teams, implementing smart, token-aware rate limits ensures your system stays predictable under pressure.
Alongside rate limiting, features like fallback routing, real-time feedback, and granular configuration give engineering teams the tools to balance performance with control. TrueFoundry’s LLM Gateway brings these capabilities together with a declarative interface, allowing platform teams to define policies that are transparent, auditable, and aligned with organizational goals.
As generative AI adoption accelerates, systems that enforce intelligent access control without sacrificing user experience or uptime will define the next generation of infrastructure resilience. If you are building or scaling an AI gateway, rate limiting is not just something to consider. It is something to get right from day one.
Ready to enforce token- and cost-aware rate limits across every team and model?
Book a Demo →
Rate limiting in LLM gateway refers to the mechanism used to control the frequency of incoming requests or the volume of tokens a user, team, or application can process within a specific time window. Unlike traditional API throttling, it is token-aware and accounts for the actual compute burden of different model architectures, ensuring that resource-heavy queries do not crash the system.
Implementing rate limiting in LLM gateway environments helps control costs by preventing unexpected token consumption spikes and runaway scripts. By setting granular daily or hourly quotas, organizations can cap spending for specific users or non-production environments, ensuring that AI experiments remain within a predictable budget while protecting against expensive billing surprises.
Rate limiting in LLM gateway setups is essential to protect infrastructure from abuse and ensure high availability for all users. It prevents a single "noisy neighbor" from exhausting provider quotas or GPU capacity, which would otherwise lead to increased latency and frequent 429 "Too Many Requests" errors. This management layer is critical for maintaining stable SLAs in production.
Common strategies for rate limiting in LLM gateway include Request-Per-Minute (RPM) and Token-Per-Minute (TPM) limits, which provide a precise measure of resource usage. Advanced gateways also support tiered limits based on user roles or model types, allowing mission-critical tasks to receive higher priority while lower-priority development workloads are throttled during periods of congestion.
While it adds a tiny processing step, rate limiting in LLM gateway typically introduces less than 4 milliseconds of overhead, which is negligible compared to the seconds needed for model generation. In fact, it often improves perceived latency by preventing the backend queues from becoming saturated, ensuring that requests are processed smoothly without causing timeouts or service failures.
Yes, TrueFoundry provides a production-grade implementation of rate limiting in LLM gateway through a declarative, rule-based configuration. It allows teams to enforce token-aware limits across multiple model providers and tenants using simple YAML files. This system provides real-time feedback and detailed dashboards, enabling platform teams to scale AI workloads while maintaining strict cost and resource governance.
AI rate limiting works by tracking how frequently a user sends requests to an AI API. The system counts requests or tokens within a time window. If the user exceeds the allowed limit, the API temporarily blocks new requests or returns an error until the limit resets. This protects servers from overload.
Absolutely. By capping token usage and request rates, gateways prevent unexpected GPU overuse or cloud spend. Organizations can align usage with budgets, plan for tiered access, and reduce costly over-provisioning while maintaining consistent service for critical workloads.
Yes. Modern AI gateways like TrueFoundry allow teams to update rate-limit rules in real time or via automated scripts, ensuring infrastructure can handle unexpected surges without downtime or degraded performance. Dynamic adjustments keep service responsive while maintaining fair usage across tenants.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.
Product
Company
Resources
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
.webp){kind=link}
.webp){kind=link}
.webp){kind=link}
.webp){kind=link}
.webp){kind=link}
.webp){kind=link}
{kind=link}
.webp){kind=link}
{kind=link}
.webp){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}